OWOD:开放世界目标检测,更贴近现实的检测场景 | CVPR 2021 Oral
不同于以往在固定数据集上测试性能,论文提出了一个更符合实际的全新检测场景Open World Object Detection,需要同时识别出未知类别和已知类别,并不断地进行增量学习。论文还给出了ORE解决方案,通过对比聚类和基于能量的分类器来进行开放开放世界的检测训练
来源:晓飞的算法工程笔记 公众号
论文: Towards Open World Object Detection

Introduction
常见的目标检测算法都针对特定的数据集进行训练,学习固定数量的类别,用于特定的场景。而论文则讨论一个更现实的场景,开放世界目标检测(Open World Object Detection)。在这个场景中,算法需要解决非目标误识别问题以及具备增量学习的能力。

将检测模型应用到开放世界中,除了识别指定类别的目标,还要将非目标类别区别为Unknow,称为Open Set Learning,这需要很强的泛化能力。而Open World Object Detection场景的要求会比Open Set Learning更进一步,当Unknow样本足够时,可随时将Unknow样本打上标签加入到目标类别中,即增量学习。这样的场景设定更为现实,更有助于算法落地,比如机器人、自动驾驶以及监控等需要在运行中不断进行优化的应用。
论文的主要贡献如下:
- 定义了Open World Object Detection问题,更贴近现实生活。
- 提出ORE算法,基于对比聚类(contrastive clustering)、可框出未知类别的检测网络(unknown-aware proposal network)、能量分类器(energy based unknown identification)来解决Open World Object Detection上的问题。
- 设计了完备的实验,用于衡量算法在Open World Object Detection上的性能。
- 作为论文的副产品,ORE在增量学习任务上达到了SOTA,而且还有很大的提升空间。
Open World Object Detection
首先定义Open World Object Detection的环境,在\(t\)时刻,已知的目标类别为\(\mathcal{K}^t=\{1,2,\cdots,C\} \subset{\mathbb{N}^{+}}\),其中\(\mathbb{N}^{+}\)为所有正整数,未知的类别为\(\mathcal{U}=\{C+1,\cdots\}\)。\(\mathcal{K}\)的训练集为\(\mathcal{D}^t=\{X^t,Y^t\}\),\(X=\{I_1,\cdots,I_M\}\)和\(Y=\{Y_1,\cdots,Y_M\}\)分别为图片和标注信息,其中每张图片的\(Y_i=\{y_1,y_2,\cdots,y_K\}\)包含了多个目标实例,每个实例都有其标签和位置信息。
