监控Celery不一定非要使用Flower
运维平台中有许多的周期/定时/异步任务,例如证书扫描、数据备份、日志清理、线上作业等等,这些任务的执行都是借助于Celery来完成的。任务多了之后就会遇到一系列的问题,例如我之前写过的将任务分多队列来解决生产环境下的任务优先级问题,除此之外还要经常关注队列的状态以及任务的运行情况,为了方便查看任务以及Worker的运行情况,我在后台中添加了队列状态这个功能
这个功能参考了Celery知名监控工具Flower的实现,之所以没有直接使用Flower,主要有几方面的考虑,其一是Flower的页面风格与我们本身的平台风格差异较大,其二是Flower要单独启动进程或者是去看代码深度集成,比较麻烦,其三也是想要更加深入的了解下Celery,毕竟项目用了它,了解不深遇到问题不好解决。基于以上几点考虑,就自己实现了Celery监控功能的开发。好在并不复杂,Celery本身提供了一组API,可以查询任务队列的状态、执行结果等信息。借助于这些API就能完成比较详细的监控,Celery的API主要有两个
inspect
app.control.inspect(): 这个方法返回一个Inspect对象,可以使用它来获取任务队列、工作节点等的信息。例如inspect().active()可以获取当前活动的任务列表,inspect().registered()可以获取已注册的任务列表,不指定worker的情况下查看全部worker的数据,如果指定worker则查看对应worker的数据
具体的用法如下:
from celery import Celery
app = Celery('your_celery_app_name')
# 检查工作节点的在线状态
worker_status = app.control.inspect([worker]).ping()
