大数据实践解析(上):聊一聊spark的文件组织方式
摘要:
在大数据/数据库领域,数据的存储格式直接影响着系统的读写性能。Spark针对不同的用户/开发者,支持了多种数据文件存储方式。本文的内容主要来自于Spark AI Summit 2019中的一个talk【1】,我们将整个talk分为上下两个部分,上文会以概念为主介绍spark的文件/数据组织方式,下文中则通过例子讲解spark中的读写流程。本文是上半部分,首先会对spark中几种流行的文件源(File Sources)进行特性介绍,这里会涉及行列存储的比较。然后会介绍两种不同的数据布置(Data layout),分别是partitioning以及bucketing,它们是spark中两种重要的查询优化手段。
文件格式
在介绍文件格式之前,不得不提一下在存储过程中的行(Row-oriented)、列(Column-oriented)存储这两个重要的数据组织方式,它们分别适用于数据库中OLTP和OLAP不同的场景。spark对这两类文件格式都有支持,列存的有parquet, ORC;行存的则有Avro,JSON, CSV, Text, Binary。
下面用一个简单的例子说明行列两种存储格式的适用场景:
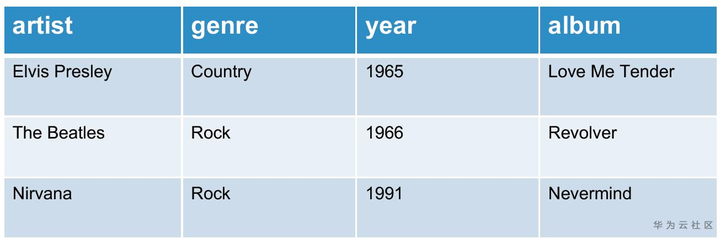
在上图的music表中,如果用列存和行存存储会得到下面两种不同的组织方式。在左边的列存中,同一列的数据被组织在一起,当一列数据存储完毕时,接着下一列的数据存放,直到数据全部存好;而在行存中,数据按照行的顺序依次放置,同一行中包括了不同列的一个数据,在图中通过不同的颜色标识了数据的排列方法。

如果使用列存去处理下面的查询,可以发现它只涉及到了两列数据(album和artist),而列存中同一列的数据放在一起,那么我们就可以快速定位到所需要的列的位置,然后只读取查询中所需要的列,有效减少了无用的数据IO(year 以及 genre)。同样的,如果使用行存处理该查询就无法起到 “列裁剪“” 的作用,因为一列中的数据被分散在文件中的各个位置,每次IO不可避免地需要读取到其他的数据,所以需要读取表中几乎所有的数据才能满足查询的条件。

通过这个例子可以发现,列存适合处理在几个列上作分析的查询,因为可以避免读取到不需要的列数据,同时,同一列中的数据放置在一起也十分适合压缩。但是,如果需要对列存进行INSET INTO操作呢?它需要挪动几乎所有数据,效率十分低下。行存则只需要在文件末尾append一行数据即可。在学术界,有人为了中和这两种“极端”的存储方式,提出了行列混存来设计HTAP(Hybrid transactional/analytical processing)数据库,感兴趣的读者可以参考【2】。
所以简单总结就是:列存适合读密集的workload,特别是那些仅仅需要部分列的分析型查询;行存适合写密集的workload,或者是要求所有列的查询。
文件结构介绍
- Parquet
