算法学习笔记【6】| KMP 算法
KMP(Knuth-Morris-Pratt字符串查找算法)
KMP 算法是可以快速在文本串 s 中找到模式串 a 的算法。
Part 1:幼稚的算法
首先思考我们在暴力匹配模式串时的思路:
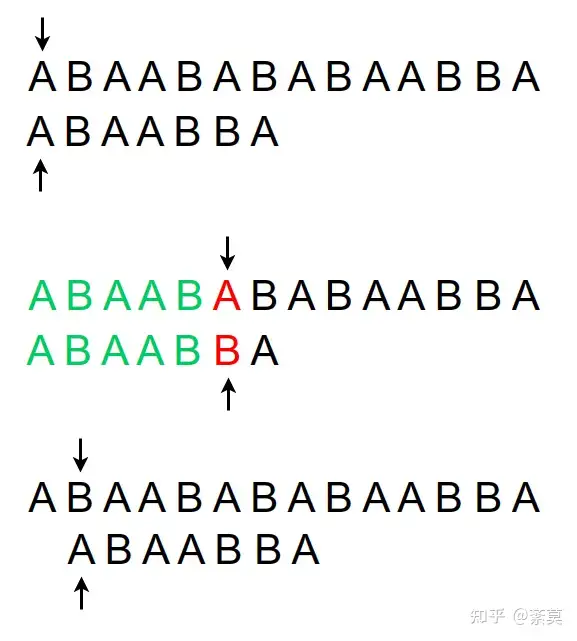
一旦有一位失配,就需要整个回溯,导致时间复杂度超标。
而 KMP 算法主要就是优化了这个回溯的问题。
一个人有多强不在于他能在顺境时走得多远,而在于他在逆境时能多久找回曾经的自己。
KMP 算法
首先我们要考虑让某个点不回溯,再优化另一个点的回溯过程。
KMP 给出了这样的一种方式:
设 i 表示文本串的位置,j 表示模式串的位置,我们让 i 不动,j 回溯到最合适的位置,这个位置,我们记为PMT(Partial Match Table,部分匹配表)。
PMT 数组的含义,也可以这样表示:
1 到 j 子串的最长公共前后缀长度。
就像这样:
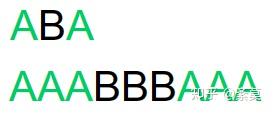
当然,最长前后缀是可以重叠的:

那就有个问题,难道最长的不是整个串吗?所以为了避免卡 bug,PMT 要求这个公共前后缀的长度要小于子串长度。
我们在考虑一开始那个发生失配的情况,用 KMP 算法就可以变成这样:
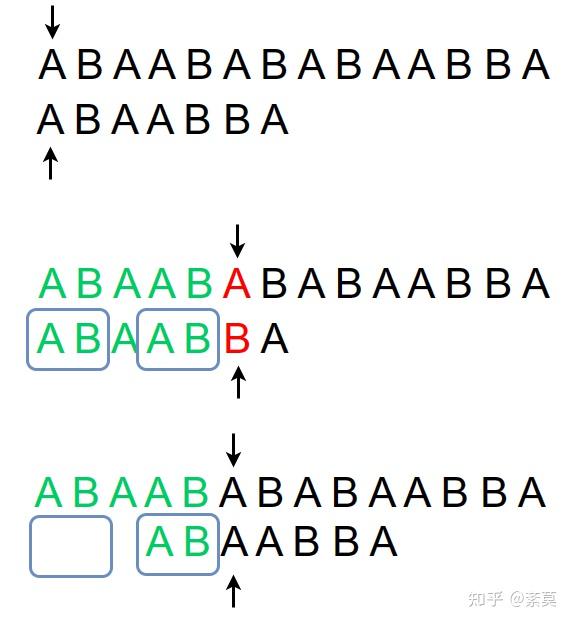
实际上我们没有移动 i,只是让 j 变成了 pmt[j-1]。
如果这一位继续失配,那么 j 又变成了 pmt[j-1]。
反复如此,直到不得不移动 i 为止。
那么代码可以写成这样:
for(int i=0,j=0;i<s.size();i++){
while(j && s[i] != a[j])
j = pmt[j-1];
if(s[i] == a[j]) j++;
if(j == a.size())
j = pmt[j-1];
}
对于每一位首先处理失配的情况,然后判断是否能匹配当前位置,特别的是当 j 匹配完后(匹配成功),就需要准备下一次匹配,也可以理解为 j 的下一位(空)和 i 的下一位失配了。
不过我们上面的代码是假设 pmt 数组已经求出,别忘了求出 pmt 本身也不简单。
一个精妙的方法是进行模式串的自匹配。首先将模式串错开一位,然后和自己匹配一次,这样每次匹配的最大长度就刚好是公共前后缀的长度!