# 返回工作节点的统计信息,如活动任务数、完成任务数等
worker_stats = app.control.inspect([worker]).stats()
# 返回活动任务的信息
active_tasks = app.control.inspect([worker]).active()
# 返回已注册任务的信息
registered_tasks = app.control.inspect([worker]).registered()
# 返回计划中的任务的信息
scheduled_tasks = app.control.inspect([worker]).scheduled()
# 返回已预订任务的信息
reserved_tasks = app.control.inspect([worker]).reserved()
# 返回已撤销任务的信息
revoked_tasks = app.control.inspect([worker]).revoked()
# 返回活动队列的信息
active_queues = app.control.inspect([worker]).active_queues()
# 查询worker的配置信息
worker_conf = app.control.inspect([worker]).conf()
# 返回工作节点的报告信息
worker_reports = app.control.inspect([worker]).report()
# 查询特定任务的信息
task_info = app.control.inspect([worker]).query_task(task_id)
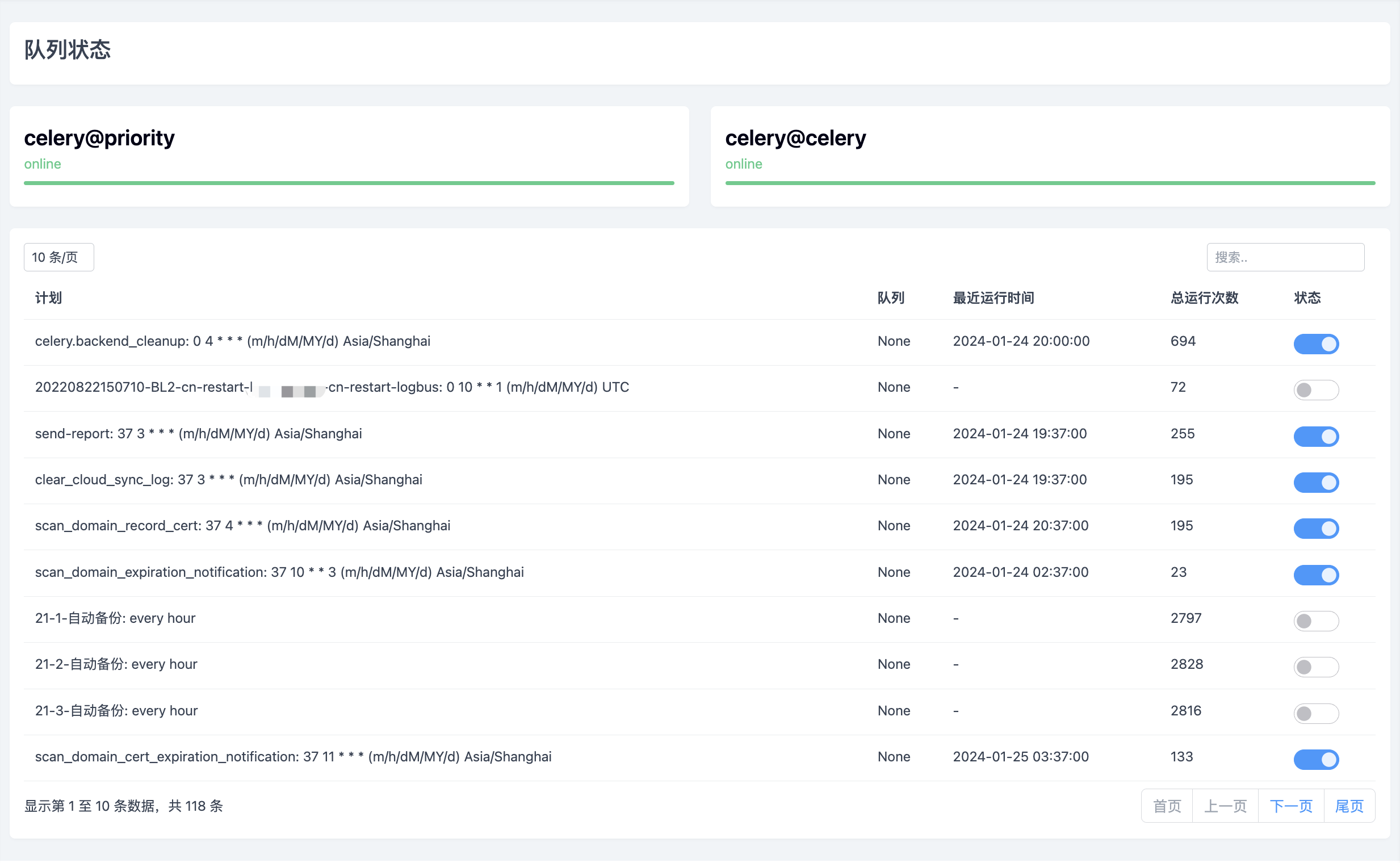
通过inspect可以查看celery整体以及单个worker的相关信息,例如首页的状态就是通过ping来实现的