在Parquet中,首尾都是parquet的magic number,用于检验该文件是否是一个parquet文件。Footer放在文件的末尾,存放了元数据信息,这里包括schema信息,以及每个row group的meta data。每个row group是一系列行数据的组成,row group中的每个column是一个列。
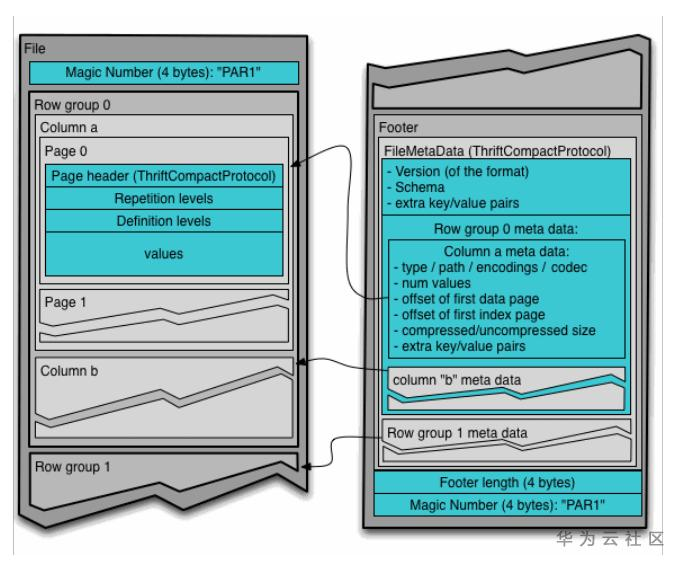
parquet格式能有效应用查询优化中的优化规则,比如说谓词下推(Predicate Push),将filter的条件推到扫描(Scan)数据时进行,减少了上层操作节点不必要的计算。又比如通过设置元数据中的min/max,在查询时可以拿着条件和元数据进行对比,如果查询条件完全不符合min/max,则可以直接跳过元数据所指的数据块,减少了无用的数据IO。
- ORC
ORC全称是Optimized Row Columnar,它的组织方式如下图,其中
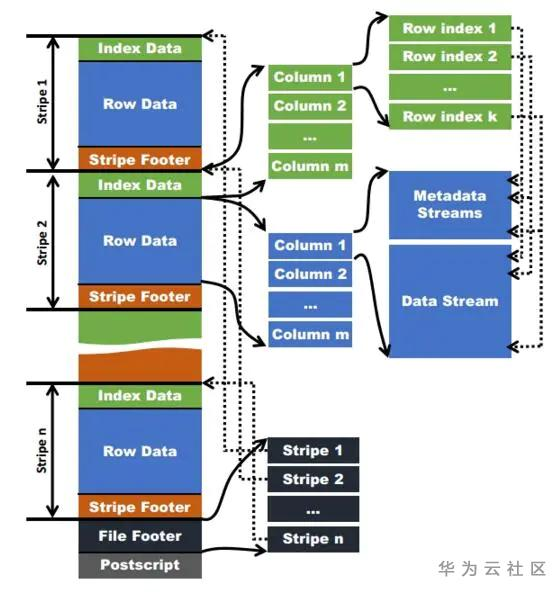
Postsctipt保存了该表的行数,压缩参数,压缩大小,列等信息;
File Footer中是各个stripe的位置信息,以及该表的统计结果;
数据分成一个个stripe,对应于parquet中的row group;
Stripe Footer主要是记录每个stripe的统计信息,包括min,max,count等;
Row data是数据的具体存储;
Index Data保存该stripe数据的具体位置,总行数等。
它们之间的关系在上图中用虚实线做了很好的补充。
行存文件格式
行存相较于列存会比较简单,在实际开发中可能也接触会相对较多,所以这里简单介绍其优缺点。
- Avro:Avro的特点就是快速以及可压缩,并且支持schema的操作,比如增加/删除/重新命名一个字段,更改默认值等。
- JSON:在Spark中,通常被当做是一个结构体,在使用过程中需要注意key的数目(容易触发OOM错误),它对schema的支持并不是很好。优点是轻量,容易部署以及便于debug。
- CSV:通常用于数据的收集,比如说日志信息等,写性能比读性能好,它的缺点是文件规范的不够标准(分隔符,转义符,引号),对嵌套数据类型的支持不足等。它和JSON都属于半结构化的文本结构。
- Raw text file:基于行的文本文件,在spark中可通过 spark.read.text()直接读入并按行切分,但是需要保持行的size在一个合理的值,支持有限的schema。
- Binary:二进制文件,是Spark 3.0 的新特性。Spark会读取每个binary文件并转化成一条记录(record),该记录(record)会存储原始的二进制数据以及文件的matedata。这里记录(record)是一个schema,包括文件的路径(StringType),文件被修改的时间(TimestampType),文件的长度(LongType)以及内容(BinaryType)。
例如,如果我们需要递归读取某目录下所有的JPG文件则可以通过下面的API来完成:
spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/path/to/dir")
数据布置(Data layout)
partitioning
分区(Partition)是指当数据量很大时,可以按照某种方式对数据进行粗粒度切分的方式,比如在上图中按year字段进行了切分,在year字段内部,又将genre字段进行了切分。这样带来的好处也是显而易见的,当处理“year = 2019 and genre = ‘folk’”的查询时,就可以过滤掉不需要扫描的数据,直接定位到相应的切片中去做查询,提高了查询效率。
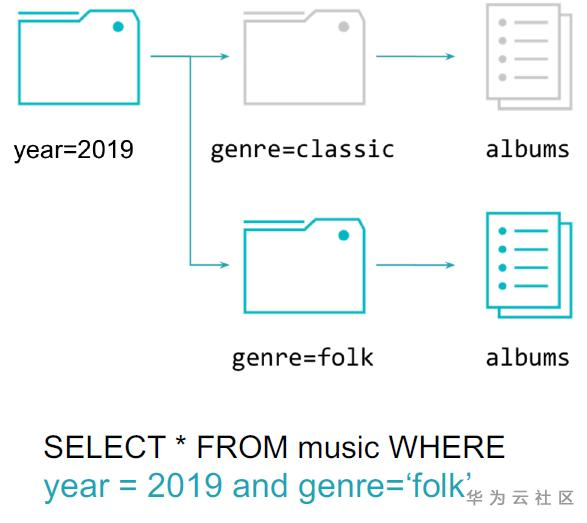
在Spark SQL和DataFrame API分别提供了相应的创建partition的方式。

同时,越多的分区并不意味着越好的性能。当分区越多时,分区的文件数也随着增多,这给metastore获取分区的数据以及文件系统list files带来了很大的压力,这也降低了查询的性能。所以建议就是,选取合适的字段做分区,该字段不应出现过多的distinct values,使分区数处于一个合适的数目。如果distinct values很多怎么办?可以尝试将字段hash到合适的桶中,或是可以使用字段中的一小部分作为分区字段,比如name中的第一个字母。
bucketing
在Spark的join操作中,如果两边的表都比较大,会需要数据的shuffle,shuffle数据会占据查询过程中大量的时间,当某个耗时的Join的字段被频繁使用时,我们可以通过使用分桶(bucketing)的手段来优化该类查询。通过分桶,我们将数据按照joinkey预先shuffle及排序,每次处理sort merge join时,只需要各自将自己本地的数据处理完毕即可,减少了shuffle的耗时。这里要注意,分桶表的性能和分桶的个数密切相关,过多的分桶会导致小文件问题,而过少的分桶会导致并发度太小从而影响性能。
分桶前的Sort merge join:
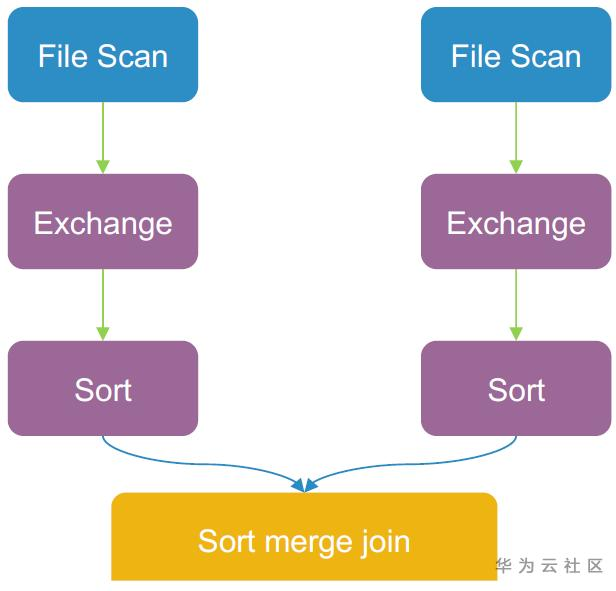
分桶后:
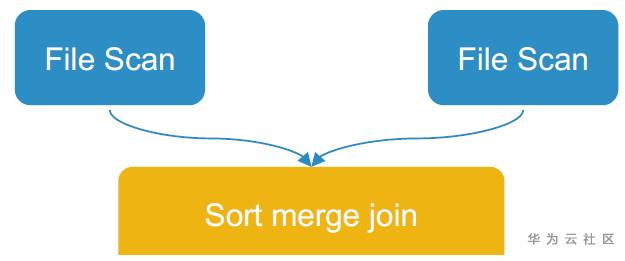
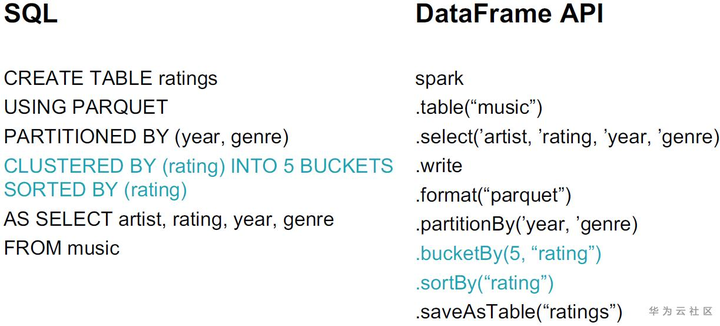
在Spark SQL和DataFrame API分别提供了相应的创建分桶的方式。通过排序,我们也可以记录好min/max,从而避免读取无用的数据。
参考
【1】Databricks. 2020. Apache Spark's Built-In File Sources In Depth - Databricks. [online] Available at: <https://databricks.com/session_eu19/apache-sparks-built-in-file-sources-in-depth>.