在Open World Object Detection的设定中,模型\(M_C\)用于检测所有的\(C\)个已知类别,同时可以将为未知的目标标记为未知(0),未知的实例集合\(U_t\)经过专人筛选后得出\(n\)个样本足够的新类别,然后通过增量学习地获取模型\(M_{C+n}\),已知类别更新为\(\mathcal{K}_{t+1}=\mathcal{K}_t+\{C+1,\cdots,C+n\}\)。不停地循环执行上述的步骤,模型就可以不停地迭代其类别。
ORE: Open World Object Detector
Open World Object Detection的关键在于能够无监督地识别未知类别,以及加入新类别时不会遗忘先前的类别。为了解决上述问题,论文提出了ORE解决方案。
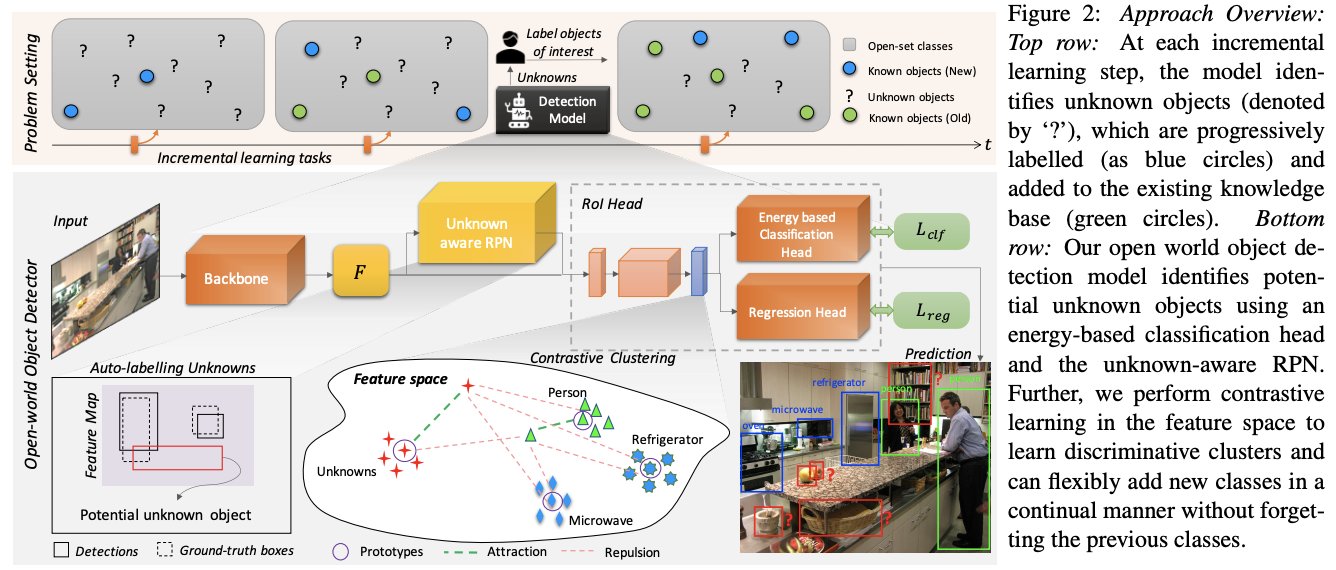
图2为ORE的高层抽象,以两阶段检测器Faster R-CNN作为基础检测器。在第一阶段,检测器可通过类不可知的RPN给出可能存在物体的所有区域,而在第二阶段,将上述的每个区域进行分类和位置调整。为了更好的适应Open World Object Detection,ORE对RPN和分类器都进行了相应的改进,适应自动打标签和识别未知类的需求。
Contrastive Clustering
将Open World中区分未知类问题转化为对比聚类问题是个不错的选择,在特征空间上进行类别分割,同类别的实例会尽量的靠近,而不相似的类别则会尽量的远离。对于每个已知类\(i \in \mathcal{K}^t\),维护一个原型向量\(p_i\),假设\(f_c\in \mathbb{R}^d\)为类别\(c\)的中间层特征,对应图2的ROI Head中的蓝色2048维特征,定义对比损失为:
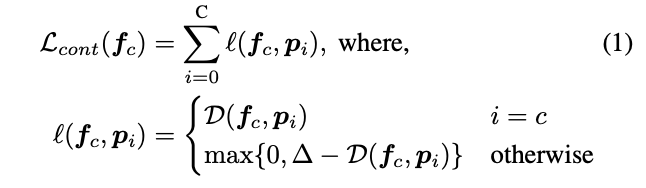
\(\mathcal{D}\)为距离函数,\(\Delta\)为相似阈值,不同类别实例间的距离要大于该阈值。在训练时,通过最小化对比损失来保证特征空间上的类别分割。需要注意的是,对比聚类的关键步骤是维护各类别的原型向量集合\(\mathcal{P}=\{p_0,\cdots,p_C\}\),一般取该类别的特征向量的均值。但由于整个网络是端到端训练的,特征向量也在不断地变化,原型向量也会跟着不断变化。为了适应这个特性,ORE为每个类维护了一个固定大小的特征队列\(\mathcal{F}_{store}=\{q_0,\cdots,q_C\}\),用来存储最新的特征向量。

对比损失的计算过程如算法1所示,为了保证原型向量有相对的准确性,仅当超过一定迭代次数\(I_b\)之后才开始计算损失值,之后每\(I_b*n\)次迭代就以动量的形式更新一次原型向量。这样可以避免原型向量变化过大的问题,得到的损失值添加到检测损失值中进行端到端的学习。
Auto-labelling Unknowns with RPN