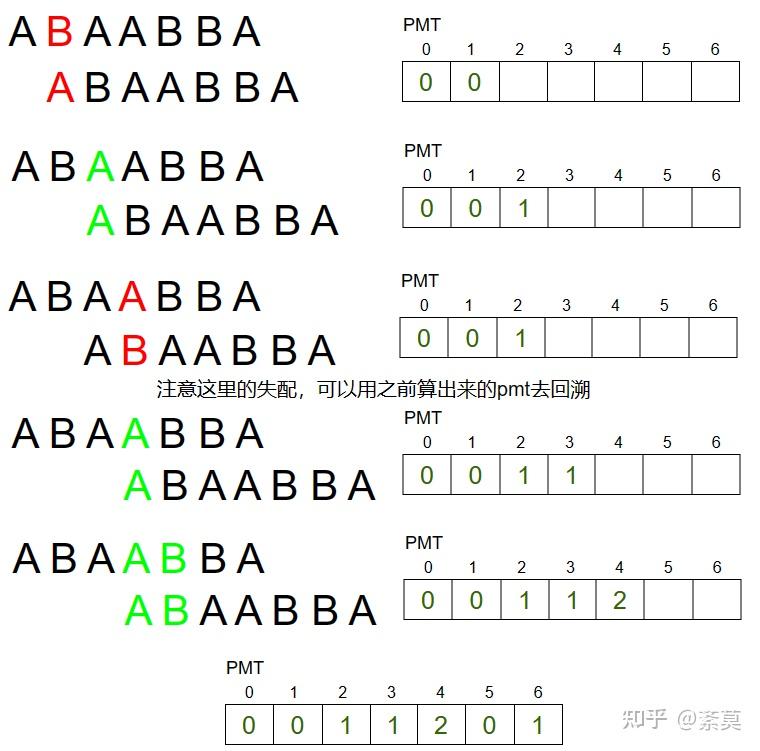
代码如下:
#include <bits/stdc++.h>
using namespace std;
int main(){
string a;
cin>>a;
int pmt[114]={0};
for(int i=1,j=0;i<a.size();i++){
while(j && a[i] != a[j])
j = pmt[j-1];
if(a[i] == a[j]) j++;
pmt[i] = j;
}
for(int i=0;i<a.size();i++){
cout<<pmt[i]<<' ';
}
return 0;
}
例题和代码
border 其实就是 pmt 数组。
const int N=1000005;
int pmt[N];
int main(){
ios_base::sync_with_stdio(false);cin.tie(0);cout.tie(0);
string s,a;
cin>>s>>a;
for(int i=1,j=0;i<a.size();i++){
while(j && a[i] != a[j])
j = pmt[j-1];
if(a[i] == a[j]) j++;
pmt[i] = j;
}
for(int i=0,j=0;i<s.size();i++){
while(j && s[i] != a[j])
j = pmt[j-1];
if(s[i] == a[j]) j++;
if(j == a.size()){
cout<<i+1-(a.size()-1)<<endl;
j = pmt[j-1];
}
}
for(int i=0;i<a.size();i++){
cout<<pmt[i]<<' ';
}
return 0;
}
算法学习笔记【6】| KMP 算法的更多相关文章
- 【算法学习笔记】Meissel-Lehmer 算法 (亚线性时间找出素数个数)
「Meissel-Lehmer 算法」是一种能在亚线性时间复杂度内求出 \(1\sim n\) 内质数个数的一种算法. 在看素数相关论文时发现了这个算法,论文链接:Here. 算法的细节来自 OI w ...
- 算法学习笔记:Kosaraju算法
Kosaraju算法一看这个名字很奇怪就可以猜到它也是一个根据人名起的算法,它的发明人是S. Rao Kosaraju,这是一个在图论当中非常著名的算法,可以用来拆分有向图当中的强连通分量. 背景知识 ...
- 算法学习笔记:Tarjan算法
在上一篇文章当中我们分享了强连通分量分解的一个经典算法Kosaraju算法,它的核心原理是通过将图翻转,以及两次递归来实现.今天介绍的算法名叫Tarjan,同样是一个很奇怪的名字,奇怪就对了,这也是以 ...
