MViTv2:Facebook出品,进一步优化的多尺度ViT | CVPR 2022
论文将
Multiscale Vision Transformers(MViTv2) 作为图像和视频分类以及对象检测的统一架构进行研究,结合分解的相对位置编码和残差池化连接提出了MViT的改进版本来源:晓飞的算法工程笔记 公众号
论文: MViTv2: Improved Multiscale Vision Transformers for Classification and Detection

Introduction
为不同的视觉识别任务设计架构一直很困难,而最广泛采用的架构是结合了简单性和有效性的架构,例如VGGNet和ResNet。最近,Vision Transformers(ViT) 已经显示出能够与卷积神经网络 (CNN) 相媲美的性能,涌现出大量将其应用于不同的视觉任务中的工作来。
虽然ViT在图像分类中很流行,但在高分辨率目标检测和视频理解任务中的应用仍然具有挑战性。视觉信号的密度对计算和内存要求提出了严峻的挑战,主要因为基于Transformer的模型的自注意力块的复杂度与输入长度呈二次方增长。目前有大量的研究来解决这个问题,比较主要的两个为:
- 使用窗口注意力,在一个窗口内进行局部注意力计算以及对象检测,主要用于目标检测任务。
- 使用池化注意力,在计算自注意力之前先聚合局部特征的,主要用于视频任务。
后者推动了Multiscale Vision Transformers(MViT)的研究,以简单的方式扩展ViT的架构。整个网络不再固定分辨率,而是构造从高分辨率到低分辨率的多个阶段的特征层次结构。
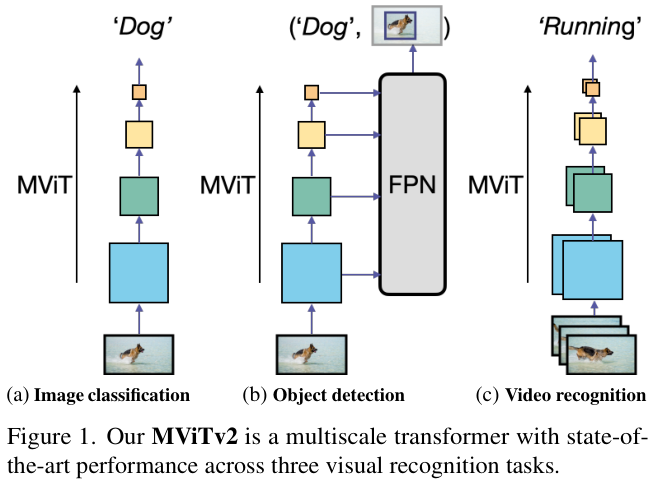
MViT专门为视频任务设计,具有最先进的性能。论文将MViT作为一个模型系列在图像分类、目标检测和视频分类中进行研究,从而了解它是否能够作为通用的视觉任务的主干网络。
根据研究结果,论文提出了改进的架构 (MViTv2),并包含以下内容:
- 从两个方面来大幅提升池化注意力的性能:
- 使用坐标分离的位置距离构造相对位置编码,在
Transformer块中注入平移不变的位置信息。 - 使用残差池化连接来补偿注意力计算中池化缩放带来的影响。
- 使用坐标分离的位置距离构造相对位置编码,在
- 根据标准的密集预测框架
Mask R-CNN with Feature Pyramid Networks(FPN)改进MViT结构,并将其应用于目标检测和实例分割。实验表明,池化注意力比窗口注意力机制(例如Swin)更有效。另外,论文进一步开发了一种简单的混合池化注意力和窗口注意力的方案,可以实现更好的准确性/计算权衡。 - 论文提供了五种尺寸的
MViT2架构,只需很少的修改就能作为图像分类、对象检测和视频分类的通用视觉架构。实验表明,MViT在ImageNet分类的准确率为88.8%,COCO对象检测的APbox准确率为58.7%,Kinetics-400视频分类的准确率为86.1%。其中,在视频分类任务上的准确率是非常出色的。
Revisiting Multiscale Vision Transformers
MViTv1的关键思想是为低级和高级视觉建模构建不同的阶段,而不是像ViT那样全是单尺度块。MViTv1缓慢地扩展通道宽度\(D\),同时降低网络输入到输出阶段的序列长度\(\boldsymbol{\mathit{L}}\),具体可以看之前的文章 【MViT:性能杠杠的多尺度ViT | ICCV 2021】。
为了在Transformer块内执行下采样,MViT引入了池化注意力(Pooling Attention)。具体来说,对于输入序列 \(X\in{\mathbb{R}}^{L\times D}\),分别对查询、键和值张量应用线性投影 \({W}_{Q}\)、\({W}_{K}\)、\({W}_{V}\in\mathbb{R}^{D\times D}\),以及池化运算符 (\({\mathcal{P}}\)):
\quad\quad(1)
\]
其中,\({Q}\in\mathbb{R}^{\tilde{L}\times D}\) 的长度 \(\tilde{L}\) 可减小 \({\mathcal{P}}_{Q}\) 倍,\(K\),\(V\) 的长度则可减少 \({\mathcal{P}}_{K}\) 和 \({\mathcal{P}}_{V}\)倍。
随后,使用池化注意力计算任意长度 \({\widetilde{L}}\) 的输出序列 \(Z\in\mathbb{R}^{{\tilde{L}}\times D}\) 的输出序列:
\quad\quad(2)
\]
请注意,键和值张量的下采样因子 \({\mathcal{P}}_{K}\) 和 \({\mathcal{P}}_{V}\) 可能与应用于查询序列的 \({\cal P}_{Q}\) 不同。
池化注意力通过池化查询张量 \({Q}\) 来降低MViT不同阶段之间的分辨率,通过池化键 \(K\) 和值 \(V\) 张量来显着降低块内的计算和内存复杂性。
Improved Multiscale Vision Transformers
Improved Pooling Attention