在对比聚类中,未知类别也有其对应的原型向量\(p_0\),按正常的流程,需要对图片中的所有未知类别进行标注,以便归类特征,显然这是不现实的。所以论文采用RPN的预测框输出作为一个未知目标标注的折衷选择,将预测框中objectness分数高且与GT无重叠的top-K部分直接归类为未知目标,将其特征加入到未知列表的特征队列\(q_0\)中。
Energy Based Unknown Identifier
由于Opern World Detection场景包含未知类别的特性,传统的softmax分类器可能会给出不可控的结果,所以论文采用了基于能量的分类器(EBM),能够学习输入特征与标签之间的匹配程度,用来识别未知目标。给定特征\(f \in F\)与标签\(l\in L\),学习一个能量函数\(E(F,L)\),能够通过\(E(f):\mathbb{R}^d\to\mathbb{R}\)得到一个能用于描述特征与标签之间的匹配程度的标量(即能量)。这里,论文采用了Helmholtz free energy公式计算所有标签的结果之和:
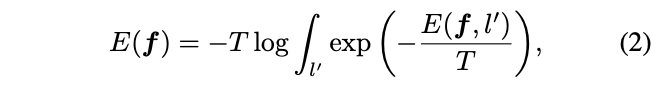
\(T\)是温度参数。通过Gibbs分布,可以将各标签的能量转化成类似softmax那样的效果:
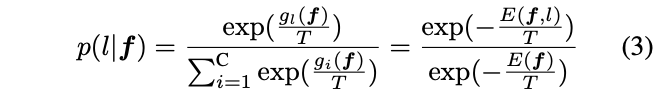
\(p(l|f)\)为标签\(l\)的概率密度函数,\(g_l(f)\)为分类头\(g(\cdot)\)的第\(l^{th}\)个分类单元。根据公式3的对应关系,论文得到了用于分类模型的free energy公式:
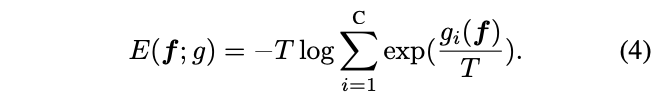
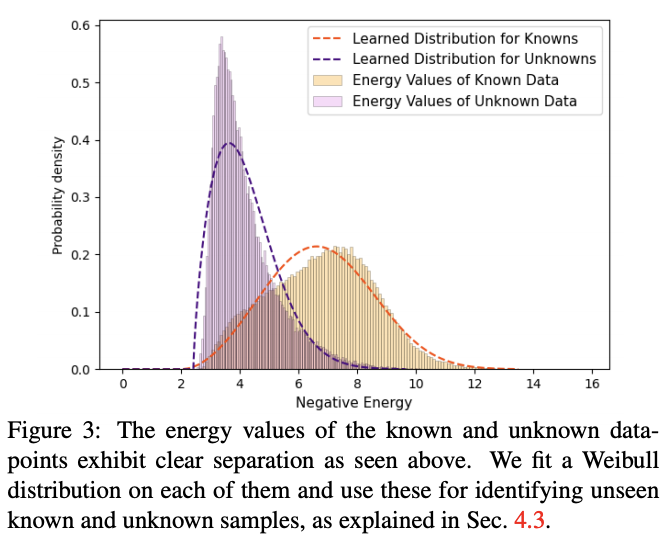
由于ORE用了对比聚类对特征进行分割,已知类别的能量值和未知类别的能量值也有明显的差别。对已知类别和未知类别的能量值分布进行shifted Weibull distributions建模,得到\(\xi_{kn}(f)\)和\(\xi_{unk}(f)\),如图3所示。当\(\xi_{kn}(f) < \xi_{unk}(f)\)时,可认为该目标属于未知类别。
Alleviating Forgetting
在对识别出来的未知目标进行标注后,得到了新的数据集,如果将所有数据集混合重新训练会很耗时且不够灵活,所以只能使用新数据集进行增量学习,这就需要解决新类别训练对旧类别识别效果的影响。
论文参照了增量学习的SOTA方法,使用简单的样本回放策略来保证旧类别的效果,先构造一个小的样本集(exemplar set),包含每个类别的\(N_{ex}\)个样本,每次使用全量新数据集进行增量学习后,都使用小样本集进行一次finetune训练,这样就能很好地保证旧类别的效果而且不耗时。
Experiment
Open World Evaluation Protocol
由于是一个全新的任务场景,论文也对实验进行了一些描述。
Data split