一个card表示一个worker,点击card可以查看worker的详细信息,例如Pool标签的数据就来自于stats,Register标签的数据就来自于registered,Tasks标签就分别展示了active、scheduled、reserved和revoked的任务数据
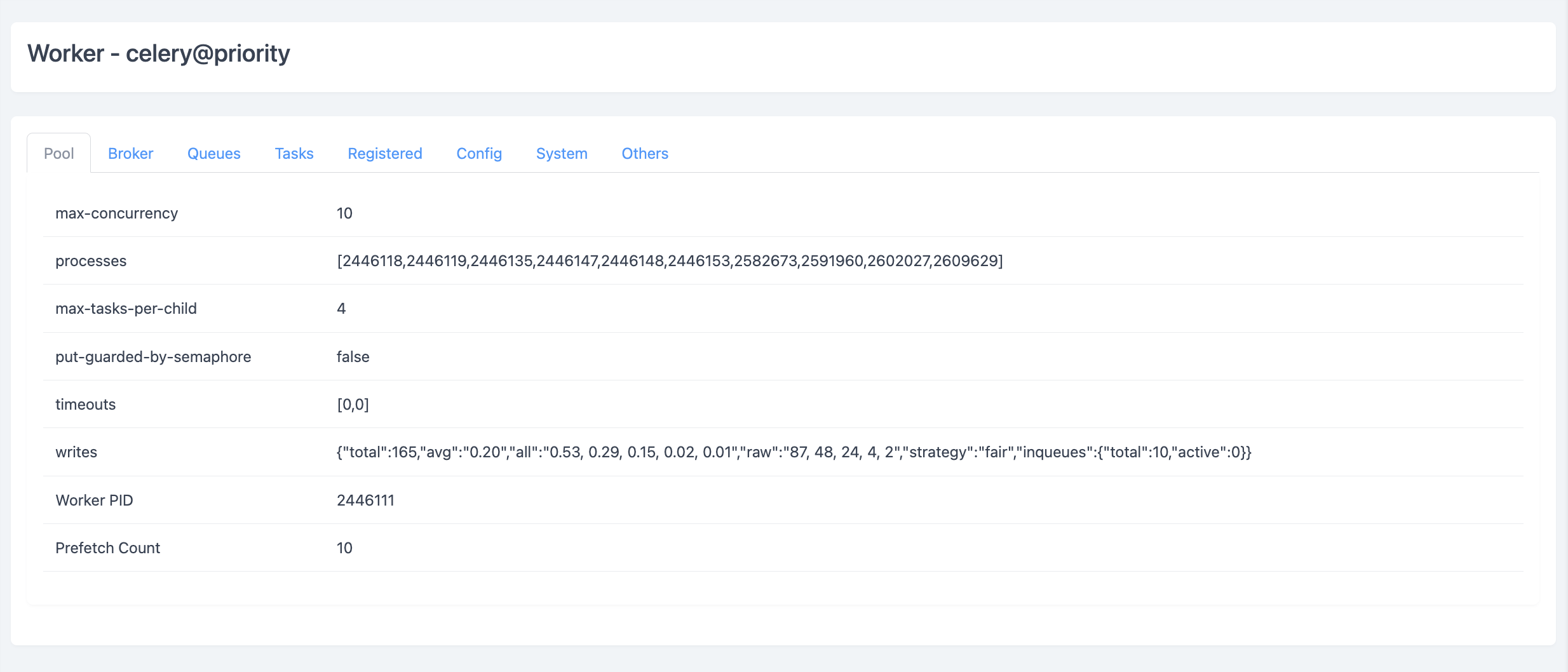
通过这些信息可以全面掌握Celery的运行状态以及每个Worker的运行情况,做到对Celery的全局掌控
AsyncResult
AsyncResult: 这个类可以查询特定任务的状态和结果。通过任务的ID创建一个AsyncResult对象,并使用其方法来获取任务的状态、结果等信息。例如AsyncResult(task_id).state可以获取任务的状态,AsyncResult(task_id).result可以获取任务的执行结果
具体的用法如下:
from celery import Celery
app = Celery('your_celery_app_name')
result = app.AsyncResult(task_id)
# 获取任务状态
state = result.state
# 获取任务结果
result = result.result
# 返回一个布尔值,检查任务是否已经完成
is_ready = result.ready()
# 返回一个布尔值,检查任务是否成功完成
is_successful = result.successful()
# 返回一个布尔值,检查任务是否执行失败
is_failed = result.failed()
# 返回一个字符串,获取任务的错误追溯信息
traceback = result.traceback
# 返回一个AsyncResult对象,获取任务的父任务
parent_task = result.parent
# 返回一个列表,包含任务的子任务的AsyncResult对象,获取任务的子任务
child_tasks = result.children
