lec-4-Introduction to Reinforcement Learning
模仿学习imitation learning与RL的不同
- 模仿学习中需要有专家指导的信息
- RL不需要访问专家信息
RL Definitions
- 奖励函数
- 马尔科夫决策链
- 只与上一个状态有关
- 目的
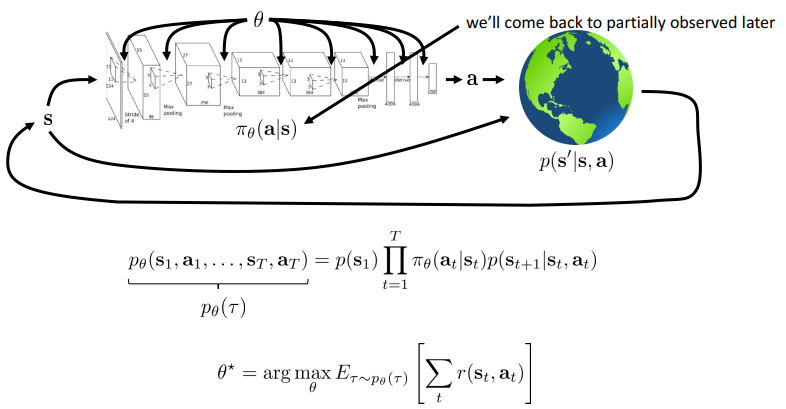
- 空间
- 有限
- 可找到最优参数
- 无限
- 证明p的概率分布是个平稳分布stationary distribution
- 有限
- 期望
- 由于奖励函数是不平滑的
- 转换: 但是可以优化 看似不平滑甚至稀疏的奖励功能(不平滑or不可微的期望) 在可微且平稳的概率下的函数
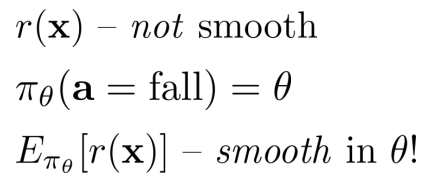
- 转换: 但是可以优化 看似不平滑甚至稀疏的奖励功能(不平滑or不可微的期望) 在可微且平稳的概率下的函数
- 由于奖励函数是不平滑的
算法
基本过程:
- 生成样本→调整模型/估计回报(评估policy)→提升策略policy→生成样本
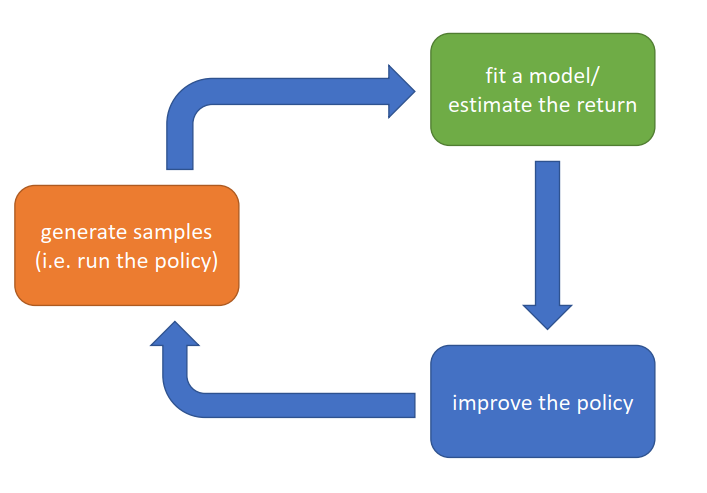
- 各部分代价
- 生成样本
Expensive:真实环境进行一次,也许代价会很高,机器人、车、电网等
cheap:模拟环境 - 评估policy
expensive:学习神经网络大量参数
cheap:MC等求均值等 - 提升policy
expensive:反向传播大量参数求导
cheap:回报均值梯度求导更新
- 生成样本
- 生成样本→调整模型/估计回报(评估policy)→提升策略policy→生成样本
Value Functions(基于值的)
- 核心:第二步(评估policy)使用Q-function or value function
- 定义
- 期望:
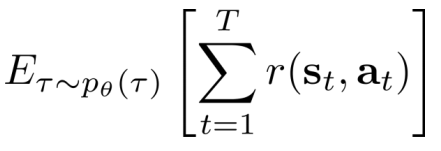
- Q-function:
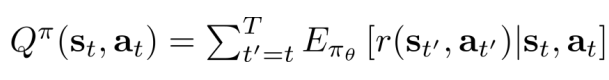
- Value function:
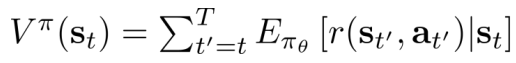
- 关系:
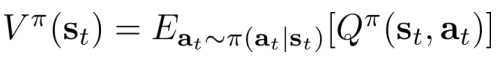
- Idea:
Policy iteration:Policy+Q-function → improve policy
比较QandV,if Q>V, 计算梯度增加动作概率
- 期望:
算法类型
- Policy gradients
- Value-based:拟合/评估Q、V
- Actor-critic
- Model-based RL:重点在提升policy上
算法的tradeoffs(权衡)→以至于出现如此多算法

Sample efficiency
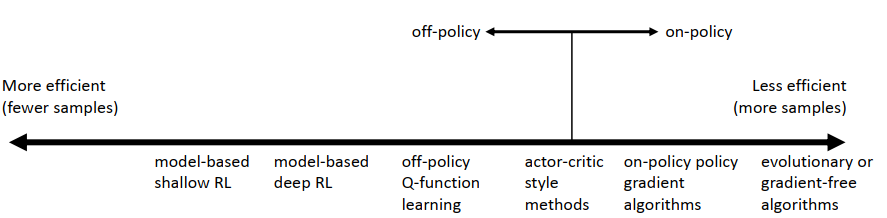
Stability and ease of use
- 值函数拟合:定点迭代
- 深度网络不能保证收敛性
- 基于模型的
- 收敛but不能保证model=better policy
- 策略梯度
- 只有一个在真正的目标上执行梯度下降(上升)的
- 值函数拟合:定点迭代
各类算法

Resource:CS285官网资料
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权:转载或者引用本文内容请注明来源及原作者
lec-4-Introduction to Reinforcement Learning的更多相关文章
