2天完成17TB数据量迁移,华为云数据库是如何做的?
摘要:童年时候,我们会对着墙上挂着的中国地图,来认识一处处山川河流和城市人文。如今,数字化时代下,传统的地图已经不能满足人们的需求,如何获取各种丰富的地理内容和实时动态信息成为现代人普遍的地理信息诉求。作为国家基础地理信息公共服务平台,天地图集成了来自国家、省、市(县)各级测绘地理信息部门,以及相关政府部门、企事业单位 、社会团体、公众的地理信息公共服务资源,以门户网站、服务接口、前置服务等形式向政府、专业部门、企业、公众等用户提供在线地理信息服务。此前,国家基础地理信息中心携手华为云,基于天地图平台,共同打造云上智慧地图,促进地理信息资源共享和高效利用,让世界触手可及。
地理数据量增加,数据库弹性迎挑战
天地图覆盖全国300多个地级以及地级以上城市0.6米分辨率的卫星遥感影像等地理信息数据,全库数据量达到17TB,数据吞吐量巨大。巨大的吞吐量和高额运维成本,促使国家基础地理信息中心迫切寻求低成本、高可用、高性能、大容量的数据库产品,同时希望可以将迁移时间压缩到2天左右。
- 低成本:早期天地图运营投入较多资金,包括数据库在内的IT投入成本居高不下。业务有读写分离诉求,希望在保证性能的前提下,通过一套实例实现读写分离,从而降低数据库成本。
- 高可用:社区版MongoDB一个shard多数节点故障,就会导致该shard成为只读,因此希望提供无状态的路由节点,实现快速故障转移。
- 高性能:天地图每天的访问量在6亿左右,随着数据量和业务访问量的增加,现有系统不足以支撑日益增长的业务需求,需要更高性能的数据库来支撑日益增长的业务数据。
- 容量:随着瓦片层级增加,数据量越来越大,现有MongoDB扩容难度大,需要一款数据库支持不少于20TB的瓦片数据,支持在线扩容。
- 运维效率:运维人力有限,系统运维压力越来越大,运维工作成本越来越高,现有社区版MongoDB难以支撑运维工作需求。希望能够提供数据库自运维能力,能为数据库做技术兜底,降低运维成本。

天地图&华为云
- 彰显云上“数字中国”新魅力
天地图业务数据复杂,数据种类多样,结合客户诉求和业务特点,华为云数据库采用公有云对外服务为主,私有云对内测试为辅的混合云架构,提供多种数据库引擎方案,联合打造高性能、高可用的数字底座。
华为云GaussDB(for Mongo)提供在线地图的瓦片数据处理服务;华为云RDS for PostgreSQL提供矢量数据和三维数据处理服务;华为云RDS for MySQL提供用户管理和专题图层属性服务,多款数据库极速融合,共同发力,17TB的海量数据迁移仅仅用了2天。
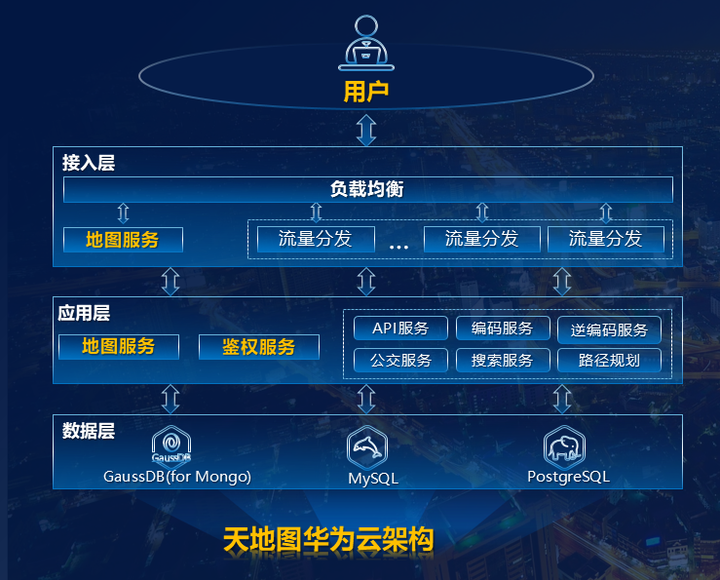
- 高可用特性加持,业务稳定运行
天地图作为国家级的服务平台,数据的安全可靠可谓至关重要。华为云GaussDB(for Mongo)支持跨AZ高可用,拥有完善的跨区域容灾策略,每天自动进行全量备份和增量备份,并定期进行恢复演练,验证备份恢复流程的有效性,实现分钟级备份恢复。同时提供无状态的路由节点,支持秒级故障转移,客户业务无感知,业务运行稳定。
- 超高性能与大容量,再大流量也不怕
天地图为30+部委机构和全国30多个省市提供地理信息基础平台服务,日均API和服务调用超过6亿次,访问压力极大。华为云GaussDB(for Mongo) 可实现分钟级节点扩容和秒级存储扩容,满足敏捷业务弹性需要,对天地图高达上亿的访问毫无压力,响应能力快稳准,有效保障了天地图在高负载情景下业务的正常运行。而且GaussDB(for Mongo)基于存算分离架构和rocksdb优化,相比开源MongDB性能提高3倍以上,最大支持96TB的数据处理能力,完全满足天地图海量业务请求。
- 降本增效不止一点点
GaussDB(for Mongo)完全兼容MongoDB协议,客户业务无需任何改造,即可轻松切换数据库,极大减少了改造成本;而且通过实时生成快照和删除快照的能力,GaussDB(for Mongo)实现一套集群即可提供读写分离的能力,数据库成本节省至少50%。天地图上华为云之后,基于数据库服务自动化运维平台,数据更新效率提升5倍,新业务上线速度提高2倍,还减轻了DBA繁重的运维压力,让客户更聚焦业务层面。
自2019年2月上线以来,华为云数据库已轻松支撑天地图6亿+的日均访问量,保障业务平稳运行,实现零事故;同时为公众提供了更为全面、精准、权威、 智能、人性化的地理信息服务,让全社会共享测绘发展成果,感受“数字中国”的独特魅力。
Ps:【云数据库特惠专场】新用户4.5折起,助力企业效益增长,详情请戳https://activity.huaweicloud.com/dbs_Promotion/index.html
2天完成17TB数据量迁移,华为云数据库是如何做的?的更多相关文章
- 从SQL Server到MySQL,近百亿数据量迁移实战
从SQL Server到MySQL,近百亿数据量迁移实战 狄敬超(3D) 2018-05-29 10:52:48 212 沪江成立于 2001 年,作为较早期的教育学习网站,当时技术选型范围并不大:J ...
