Spark Streaming连接TCP Socket
1.Spark Streaming是什么
Spark Streaming是在Spark上建立的可扩展的高吞吐量实时处理流数据的框架,数据可以是来自多种不同的源,例如kafka,Flume,Twitter,ZeroMQ或者TCP Socket等。在这个框架下,支持对流数据的各种运算,比如map,reduce,join等。处理过后的数据可以存储到文件系统或数据库。
利用Spark Streaming,你可以使用与批量加载数据相同的API来创建数据管道,并通过数据管道处理流式数据。此外,Spark Steaming的“micro-batching”方式提供相当好的弹性来应对某些原因造成的任务失败。
2. Spark Streaming的基本原理
Spark Streaming对数据的处理方式主要采用的方法是对Stream数据进行时间切片,分成小的数据片段,通过类似批处理的方式处理数据片段。
Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。
Spark Streaming将流式计算分解成一系列短小的批处理作业。Spark Streaming的输入数据分成一段一段的数据(DStreaming),每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的操作变为针对Spark中对RDD的操作,将RDD经过操作变成中间结果保存在内存中。
3. DStream
上面提到了DStreaming,那么DStreaming到底是什么呢:
DStreaming相当于在Streaming的框架下对RDD进行封装,表示的是我们处理的一个实时数据流。类似于RDD,DStream提供了转换操作,窗口转换操作和输出操作三种操作方法。
4.Spark Streaming的优势
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
实时性:它能运行在100+的结点上,并达到秒级延迟。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark的任务集的调度过程。其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高的所有流式准实时计算场景。
高效和容错的特性:对于流式计算来说,容错性至关重要。在spark中每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作,只要输入数据是可容错的,那么任意一个RDD的分区出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。而spark Streaming使用基于内存的Spark作为执行引擎, 其容错性自然很好。
吞吐量:Spark Streaming能集成Spark的批处理和交互查询,其吞吐量比Storm至少高2~5倍。并且它为实现复杂的算法提供了和批处理类似的简单接口。
接下来用Spark Streaming连接TCP Socket来说明如何使用Spark Streaming:
1 创建StreamingContext对象
首先使用StreamingContext模块,这个模块的作用是提供所有的流数据处理的功能:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext sc = SparkContext("local[2]", "streamwordcount")
# 创建本地的SparkContext对象,包含2个执行线程 ssc = StreamingContext(sc, 2)
# 创建本地的StreamingContext对象,处理的时间片间隔时间,设置为2s
2 创建DStream对象
我们需要连接一个打开的 TCP 服务端口,从而获取流数据,这里使用的源是TCP Socket,所以使用socketTextStream()函数:
lines = ssc.socketTextStream("localhost", 8888)
# 创建DStream,指明数据源为socket:来自localhost本机的8888端口
3 对DStream进行操作
我们开始对lines进行处理,首先对当前2秒内获取的数据进行分割并执行标准的MapReduce流程计算。
words = lines.flatMap(lambda line: line.split(" "))
# 使用flatMap和Split对2秒内收到的字符串进行分割
得到的words是一系列的单词,再执行下面的操作:
pairs = words.map(lambda word: (word, 1))
# map操作将独立的单词映射到(word,1)元组 wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# reduceByKey操作对pairs执行reduce操作获得(单词,词频)元组
5 输出数据
将处理后的数据输出到一个文件中:
outputFile = "/home/feige/streaming/ss"
# 输出文件夹的前缀,Spark Streaming会自动使用当前时间戳来生成不同的文件夹名称 wordCounts.saveAsTextFiles(outputFile)
# 将结果输出
6 启动应用
要使程序在Spark Streaming上运行起来,需要执行Spark Streaming启动的流程,调用start()函数启动,awaitTermination()函数等待处理结束的信号。
ssc.start()
# 启动Spark Streaming应用
ssc.awaitTermination()
打开终端执行:
nc -lk 8888
nc的-l参数表示创建一个监听端口,等待新的连接。-k参数表示当前连接结束后仍然保持监听,必须与-l参数同时使用。
执行完上面的命令后不关闭终端,我们将在这个终端中输入一些处理的数据:

打开一个新的终端来执行我们的Spark Streaming应用:

这里是spark streaming执行的过程
现在我们来看看程序执行的效果,程序每隔2秒扫描一次监控窗口输入的内容,我们查看一下:
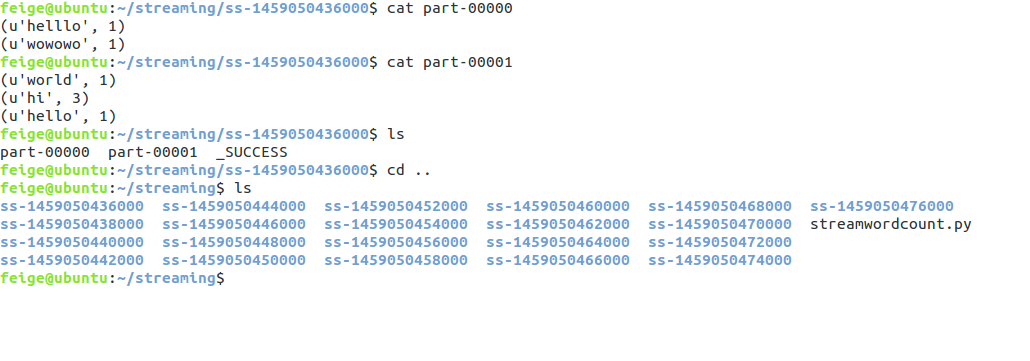
结束语:
最近压力比较大,琐事诸多,相信这段时间过后一切都会好起来的,加油!!!