# 返回一个字典,获取任务的其他信息
info = result.info
# 获取任务的结果,可以指定超时时间和是否向上传播异常
result = result.get(timeout=10, propagate=False)
# 忘记任务,将任务从结果存储中删除。一旦任务被遗忘,将无法查询其状态和结果
result.forget()
通过AsyncResult可以获取到任务执行的相关信息,对任务执行过程和结果都有很好的把控。不过这需要任务的ID,任务ID通常可以通过任务执行时获取,ops_coffee_auto_notify_task.delay()异步执行任务后返回的就是任务的ID。但对于任务的话我通常会单独记录任务执行的过程和状态,而不依赖Celery的结果记录,所以对于AsyncResult的需求并不强
但平常需要开关系统内置的周期任务,此时就需要知道系统任务列表,通过获取PeriodicTask表的数据即可,同时通过修改PeriodicTask表的enabled字段值来达到开启或暂停的目的
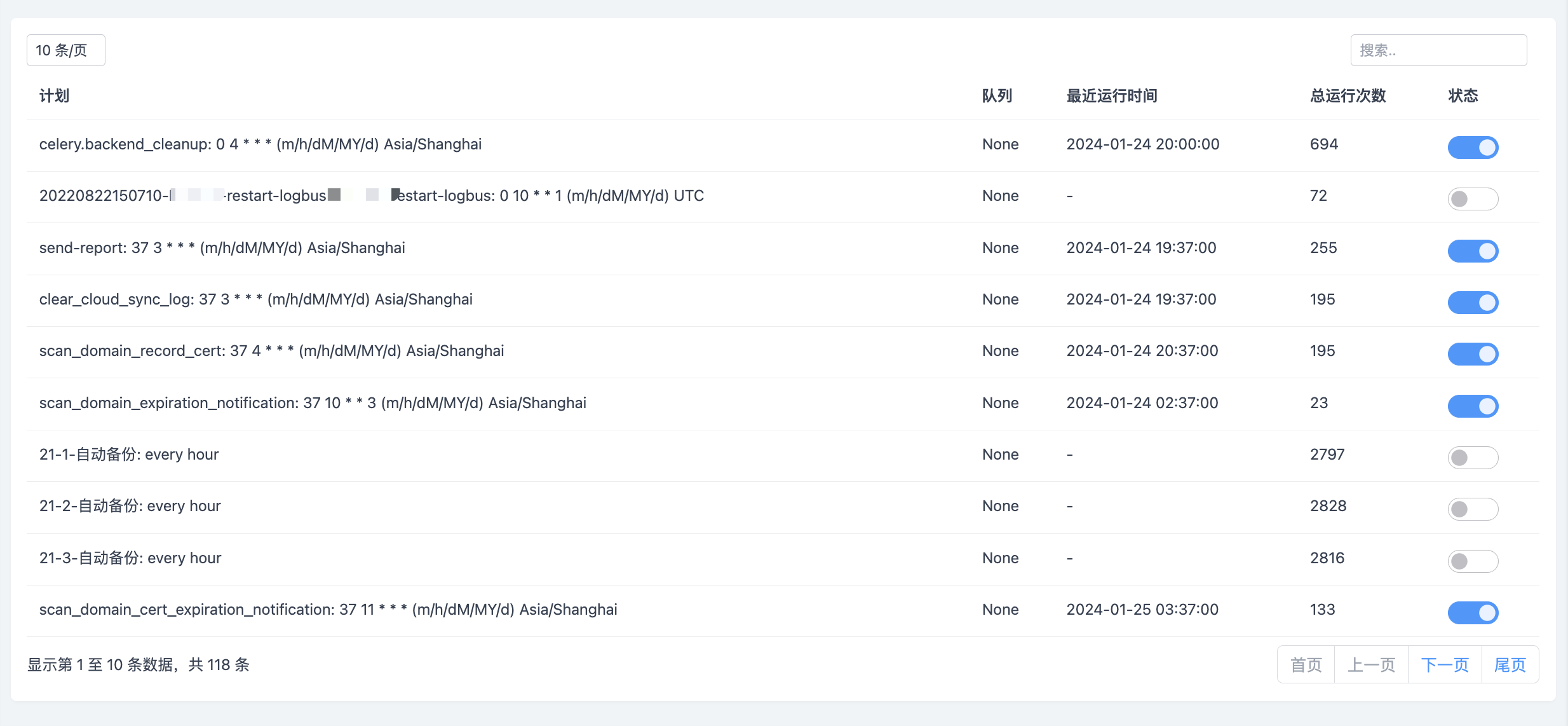
inspect更关注Celery的Worker运行情况,而AsyncResult则更关注于Celery的任务运行状态,通过两者的配合就能更好的掌握周期/定时/异步任务的执行情况了,通过监控功能的开发也对Celery有了更深的了解,同时运维自动化平台也变得更加完善
监控Celery不一定非要使用Flower的更多相关文章
- LoadRunner添加Weblogic监控的注意事项(非单纯的操作步骤)
LoadRunner添加Weblogic监控的注意事项(非单纯的操作步骤) 关于LR如何监控Weblogic(JMX方式)的操作就不在这里多说了,帮助文件和网上的介绍已经非常多了,关键是对各操作步 ...