Decomposed relative position embedding
虽然MViT已经显示出其在token之间建模交互方面的能力,但它们关注的是内容,而不是结构。完全依赖于绝对位置编码来提供位置信息的时空结构建模,导致MViT忽略了视觉中平移不变性的基本原理。也就是说,即使相对位置保持不变,MViT对两个补丁之间的交互进行建模的方式也会根据token在图像中的绝对位置而改变。为了解决这个问题,论文将相对位置编码加入到自注意力计算中。
论文将两个输入元素 \(i\) 和 \(j\) 之间的相对位置表示为位置编码 \(R_{p(i),p(j)}{\in}\mathbb{R}^{d}\) ,其中 \(p({t})\) 和 \(p({j})\) 表示元素 \(i\) 和 \(j\) 的空间位置,随后将相对位置编码嵌入到自注意力模块中:
{{\mathrm{Attn}(Q,K,V)=\mathrm{Softmax}\left((Q K^{\textsf{T}}+E^{(\operatorname{rel})})/\sqrt{d}\right)V}}
\\
{{\mathrm{where}}} \ \ \ \ E_{i j}^{\mathrm{(rel)}}=Q_{i}\cdot R_{p(i),p(j)}
\end{array}
\quad\quad(3)
\]
但是,由于 \(R_{p(i),p(j)}\) 涉及时空坐标,存在的位置编码数量为 \({\cal O}(T W H)\),计算起来很复杂。为了降低复杂性,论文沿时空轴对元素 \(i\) 和 \(j\) 之间的距离进行分解计算:
\quad\quad(4)
\]
其中 \(R^{\mathrm{h}},R^{\mathrm{w}},R^{\mathrm{t}}\) 是沿高度、宽度和时间轴的位置编码,\(h(i)\)、\(w(i)\) 和 \(t(i)\) 分别表示标记的垂直、水平和时间位置。需要注意的是,\(R^{t}\) 是可选的,主要是为了支持视频任务中的时间维度。相比之下,论文的位置分解将学习编码的数量减少到 \(\mathcal{O}(H+W+H)\) ,这对早期的高分辨率特征图有很大的帮助。
Residual pooling connection
正如MViTv1所描述的,池化注意力对于降低注意力块中的计算复杂度和内存消耗非常有效。 一般情况下,在 \(K\) 和 \(V\) 张量的缩放因子要大于 \(Q\) 张量的缩放因子,而且 \(Q\) 张量仅在跨阶段的分辨率发生变化时才被下采样。为了避免特征信息因为较大的缩放因子而丢失,论文添加了与池化的 \(Q\) 张量的残差池化连接,增加信息流并促进MViT中池化注意力块的训练。
如图 2 所示,论文在注意力块内引入了一个新的残差池化连接。具体来说,论文将池化查询张量添加到输出序列 \(Z\) 中:
\quad\quad(5)
\]
需要注意的是,输出序列 \(Z\) 与池化张量 \(Q\) 的长度相同。
这里的残差连接和池化操作都是必须的,在非跨阶段的块中也要补一个步幅为 1 的池化操作对 \(Q\) 进行处理。由于这种改进的计算增加很少,所以仍能维持池化注意力的低计算复杂度。
MViT for Object Detection