【2】 Bridging the Archipelago betweenRow-Stores and Column-Stores for Hybrid Workloads (SIGMOD'16)
大数据实践解析(上):聊一聊spark的文件组织方式的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据实践:ODI 和 Twitter (二)
大数据实践:ODI和Twitter(二) 在前面的文章中,我们已经使用flume将数据从twitter抓取到Hive中,现在我们来看看ODI(Oracle Data Integrator)如何在HIV ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大众点评的大数据实践-CSDN.NET
大众点评的大数据实践-CSDN.NET 大众点评的大数据实践 爬虫工程师成大数据时代的"宠儿" - 杭州新闻中心 - 杭州网 爬虫工程师成大数据时代的"宠儿"
- 大数据实践:ODI 和 Twitter (一)
本文利用twitter做为数据源,介绍使用Oracle大数据平台及Oralce Data Integrator工具,完成从twitter抽取数据,在hadoop平台上处理数据,并最终加载到oracle ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 分布式处理与大数据平台(RabbitMQ&Celery&Hadoop&Spark&Storm&Elasticsearch)
热门的消息队列中间件RabbitMQ,分布式任务处理平台Celery,大数据分布式处理的三大重量级武器:Hadoop.Spark.Storm,以及新一代的数据采集和分析引擎Elasticsearch. ...
随机推荐
- nvm的安装及使用(入门级)
1 从官网下载压缩包到本地 下载地址: https://github.com/coreybutler/nvm-windows/releases 2 配置 2.1 settings.txt配置 (1)下 ...
- 如何将linux设置成网关
如何将linux设置成网关 打开网关linux的端口转发功能:echo '1' > /proc/sys/net/ipv4/ip_forward 在VMWare中创建一个仅主机的内网: 进入本机配 ...
- Frog 3 题解
Frog 3 题目大意 题意都这么明确了还要这个干什么. 存在 \(n\) 个点,每个点有一个属性 \(h_i\),\(h_i\) 单增,从点 \(i\) 移动到点 \(j(j>i)\) 的代价 ...
- C++中const和constexpr的多文件链接问题
C++语言支持分离编译,在多文件编程中:变量或函数可以被声明多次,但却只能被定义一次.如果要在多个文件中使用同一个变量,变量的定义能且只能出现在一个文件中,在其他使用该变量的文件中需要声明该变量.如果 ...
- Spring Cloud Gateway系列:简介和入门
一.简介 官网:https://cloud.spring.io/spring-cloud-gateway/reference/html/ SpringCloud Gateway是SpringCloud ...
- RLChina2022公开课-博弈搜索算法
序列决策 序列决策问题一般用马尔可夫决策模型进行描述 搜索算法的优化
- 如何通过Python代码旋转PDF页面
前言 日常处理 PDF 文档时,我们时常会遇到页面颠倒.很难正常阅读或打印的情况. 在这种情况下,我们可以通过旋转页面来调整文档的方向.旋转时,也可以根据具体情况,选择顺时针或逆时针旋转特定的角度,以 ...
- trafilatura 网页解析原理分析
trafilatura 介绍 Trafilatura是一个Python包和命令行工具,用于收集网络上的文本.其主要应用场景包括网络爬虫下载和网页解析等. 今天我们不讨论爬虫和抓取,主要看他的数据解析是 ...
- JVM SandBox 的技术原理与应用分析
https://www.infoq.cn/article/tsy4lgjvsfweuxebw*gp https://blog.csdn.net/qq_40378034/article/details/ ...
- Spring系列:基于XML的方式构建IOC
目录 一.搭建模块spring6-ioc-xml 二.获取bean的三种方式 三.基于setter注入 四.基于构造器注入 五.特殊值处理 六.为对象类型属性赋值 七.引入外部属性文件 八.基于XML ...