- Miller-Rabin 与 Pollard-Rho 算法学习笔记
前言 Miller-Rabin 算法用于判断一个数 \(p\) 是否是质数,若选定 \(w\) 个数进行判断,那么正确率约是 \(1-\frac{1}{4^w}\) ,时间复杂度为 \(O(\log ...
- 算法笔记之KMP算法
本文是<算法笔记>KMP算法章节的阅读笔记,文中主要内容来源于<算法笔记>.本文主要介绍了next数组.KMP算法及其应用以及对KMP算法的优化. KMP算法主要用于解决字符串 ...
- 算法学习笔记(20): AC自动机
AC自动机 前置知识: 字典树:可以参考我的另一篇文章 算法学习笔记(15): Trie(字典树) KMP:可以参考 KMP - Ricky2007,但是不理解KMP算法并不会对这个算法的理解产生影响 ...
- C / C++算法学习笔记(8)-SHELL排序
原始地址:C / C++算法学习笔记(8)-SHELL排序 基本思想 先取一个小于n的整数d1作为第一个增量(gap),把文件的全部记录分成d1个组.所有距离为dl的倍数的记录放在同一个组中.先在各组 ...
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- Manacher算法学习笔记 | LeetCode#5
Manacher算法学习笔记 DECLARATION 引用来源:https://www.cnblogs.com/grandyang/p/4475985.html CONTENT 用途:寻找一个字符串的 ...
- Johnson算法学习笔记
\(Johnson\)算法学习笔记. 在最短路的学习中,我们曾学习了三种最短路的算法,\(Bellman-Ford\)算法及其队列优化\(SPFA\)算法,\(Dijkstra\)算法.这些算法可以快 ...
随机推荐
- Swift高级进阶-Swift编译过程,”SIL代码“,“IR语法”
swift编译过程 如果不懂LLVM,Clang的同学可以去了解下它的知识点 一些文章中有详细介绍 OC 的编译过程 ,本文来探索一下 Swift 的编译过程.Swift 的编译过程中使用 Swif ...
- Geospatial Data 在 Nebula Graph 中的实践
本文首发于 Nebula Graph Community 公众号 本文主要介绍了地理空间数据(Geospatial Data)以及它在 Nebula Graph 中的具体实践. Geospatial ...
- Codeforces Round 729 (Div. 2)B. Plus and Multiply(构造、数学)
题面 链接 B. Plus and Multiply 题意 给定\(n,a,b\) 可以进行的操作 \(*a\) \(+b\) 最开始的数是1 问能否经过上面的两种操作将1变为n 题解 这题的关键是能 ...
- 软件架构(四)单体架构(Monolithic Architecture)
系列目录 软件架构(一)概览 软件架构(二)编程语言的历史 软件架构(三)名词解释:架构.设计.风格.模式 软件架构(四)单体架构(Monolithic Architecture) 软件架构(五)分层 ...
- tp5.1 controller 名称自动转换大小写,导致文件名对不上 url_convert
// 是否自动转换URL中的控制器和操作名 'url_convert' => false, // true,
- etcd每个节点都存储了完整的键值对数据集,为什么扩容etcd集群仍可分散存储压力?
etcd每个节点都存储了完整的键值对数据集,这主要是为了确保数据的一致性和高可用性.在这种设计下,任何一个节点都可以处理读取请求,并在本地提供数据,从而无需跨节点通信.这种冗余的数据存储方式也增加了系 ...
- day02-SpringMVC映射请求数据
SpringMVC映射请求数据 1.获取参数值 在开发中,如何获取到 http://xxx/url?参数名1=参数值1&参数名2=参数值2 中的参数? 之前的案例中我们知道:提交的url的参数 ...
- cpprestsdk有bug.
好不容易将cpprestsdk移植到MinGW,并编译通过,出于安全还是先将samples还有tests测试一下是否正常. 用samples/blackjack一测试就出现奇葩现象,server一端会 ...
- FFmpeg命令行之ffmpeg
一.简述 ffmpeg是一个非常强大的工具,它可以转换任何格式的媒体文件,并且还可以用自己的AudioFilter以及VideoFilter进行处理和编辑.有了它,我们就可以对媒体文件做很多我们想做的 ...
- Spring Boot自动运行之 CommandLineRunner、ApplicationRunner和@PostConstruct
在使用Spring Boot开发的工作中,我们经常会需要遇到一种功能需求,比如在服务启动时候,去加载一些配置,去请求一下其他服务的接口.Spring Boot给我们提供了三种常用的实现方法: 第一种是 ...