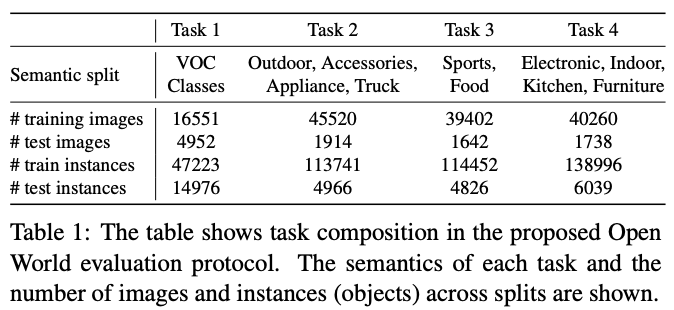
将所有类别分成多个任务\(\mathcal{T}=\{T_1, \cdots, T_t, \cdots\}\),具体的类别来源如表1所示。在特定的时间\(t\)将特定的任务\(T_t\)投放到场景中,类别\(\{T_{\tau}: \tau < t\}\)作为已知类别,而类别\(\{T_{\tau}: \tau > t\}\)则作为未知类别。
Evaluation metrics
由于未知目标容易识别成已知类别,使用Wilderness Impact(WI)指标来衡量这种表现:
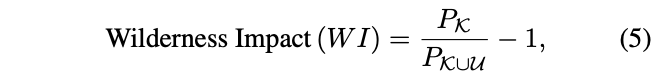
\(P_{\mathcal{K}}\)为在已知类别的验证集上的准确率,\(P_{\mathcal{K}\cup \mathcal{U}}\)为在已知类别和未知类别的验证集上的准确率,上述的准确率都是在0.8召回率下对应的值。理想情况下,WI的值越小越好,表明未知类别对准确率的干扰很少。此外,还使用Absolute Open-Set Error(A-OSE)来表示未知类别识别成已知类别的绝对数量,再加上目标检测常用的map指标。
Open World Object Detection Results
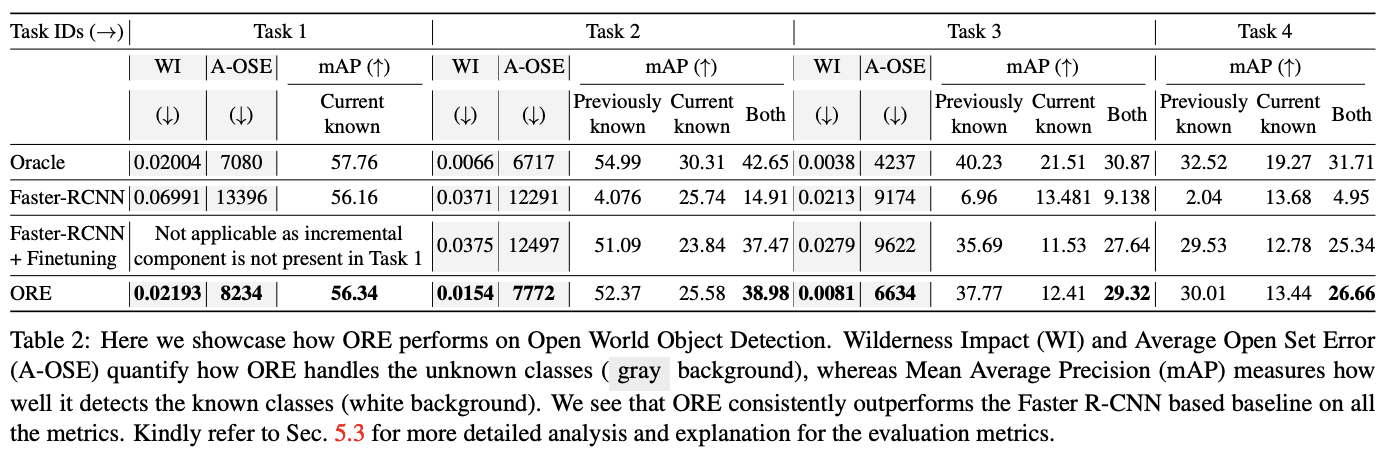

上述是一个主要的实验结果,论文还有很多对比实验,有兴趣的可以去看看。
Conclusion
不同于以往在固定数据集上测试性能,论文提出了一个更符合实际的全新检测场景Open World Object Detection,需要同时识别出未知类别和已知类别,并不断地进行增量学习。论文还给出了ORE解决方案,通过对比聚类和基于能量的分类器来进行开放开放世界的检测训练。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

OWOD:开放世界目标检测,更贴近现实的检测场景 | CVPR 2021 Oral的更多相关文章
- CVPR2021 | 开放世界的目标检测
本文将介绍一篇很有意思的论文,该方向比较新,故本文保留了较多论文中的设计思路,背景知识等相关内容. 前言: 人类具有识别环境中未知对象实例的本能.当相应的知识最终可用时,对这些未知实例的内在好奇心 ...
- Three.js 实现3D开放世界小游戏:阿狸的多元宇宙 🦊
声明:本文涉及图文和模型素材仅用于个人学习.研究和欣赏,请勿二次修改.非法传播.转载.出版.商用.及进行其他获利行为. 背景 2545光年之外的开普勒1028星系,有一颗色彩斑斓的宜居星球 ,星际移民 ...
- GDC2016 执着于光影表现的【全境封锁】的开放世界渲染
执着于光影表现[全境封锁]的开放世界渲染 Snowdrop(雪莲花)引擎的全局照明技术介绍 补上原文链接:http://game.watch.impress.co.jp/docs/news/201 ...
