使用 OpenTelemetry 构建可观测性 05 - 传播和行李(Propagation & Baggage)
我们开发的应用程序可能具有不同的形态和架构:有些是单体应用,有些是微服务。为单体应用程序添加遥测数据相对来说简单,因为所有数据都在同一进程中。然而对于微服务应用程序,情况可能会更具挑战性。
通常,分布式微服务应用程序的不同服务之间仅通过网络连接。然而,当我们想要创建有效的链路追踪数据,就要考虑到下面的问题:
即使是微服务应用程序,我们也希望观察到从开始到结束的用户路径,这意味着跨越多个服务的边界。这就是我们所说的分布式链路追踪。不过我们如何实现这一点呢?我们如何使链路追踪信息贯穿可能是分布在多个进程,并且是不同的基础架构上呢?
传播( propagation )
在 OpenTelemetry 中,解决这个挑战的方案是通过传播来实现。这意味着以某种方式将链路追踪 ID(和父跨度 ID)传递给被调用服务,以便它们可以将该信息添加到分布式链路追踪路径中的一个跨度上。下面是一个示意图:
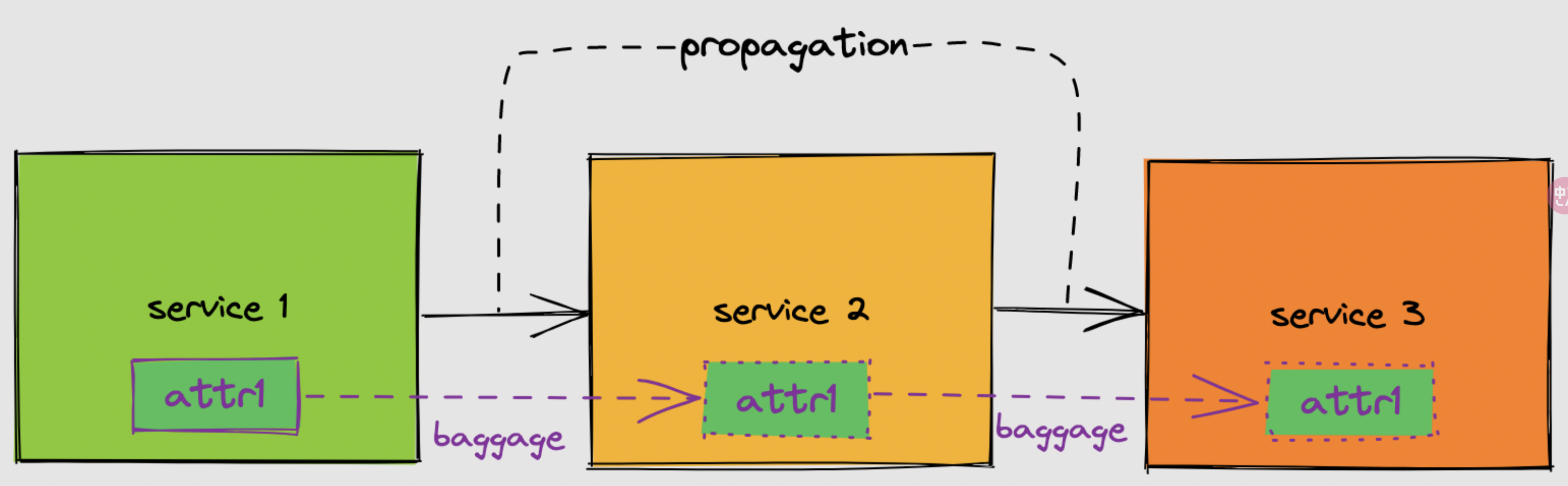
这里我们有三个服务,通过使用传播,我们能够将跟踪 ID 和父跨度 ID 作为头信息传递。在 Go 中,传播可以通过全局设置来处理:
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/propagation"
)
// ...