FPN integration
MViT的层次结构分四个阶段生成多尺度特征图,可以自然地对接到目标检测的特征金字塔网络(FPN)中,如图 3 所示。通过将FPN与MViT主干结合使用,论文将其应用于不同的检测架构(例如Mask R-CNN)。
Hybrid window attention
Transformer中的自注意力对token数量具有二次方复杂度,这个问题在高分辨率输入的目标检测中更加严重。
池化注意力和窗口注意力都通过在计算自注意力时减少查询、键和值张量的大小来控制自注意力的复杂性,但它们的本质是不同的:
- 池化注意力池通过局部聚合对特征进行下采样,但保持全局自注意力计算。
- 窗口注意力保持张量的分辨率,将输入划分为非重叠窗口并在局部执行自注意力计算。
默认窗口注意力仅在窗口内执行本地自注意力,因此缺乏跨窗口的连接。与使用滑动窗口来缓解此问题的Swin不同,论文提出了一种简单的混合窗口注意力(Hwin)来添加跨窗口连接。
Hwin对FPN的最后三个阶段的所有块输入(最后阶段的最后一个块外)计算窗口注意力得到局部特征,最后一个块则进行全局自注意力(或池化注意力)计算使得FPN的输入特征图包含全局信息。
Positional embeddings in detection
与固定分辨率输入的ImageNet分类不同,目标检测的训练通常包含不同大小的输入。对MViT中的位置编码(绝对或相对),论文首先从ImageNet预训练权重初始化参数,对应 \(224\times224\) 输入的位置编码,然后将其插值到相应的大小以进行目标检测训练。
MViT for Video Recognition
由于升级的池化注意力可以泛化到时空域,MViT可以很简单地应用于视频识别任务(例如Kinetics)。虽然MViTv1仅关注Kinetics数据集上的预训练,MViTv2也会研究从ImageNet数据集上预训练的效果。
应用于图像的MViT与应用于视频的MViT对比有三个不同之处:
- 1)主干中的映射层需要将输入投影到时空立方体而不是
2D图像块。 - 2)池化运算符需要池化时空特征图。
- 3)相对位置编码加入时空位置。
由于 1) 和 2) 中的投影层和池化运算符默认由卷积层实现,因此论文使用inflation初始化,即将预训练模型中2D卷积层的权值除以T再复制T份形成3D卷积层(文章描述的做法跟参考文献有出入)。对于 3),论文基于提出的分离相对位置编码进行计算,简单地用预训练权值初始化空间位置编码,然后将时空位置编码初始化为零。
MViT Architecture Variants

如表 1 所示,论文构建了几个不同数量参数和计算量的MViT变体,以便与其他ViT模型进行比较。每个变体主要改变基础的通道尺寸、每个阶段的块数和块中的头数,一共有五个变体(Tiny、Small、Base、Large和Huge)。需要注意,论文使用较少的头数量来改善运行时间,这对计算量和参数量是没有影响的。
遵循MViT的池化注意力设计,论文默认在所有池化注意力块中使用键和值池化,并且池化步幅在第一阶段设置为 4,并根据阶段的分辨率自适应地衰减跨阶段的步幅。
Experiments: Image Recognition
论文对ImageNet分类和COCO对象检测进行了实验。
Image Classification on ImageNet-1K

ImageNet-1K数据集上的性能如表 2 所示,论文改进的MViTv2具有更高的准确性,并且计算量和参数更少。

ImageNet-21K数据集上的性能如表 3 所示。
Object Detection on COCO

MViTv2作为不同检测框架的主干网络的性能如表 5 所示。默认采用Hwin注意力,窗口设置为 \([56, 28, 14, 7]\),使用ImageNet-1k预训练。
Ablations on ImageNet and COCO