- 【SIGGRAPH 2015】【巫师3 狂猎 The Witcher 3: Wild Hunt 】顶级的开放世界游戏的实现技术。
[SIGGRAPH 2015][巫师3 狂猎 The Witcher 3: Wild Hunt ]顶级的开放世界游戏的实现技术 作者:西川善司 日文链接 http://www.4gamer.net/ ...
- 腾讯游戏 K8s 应用实践|更贴近业务场景的 K8s 工作负载:GameDeployment & GameStatefulSet
引言 蓝鲸容器服务(Blueking Container Service,以下简称BCS)是腾讯 IEG 互动娱乐事业群的容器上云平台,底层基于腾讯云容器服务(Tencent Kubernetes E ...
- Javascript高级编程学习笔记(32)—— 客户端检测(1)能力检测
能力检测 浏览器厂商虽然在实现公共接口方面投入了大量的精力 但是每种浏览器仍旧存在许多差异 为了让网页能跨浏览器的运行,对浏览器差异做的兼容处理自然无法避免 其中最常用的也就是我们现在所说的能力检测 ...
- OpenCV计算机视觉学习(13)——图像特征点检测(Harris角点检测,sift算法)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 前言 ...
- MAML-Tracker: 目标跟踪分析:CVPR 2020(Oral)
MAML-Tracker: 目标跟踪分析:CVPR 2020(Oral) Tracking by Instance Detection: A Meta-Learning Approach 论文链接:h ...
- 离群点检测与序列数据异常检测以及异常检测大杀器-iForest
1. 异常检测简介 异常检测,它的任务是发现与大部分其他对象不同的对象,我们称为异常对象.异常检测算法已经广泛应用于电信.互联网和信用卡的诈骗检测.贷款审批.电子商务.网络入侵和天气预报等领域.这些异 ...
- RxJS/Cycle.js 与 React/Vue 相比更适用于什么样的应用场景?
RxJS/Cycle.js 与 React/Vue 相比更适用于什么样的应用场景? RxJS/Cycle.js 与 React/Vue 相比更适用于什么样的应用场景? - 知乎 https://www ...
随机推荐
- 使用OpenWrt实现IPv6 DDNS
OpenWrt 增加 crontab 任务 在/root/crontab/ 目录下, 创建脚本 ddns.sh #!/bin/sh # 远程php脚本的URL地址 SERVICE_URL=http:/ ...
- mysqlGTID主从同步出现1236错误问题
从主库xtrabackup备份,配置好gtid复制,从主库的从库复制.一直报错误 Last_IO_Error: Got fatal error 1236 from master when readin ...
- Springboot+JdbcTemplate模拟SQL注入攻击案例及解决方法
说明 SQL注入是软件开发项目测试过程中必测项,重要等级极高.本文以springboot项目为例,模拟含有SQL注入攻击,并提供解决方法.部分内容整理自网络. 搭建项目 1.创建表tbuser DRO ...
- Spring Boot+Eureka+Spring Cloud微服务快速上手项目实战
说明 我看了一些教程要么写的太入门.要么就是写的太抽象.真正好的文章应该是快速使人受益的而不是浪费时间.本文通过一个包括组织.部门.员工等服务交互的案例让刚接触spring cloud微服务的朋友快速 ...
- go-ini解析ini文件
文档 https://github.com/go-ini/ini https://ini.unknwon.io/docs/intro/getting_started go get -u gopkg.i ...
- [Python] 超简单的 超星学习通自动签到
目录 概述 代码 其他的 文件编码问题 windows 和 linux下换行符不同的问题 概述 今天两节课的签到都错过了 /(ㄒoㄒ)/~~ 所以决定花点时间做一个自动签到的工具 经过观察发现超星的结 ...
- php的php-fpm
FastCgi与PHP-fpm到底是个什么样的关系 昨晚有一位某知名在线教育的大佬问了我一个问题,你知道php-fpm和cgi之间的关系吗?作为了一个5年的phper了,这个还不是很简单的问题,然后我 ...
- SPFA最短路
目录 从Bellman-Ford开始 核心思想 模拟算法执行过程 时间复杂度 模板 spfa spfa优化的思想 模板 从Bellman-Ford开始 对于所有边权都大于等于0的图,任意两个顶点之间的 ...
- Pandas导出美化技巧,让你的Excel更出众
pandas的DataFrame可以通过设置参数使得在jupyter notebook中显示的更加美观,但是,将DataFrame的数据导出excel时,却只能以默认最朴素的方式将数据写入excel. ...
- 关于debian安装完后输入法的问题
sudo apt install ibus-libpinyin后 重启计算机