otel.SetTextMapPropagator(
propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{},
propagation.Baggage{}),
)在示例代码中,我们可以在控制器层(Handler,通常用于处理HTTP请求并生成相应的响应,承担的作用包括路由和请求分发,请求处理逻辑,响应生成)进行设置:
http.Handle(
fmt.Sprintf("/%s/", rootPath),
otelhttp.NewHandler(
http.HandlerFunc(userCart),
"http_user_cart",
otelhttp.WithTracerProvider(otel.GetTracerProvider()),
otelhttp.WithPropagators(otel.GetTextMapPropagator()),
))当从一个服务发送 HTTP 请求到另一个服务时,可通过 otelhttp 库的辅助函数来创建和管理分布式追踪的跨度对象:
import "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
// ...
resp, err := otelhttp.Get(ctx, fmt.Sprintf("%s/%s", userServiceEndpoint, userName))行李(Baggage)
从上图中可以看出 service 1 生成了一些数据 attr1 。这些与 service 1 相关的数据可能要添加到 service 2 或 service 3 所在跨度对象的属性中。由于这些服务可能无法直接访问此数据,在 OpenTelemetry 中是通过行李来解决这个问题。行李本质上是携带额外信息的键值对,通过请求传递数据给不同服务和组件。
在 Go 中,我们可以通过以下方式添加行李信息:
reqAddrBaggage, err := baggage.NewMember("req.addr", r.RemoteAddr)
if err != nil {
// Handle error...
}
reqBaggage, err := baggage.New(reqAddrBaggage)
if err != nil {
// Handle error...
}
ctx = baggage.ContextWithBaggage(ctx, reqBaggage)这样设置后我们的 HTTP 请求将包括 req.addr 行李 。
后续消费端的服务(在图中,这可能是 service 2 或 service 3 ),就可以从请求上下文中解析行李:
import "go.opentelemetry.io/otel/baggage"
// ...
reqBaggage := baggage.FromContext(ctx)
span.SetAttributes(attribute.String(
"req.addr",
reqBaggage.Member("req.addr").Value()),
)此代码解析行李信息,并将其作为当前跨度的属性添加进去。