- Celery&Flower文档笔记
1.Celery # tasks.py from celery import Celery app = Celery('tasks', broker='redis://localhost:6379', ...
- 线程池的介绍和使用,以及基于jvmti设计非入侵监控
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 五常大米好吃! 哈哈哈,是不你总买五常大米,其实五常和榆树是挨着的,榆树大米也好吃, ...
- Django分布式任务队列celery的实践
不使用数据库作为 Broker Broker 的选择大致有消息队列和数据库两种,这里建议尽量避免使用数据库作为 Broker,除非你的业务系统足够简单.在并发量很高的复杂系统中,大量 Workers ...
- celery最佳体验
目录 目录 不使用数据库作为 Broker 不要过分关注任务结果 实现优先级任务 应用 Worker 并发池的动态扩展 应用任务预取数 保持任务的幂等性 应用任务超时限制 善用任务工作流 合理应用 a ...
- 分布式消息队列 Celery 的最佳实践
目录 目录 不使用数据库作为 Broker 不要过分关注任务结果 实现优先级任务 应用 Worker 并发池的动态扩展 应用任务预取数 保持任务的幂等性 应用任务超时限制 善用任务工作流 合理应用 a ...
- celery最佳实践
作为一个Celery使用重度用户.看到Celery Best Practices这篇文章.不由得菊花一紧. 干脆翻译出来,同一时候也会添加我们项目中celery的实战经验. 至于Celery为何物,看 ...
- Celery 源码解析六:Events 的实现
在 Celery 中,除了远程控制之外,还有一个元素可以让我们对分布式中的任务的状态有所掌控,而且从实际意义上来说,这个元素对 Celery 更为重要,这就是在本文中将要说到的 Event. 在 Ce ...
- 定时任务调度-Celery
确保任务不重叠解决方法: from celery import task from celery.five import monotonic from celery.utils.log import ...
- Celery+python+redis异步执行定时任务
我之前的一篇文章中写了[Celery+django+redis异步执行任务] 博文:http://blog.csdn.net/apple9005/article/details/54236212 你会 ...
随机推荐
- Tomcat--安装&&配置文件
配置信息 centos:7.8 tomcat:7.0.3 jdk:1.8 1 部署java环境 [root@localhost ~]# tar xvf jdk-8u181-linux-x64.tar. ...
- AtCoder Beginner Contest 182 Person Editorial
Problem A - twiblr 直接输出 \(2A + 100 - B\) Problem B - Almost GCD 这里暴力枚举即可 int main() { ios_base::sync ...
- 2016年第七届蓝桥杯【C++省赛B组】
第一题:煤球数目 有一堆煤球,堆成三角棱锥形.具体: 第一层放1个, 第二层3个(排列成三角形), 第三层6个(排列成三角形), 第四层10个(排列成三角形), .... 如果一共有100层,共有多少 ...
- px2vw一个px单位转成vw单位的VSCode插件
px2vw 一个 px 单位转成 vw 单位的 VSCode 插件
- paddlespeech on centos7
概述 paddlespeech是百度飞桨平台的开源工具包,主要用于语音和音频的分析处理,其中包含多个可选模型,提供语音识别.语音合成.说话人验证.关键词识别.音频分类和语音翻译等功能. paddles ...
- C#商品金额大小写转换
见图 代码如下 public string NumToChinese(string x) { //数字转换为中文后的数组 string[] P_array_num = new string[] { & ...
- APB Slave状态机设计
`timescale 1ns/1ps `define DATAWIDTH 32 `define ADDRWIDTH 8 `define IDLE 2'b00 `define W_ENABLE 2'b0 ...
- 【BAT】递归替换文件后缀
@echo off set /p src_suffix=please input origin suffix: set /p des_suffix=please input target suffix ...
- Redis内存问题的学习之一
Redis内存问题的学习之一 背景 前几天帮同事看redis的问题 发现info memory 显示 60GB 但是实际上 save出来的dump文件只有 800M 然后导入到其他的redis之后, ...
- [转帖]Percolator - 分布式事务的理解与分析
https://zhuanlan.zhihu.com/p/261115166 Percolator - 分布式事务的理解与分析 概述 一个web页面能不能被Google搜索到,取决于它是否被Googl ...