不同注意力机制在图像分类和目标检测任务中的表现如表 4 所示。

不同位置编码方式在图像分类和目标检测任务中的表现如表 6 所示。
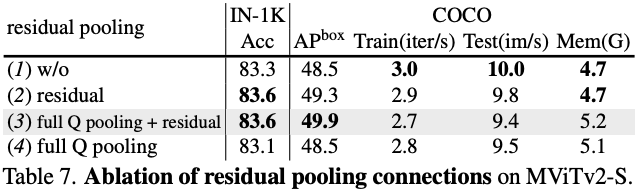
不同的残差池化策略在图像分类和目标检测任务中的表现如表 7 所示。
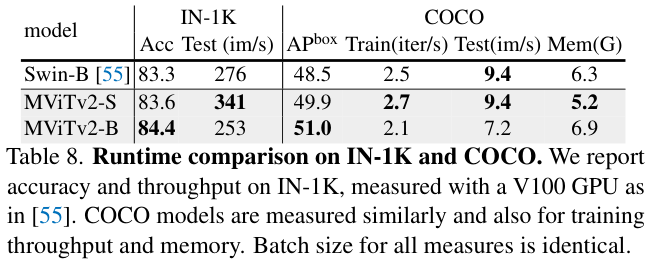
模型运行耗时在图像分类和目标检测任务中的表现如表 8 所示。

FPN对目标检测的影响如表 9 所示。
Experiments: Video Recognition
Main Results
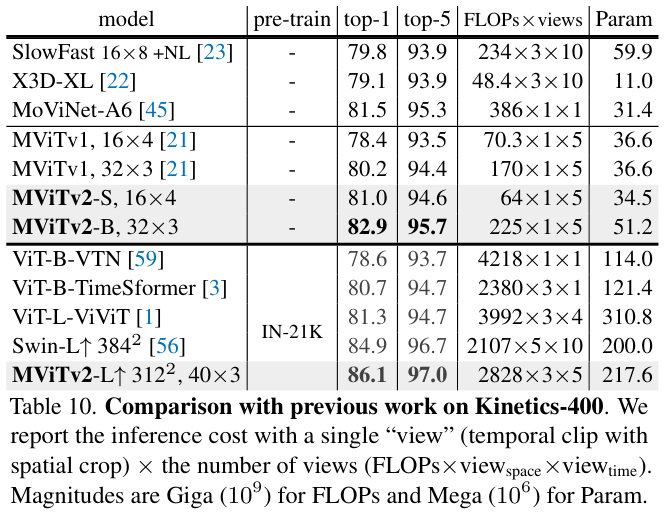


在不同量级的Kinetics数据集上的视频任务性能对比。

在SSv2数据集上的视频任务性能对比。
Ablations on Kinetics

在Kinetics-400数据集上对比不同预训练模型的性能。
Conclusion
论文提出了改进的Multiscale Vision Transformer作为视觉识别的通用主干网络。通过实验表明,MViT在图像分类、目标检测、实例分割和视频识别等广泛使用的基准测试中达到了最很不错的精度。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