Spark Streaming连接TCP Socket的更多相关文章
- 2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习 Overview 概述 Spark Streaming is an extension of the core Spark ...
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark Streaming 002 统计单词的例子
1.准备 事先在hdfs上创建两个目录: 保存上传数据的目录:hdfs://alamps:9000/library/SparkStreaming/data checkpoint的目录:hdfs://a ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- spark streaming的理解和应用
1.Spark Streaming简介 官方网站解释:http://spark.apache.org/docs/latest/streaming-programming-guide.html 该博客转 ...
- 实时流计算Spark Streaming原理介绍
1.Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的.具备容错机制的实时流数据的处理.支持从多种数据源获取数据,包 ...
- Spark Streaming之一:整体介绍
提到Spark Streaming,我们不得不说一下BDAS(Berkeley Data Analytics Stack),这个伯克利大学提出的关于数据分析的软件栈.从它的视角来看,目前的大数据处理可 ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
随机推荐
- JWPlayer 初探
http://www.360doc.com/content/13/0103/22/21412_258041878.shtml JWPlayer 是一款比较实用的web flash 播放器
- 使用netty构建一个socks proxy
使用netty构建一个socks proxy 最近在做的项目,需要自己搭建一个socks代理.netty4.0附带了一个socks代理的样例,但是3.x就没有这个东西了,碰巧使用的又是3.7,就只 ...
- CCNA实验(7) -- NAT
1.静态NAT2.动态NAT3.复用内部全局地址的NAT(PAT) enableconf tno ip do loenable pass ciscoline con 0logg syncexec-t ...
- 蓝桥杯之FBI树问题
问题描述 我们可以把由"0"和"1"组成的字符串分为三类:全"0"串称为B串,全"1"串称为I串,既含"0&q ...
- python wsgi
什么是wsgi? wsgi是一个web组件的接口防范,wsgi将web组件分为三类:web服务器,web中间件,web应用程序 wsgi基本处理模式为:wsgi Server -> wsgi m ...
- 本地yum源安装GCC
Linux环境下yum源安装GCC 前提条件是有Linux环境的安装盘ISO文件 在Linux系统中创建两个目录,一个是用来存放ISO文件,一个是用来挂载该ISO文件,如下: $mkdir /root ...
- Visual Studio的ASP.NET修改默认打开浏览器
1.新建web空应用程序,输入项目名称. 2.右击项目名称,添加“新建项”—一般处理程序 3.右击新建一个HTML文件,任意命名. 4.右击新建的Html文件,选择“浏览方式” 5.选择后弹出浏览器选 ...
- (转)ios跳转到通用页面
在代码中调用如下代码: [[UIApplicationsharedApplication] openURL:[NSURLURLWithString:@"prefs:root=LOCATION ...
- iOS 设置状态栏的颜色
1.在plist文件中设置如下属性: 2.在delegate中设置 [[UIApplication sharedApplication] setStatusBarStyle:UIStatusBarSt ...
- 浅谈JDBC(二)
JDBC中的事务 简单来说,事务就是要保证一组DAO方法的操作,要么一起成功要么一起失败. 1.事务控制的位置 在Service中的业务方法内进行事务控制. 2.事务控制的代码 a.注意:JDBC会自 ...