示例
经过之前对传播和行李的讨论,现在让我们看看 OpenTelemetry 如何发送这些数据。在示例的购物车应用程序中,如果我发出请求并从价格服务或用户服务中查看请求头,将会看到以下两行信息:
Baggage: req.addr=10.244.0.11%3A60086
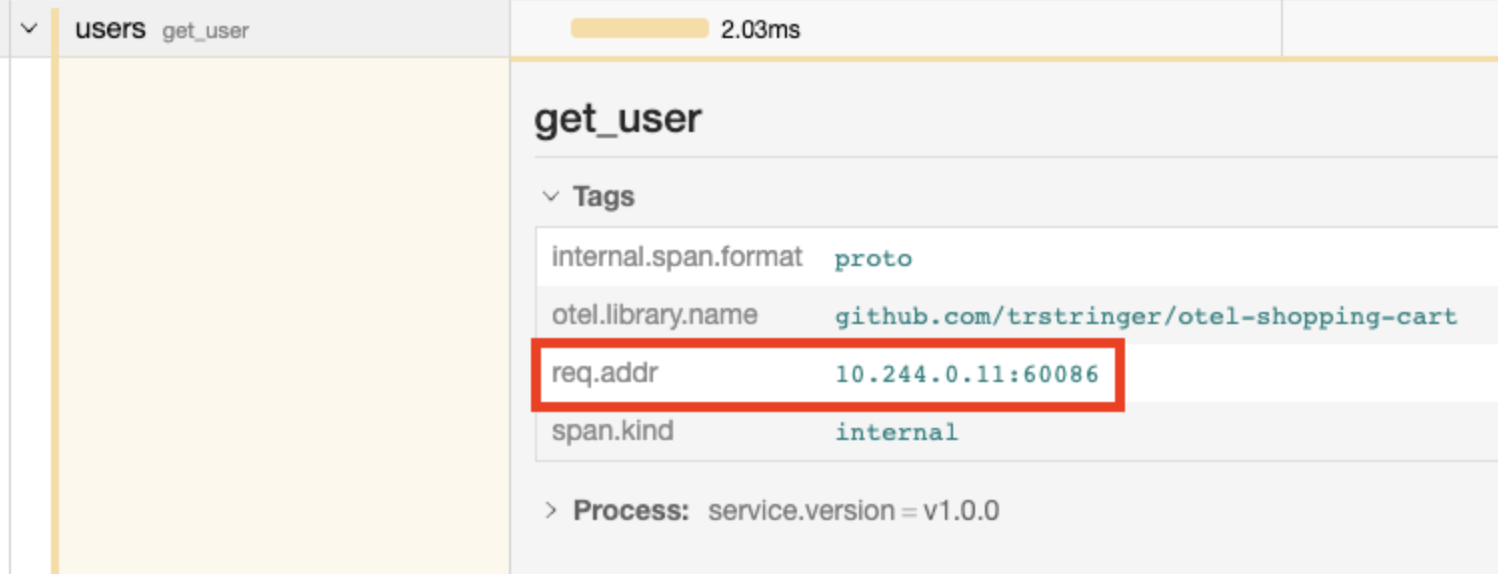
Traceparent: 00-9861e8c7b097206fed82e0f6b379aae0-4aa019606aed70b6-01请求头 Traceparent 是链路追踪 ID(本例中是“9861e8c7b097206fed82e0f6b379aae0”)和父跨度 ID (“4aa019606aed70b6”)。还有一个 Baggage ,其中包括在请求发起的源服务(购物车服务),它被添加到 req.addr 行李中。下图可以看到 req.addr 行李在用户服务中被引用:
总结
在 OpenTelemetry 中通过使用传播和行李,很好的解决了“分布式链路追踪”中“分布式”的问题。这样可以帮助您获取更有价值的链路追踪数据!
本文翻译自:https://trstringer.com/otel-part5-propagation/
扩展阅读:
使用 OpenTelemetry 构建可观测性 05 - 传播和行李(Propagation & Baggage)的更多相关文章
- 前向传播算法(Forward propagation)与反向传播算法(Back propagation)
虽然学深度学习有一段时间了,但是对于一些算法的具体实现还是模糊不清,用了很久也不是很了解.因此特意先对深度学习中的相关基础概念做一下总结.先看看前向传播算法(Forward propagation)与 ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 反向传播(Back Propagation)
反向传播(Back Propagation) 通常在设计好一个神经网络后,参数的数量可能会达到百万级别.而我们利用梯度下降去跟新参数的过程如(1).但是在计算百万级别的参数时,需要一种有效计算梯度的方 ...
- 深度学习基础-基于Numpy的多层前馈神经网络(FFN)的构建和反向传播训练
本文是深度学习入门: 基于Python的实现.神经网络与深度学习(NNDL)以及花书的读书笔记.本文将以多分类任务为例,介绍多层的前馈神经网络(Feed Forward Networks,FFN)加上 ...
- Maven项目构建利器05——Maven的生命周期
Maven各个构建环节执行的顺序: 不能打乱顺序, 必须按照既定的正确顺序(编译,测试.打包.部署)来执行Maven的核心程序中定义了抽象的生命周期, 生命周期中各个阶段的具体任务是由插件来完成的,可 ...
- 再谈反向传播(Back Propagation)
此前写过一篇<BP算法基本原理推导----<机器学习>笔记>,但是感觉满纸公式,而且没有讲到BP算法的精妙之处,所以找了一些资料,加上自己的理解,再来谈一下BP.如有什么疏漏或 ...