- sql 数据量高并发的数据库优化(转)
Mysql 大数据量高并发的数据库优化 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实 ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- phpmyadmin 打开数据表较多,数据量较大的数据库时出现超时的解决办法
用phpmyadmin打开数据表较多,数据量较大的数据库时,会出现超时,或者等半天打开了说数据库没有表.并且即便打开了,再进行其他浏览,编辑,sql等操作,页面也是相当慢的,慢等几乎无法忍受.这里慢也 ...
- 华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库:它依靠共享存储池实现了强一致,保证数据的安全可靠. 本文 ...
- elasticsearch5.0集群大数据量迁移方法及注意事项
当es集群的数据量较小的情况下elasticdump这个工具比较方便,但是当数据量达到一定级别比如上百G的时候,elasticdump速度就很慢了,此时我们可以使用快照的方法进行备份 elasticd ...
- MYSQL千万级别数据量迁移Elasticsearch5.6.1实战
从关系型库中迁移数据算是比较常见的场景,这里借助两个工具来完成本次的数据迁移,考虑到数据量并不大(不足两千万),未采用snapshot快照的形式进行. Elasticsearch-jdbc,Githu ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 大数据量高并发的数据库优化,sql查询优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 通过Canal将云上MySQL数据同步到华为云ES(CSS)中
背景: A部门想将mysql中多张表join成一个sql查询语句,然后将结果同步到es中供搜索使用 环境信息: 源端mysql在阿里云上,有公网ip 目标端es在华为云上,三节点 操作步骤与目的: 配 ...
随机推荐
- 【第一章 web入门】afr_3——模板注入与proc文件夹
[第一章 web入门]afr_3--模板注入与proc文件夹 题目来源n1book,buu上的环境 看题 url中提供了name参数,类似在路径中进行了文件名查询然后展示: 随便输入一个数字: 说明肯 ...
- windows平板的开发和选型
今天谈一个老话题,windows系统的选型和开发.问题的起因是我们一个客户说,用安卓平板不安全,苹果系统不考虑,于是他们要用自认为安全的WIN7系统. 提到WINDOWS平台下的的平板系统,此事说来话 ...
- 2.MongoDB Sharding Cluster分片集群
分片集群-规划 10个实例:38017-38026 (1)configserver:38018-38020 3台构成的复制集(1主两从,不支持arbiter)38018-38020(复制集名字conf ...
- ACAM 学习笔记 | 附 YbtOJ 全部题解
怎么有人现在才学 ACAM 呢. 好像比 SAM 简单挺多啊,也不记得当时是哪里看不懂. AC 自动机() 自动 AC 机(✘) 概述 ACAM(Aho–Corasick Automaton),是用来 ...
- 红瞳瞳CRUD Avue各参数作用
常用的两个avue文档: avue 开发文档: https://www.bookstack.cn/read/avue-2.x/3c22e1c01099c1f1.md avue开发指南:https: ...
- 题解 CF637B
题目大意: 维护个栈,去重保留最上层 题目分析: 啥也不是,数组模拟 \(\text{stack} + \text{unordered\_map}\) 直接秒掉. 复杂度 \(O(n)\) 代码实现: ...
- Android 输入系统介绍
目录 一.目的 二.环境 三.相关概念 3.1 输入设备 3.2 UEVENT机制 3.3 JNI 3.4 EPOLL机制 3.5 INotify 四.详细设计 4.1 结构图 4.2 代码结构 4. ...
- python中面向对象有什么特点
一:问题 python中面向对象有什么特点? 二:回答 python同其他面向对象语言一样,有3个特征:封装.继承.重写 简单理解就是:封装:把一系列属性和操作封装到一个方法里面,这样想要实现某种效果 ...
- String.trim()含义
就是去除两端空格,目前只用到了这个.
- Springboot的Container Images,docker加springboot
Spring Boot应用程序可以使用Dockerfiles容器化,或者使用Cloud Native Buildpacks来创建优化的docker兼容的容器映像,您可以在任何地方运行. 1. Effi ...