MViTv2:Facebook出品,进一步优化的多尺度ViT | CVPR 2022的更多相关文章
- EF之结构进一步优化
针对之前的使用,做了进一步优化 1.将DAL对象缓存起来 2.仓储类不依赖固定构造的DbContext,执行操作的时候,从线程中动态读取DbContext,这一步也是为了方便将DAL对象缓存起来,解决 ...
- 采用DTO和DAO对JDBC程序进行进一步优化
采用DTO和DAO对JDBC程序进行进一步优化 DTO:数据传输对象,主要用于远程调用等需要远程调用对象的地方DAO:数据访问对象,主要实现封装数据库的访问,通过它可以把数据库中的表转换成DTO类 引 ...
- 进一步优化SPA的首屏打开速度(模块化与懒载入) by 嗡
前言 单页应用的优点在于一次载入全部页面资源,利用本地计算能力渲染页面.提高页面切换速度与用户体验.但缺点在于全部页面资源将被一次性下载完,此时封装出来的静态资源包体积较大,使得第一次打开SPA页面时 ...
- SSE图像算法优化系列二十一:基于DCT变换图像去噪算法的进一步优化(100W像素30ms)。
在优化IPOL网站中基于DCT(离散余弦变换)的图像去噪算法(附源代码) 一文中,我们曾经优化过基于DCT变换的图像去噪算法,在那文所提供的Demo中,处理一副1000*1000左右的灰度噪音图像耗时 ...
- 看Facebook是如何优化React Native性能
原文出处: facebook 译文出处:@Siva海浪高 该文章翻译自Facebook官方博客,传送门 React Native 允许我们运用 React 和 Relay 提供的声明式的编程模型, ...
- JavaScript中国象棋程序(8) - 进一步优化
在这最后一节,我们的主要工作是使用开局库.对根节点的搜索分离出来.以及引入PVS(Principal Variation Search,)主要变例搜索. 8.1.开局库 这一节我们引入book.js文 ...
- 进一步优化ListView
之前我已经分享过一篇:viewHodler的通用写法,就是专门用来优化listview的加载的,但是对于复杂的布局,我们还需要在listview滑动和不滑动时进行自己的处理,今天我看到一篇文章就是讲这 ...
- almond进一步优化requirejs
这里只是调侃一下,“杏仁”其实指的是almond,requirejs作者的另一个开源项目,它的定位是作为requirejs的一个替代品. 使用场景 什么情况下需要使用almond呢?假设你手头有个基于 ...
- SPFA算法 - Bellman-ford算法的进一步优化
2017-07-27 22:18:11 writer:pprp SPFA算法实质与Bellman-Ford算法的实质一样,每次都要去更新最短路径的估计值. 优化:只有那些在前一遍松弛中改变了距离点的 ...
- [置顶] 学习JDK源码:可进一步优化的代码
1.参数化类型的构造函数比较啰嗦 new HashMap<String, List<String>>() 如果你调用参数化类的构造函数,那么很不幸,你必须要指定类型参数,即便上 ...
随机推荐
- CSS——透明度
CSS 中提供了一个 opacity 属性用来设置元素的透明度,它不仅对颜色有效,对图像或者页面中其它的元素也有效. 其语法格式如下: opacity: number; 其中 number 为一个 0 ...
- ASP.NET Core、Winform、WPF 删除多余的Microsoft.CodeAnalysis语言资源文件
摘要:ASP.NET Core 3.1网站生成项目时,输出文件夹多出很多Microsoft.CodeAnalysis的语言资源文件github issue 问题# ASP.NET Core3.1网站生 ...
- Abp vNext框架 基础知识 依赖注入
依赖注入 ABP的依赖注入系统是基于Microsoft的依赖注入扩展库(Microsoft.Extensions.DependencyInjection nuget包)开发的.因此,它的文档在ABP中 ...
- 基于pulp的线性优化问题:微电网日前优化调度(复现)
摘录来源:(71条消息) 微电网日前优化调度入门:求解一道数学建模题_我不是玉的博客-CSDN博客 学习记录与复现 问题描述 问题出自第十届"中国电机工程学会杯"全国大学生电工数学 ...
- #define、const和enum
enum:枚举类型(枚举变量的值只能等于枚举中定义的常量) #define:明示常量(定义真正的常量) const:限定符(名不符实,应该叫read only),限定一个变量为只读 C语言常量: 1. ...
- TXT文本文件存储
用解析器解析出数据之后,接下来就是存储数据了.保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.CSV 等.另外,还可以保存到数据库中,如关系型数据库 MySQL,非关系 ...
- 2020-2021 ICPC, NERC, Southern and Volga Russian Regional Contest AGHIJM 题解
A. LaIS 设 \(dp_i\) 为到第 i 位的最长的 almost increasing 长度.可以发现,这个 \(dp_i\) 的转移只有从 \(a_j \leq a_i\) 的地方转移过去 ...
- 13-flex
01 flex2个重要的概念 02 flex布局模型 03 flex相关属性 04 flex container相关属性 4.1 flex direction 不同的值会改变主轴的方向 4.2 fle ...
- Lfu缓存在Rust中的实现及源码解析
一个 lfu(least frequently used/最不经常使用页置换算法 ) 缓存的实现,其核心思想是淘汰一段时间内被访问次数最少的数据项.与LRU(最近最少使用)算法不同,LFU更侧重于数据 ...
- Android Framework:如何让 App 拿到Power key 值
Android app:如何让 App 拿到Power key 值 原文(有删改):https://blog.csdn.net/qq_37858386/article/details/10383566 ...