- Ⅰ Introduction to Reinforcement Learning
Dictum: To spark, often burst in hard stone. -- William Liebknecht 强化学习(Reinforcement Learning)是模仿人 ...
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- 强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习, ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
随机推荐
- windows下使用route添加路由
1,首先在"运行"窗口输入cmd(按WIN+R打开运行窗口),然后回车进入命令行. 2,在命令行下输入route命令,会有对应的提示信息. ROUTE [-f] [-p] [-4| ...
- Androidstudio连接SQLite数据库报错not such table的相关解决
错误展示 明明就是按照创建第一个表的步骤来的,然后就是死活创建不出来第二张表,离谱啊家人们! 错误解决 针对于这个错误,只需要在SQLite类里面,将其中的version变量的值更改为更高版本即可: ...
- Sql 注入方案合集
[以mysql 数据库为例] [参考书目:sqlilabs过关手册注入天书 https://www.cnblogs.com/lcamry/category/846064.html] 推荐看原书,这篇文 ...
- SQL注入,Hacker入侵数据是如何做到的
什么是SQL注入? SQL注入就是未将代码与数据进行严格的隔离,导致在读取用户数据的时候,错误地把黑客注入的数据作为代码的一部分执行. SQL注入自诞生以来以其巨大的杀伤力闻名. 例子: 典型的SQL ...
- 当transcational遇上synchronized
工作当中经常会遇到既需要开启事务管理,同时也需要同步保证线程安全的场景. 比如一个方法 @Transactional public synchronized void test(){ // } 不知道 ...
- 必知必会的 WebSocket 协议
文章介绍 WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它的出现使客户端和服务器之间的数据交换变得更加简单.WebSocket 通常被应用在实时性要求较高的场景,例如赛事数据. ...
- Flutter 异步编程指南
作者:京东物流 王志明 1 Dart 中的事件循环模型 在 App 开发中,经常会遇到处理异步任务的场景,如网络请求.读写文件等.Android.iOS 使用的是多线程,而在 Flutter 中为单线 ...
- vue之过滤、筛选功能的实现
目录 需求 代码 需求 给定一个列表(模拟数据),根据用户输入,自动筛选输入的内容并输出到屏幕 代码 <!DOCTYPE html> <html lang="en" ...
- pychearm日常用法
一 常用快捷键 编辑类:Ctrl + D 复制选定的区域或行Ctrl + Y 删除选定的行Ctrl + Alt + L 代码格式化Ctrl + Al ...
- [VMware]虚拟网络编辑器
虚拟网络编辑器 Vmware > 编辑 > 虚拟网络编辑器 VMnet0 VMnet0:用于虚拟桥接模式网络下的虚拟交换机 vmnet0: 实际上就是一个虚拟的网桥 这个网桥有很若干个端口 ...