- numpy 构建深度神经网络来识别图片中是否有猫
目录 1 构建数据 2 随机初始化数据 3 前向传播 4 计算损失 5 反向传播 6 更新参数 7 构建模型 8 预测 9 开始训练 10 进行预测 11 以图片的形式展示预测后的结果 搭建简单神经网 ...
- Opentelemetry SDK的简单用法
Opentelemetry SDK的简单用法 概述 Opentelemetry trace的简单架构图如下,客户端和服务端都需要启动一个traceProvider,主要用于将trace数据传输到reg ...
- BP(back propagation)反向传播
转自:http://www.zhihu.com/question/27239198/answer/89853077 机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定 ...
- cs231n(三) 误差反向传播
摘要 本节将对反向传播进行直观的理解.反向传播是利用链式法则递归计算表达式的梯度的方法.理解反向传播过程及其精妙之处,对于理解.实现.设计和调试神经网络非常关键.反向求导的核心问题是:给定函数 $f( ...
随机推荐
- InnoDB之UNDO LOG介绍
简介: undo log是InnoDB事务特性的重要组成部分.当对记录做增删改操作就会产生undo记录,undo记录会记录到单独的表空间中. 本文将从代码层面对undo log进行一个简单的介绍:主要 ...
- 数据湖揭秘—Delta Lake
简介:Delta Lake 是 DataBricks 公司开源的.用于构建湖仓架构的存储框架.能够支持 Spark,Flink,Hive,PrestoDB,Trino 等查询/计算引擎.作为一个开放 ...
- 阿里 & 蚂蚁自研 IDE 研发框架 OpenSumi 正式开源
简介:经历近 3 年时间,在阿里集团及蚂蚁集团共建小组的努力下,OpenSumi 作为国内首个强定制性.高性能,兼容 VS Code 插件体系的 IDE 研发框架,今天正式对外开源. 作者 | ...
- Flink 和 Pulsar 的批流融合
简介: 如何通过 Apache Pulsar 原生的存储计算分离的架构提供批流融合的基础,以及 Apache Pulsar 如何与 Flink 结合,实现批流一体的计算. 简介:StreamNativ ...
- [GPT] AI大模型背景下,小模型还有优势吗?
在AI大模型背景下,小的模型仍然具有一些优势. 以下是一些可能的优势: 速度和效率:相比于大模型,小模型需要更少的计算资源和时间,能够更快地完成训练和预测,并且能够在较低的硬件配置上运行. 灵活性 ...
- ARM 反汇编速成
1.跳转指令 B 无条件跳转 BL 带链接的无条件跳转 BX 带状态切换的无条件跳转 BLX 带链接和状态切换的无条件跳转 B loc_地址 BNE, BEQ 2.存储器与寄存器交互数据指令 ...
- WPF 设置 IncludePackageReferencesDuringMarkupCompilation 属性导致分析器不工作
本文记录在 WPF 项目里面设置 IncludePackageReferencesDuringMarkupCompilation 属性为 False 导致了项目所安装的分析器不能符合预期工作 设置 I ...
- 读书笔记 为什么要有R5G6B5颜色格式
在 Windows 下,颜色的格式有很多,我好奇为什么要设计出 R5G6B5 这样的格式?通过阅读一些书和官方的文档,似乎了解了为什么,我在本文记录一下 颜色的格式上,常用的就是 16 位和 32 位 ...
- 01、Java 安全-反序列化基础
Java 反序列化基础 1.ObjectOutputStream 与 ObjectInputStream类 1.1.ObjectOutputStream类 java.io.ObjectOutputSt ...
- ECMAScript 语言规范每年都会进行一次更新,而备受期待的 ECMAScript 2024 将于 2024 年 6 月正式亮相。目前,ECMAScript 2024 的候选版本已经发布,为我们带来了一系列实用的新功能。
Promise.withResolvers 使用 Promise.withResolvers() 关键的区别在于解决和拒绝函数现在与 Promise 本身处于同一作用域,而不是在执行器中被创建和一次性 ...