LOTO示波器的变长存储深度和分段存储
LOTO示波器的变长存储深度和分段存储
经常有客户咨询和不理解LOTO示波器的存储深度为什么是变长的,也表示对LOTO示波器的分段存储功能不理解,本文对LOTO示波器的存储机制做一次完整的梳理,帮助我们的客户更好的使用示波器。
数字示波器都是有死区时间(Dead-time)的,如下图所示,在两次采集时间段 (Acquisition-time)之间,一定会存在一个没有采集到的死区时间,在死区时间内的信号波形是采集和显示不到的。
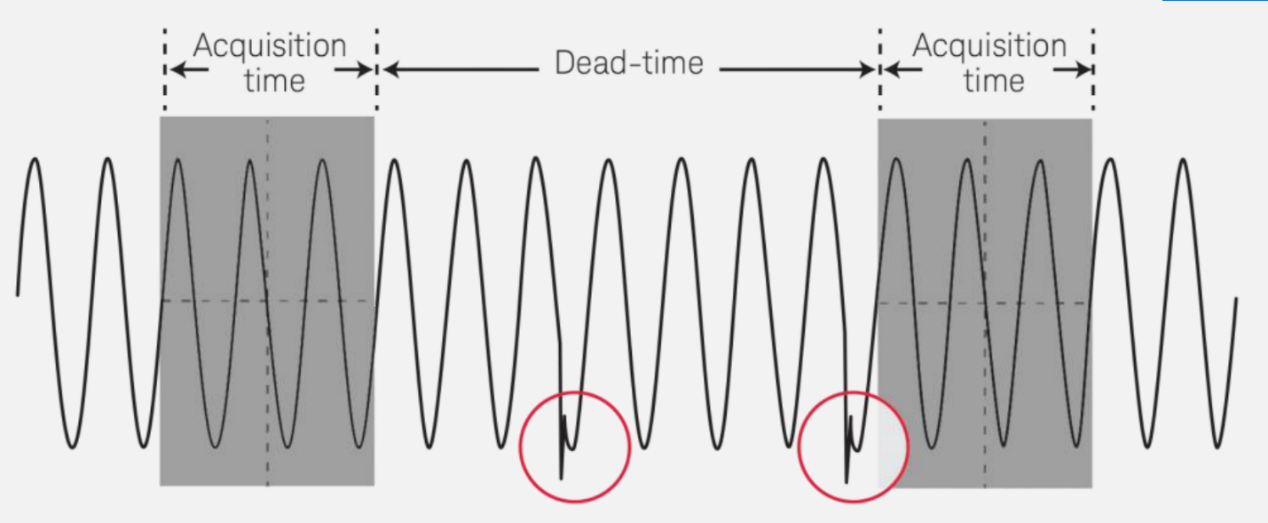
所以示波器厂家都在尽力缩短死区时间段,加长采集时间段(上图灰色部分)。但是死区时间段不可能无限制缩小,采集时间段也不能无限制增大,这两种做法都需要在产品的实际使用中做出权衡。
降低采样率或者加大存储深度,是加长采集时间段的两种常用方法。大的存储深度可以保障示波器用尽可能高的采样率一次采集尽可能长时间段的波形,但是并不能消除死区时间段,较大存储会降低处理和波形捕获率。这会降低示波器的响应速率,并增加每次采集间隔的停滞时间。降低采样率的方法,使得存储数据点数减少,有利于提高波形的捕获速率和波形刷新率,缺点是采样率降低到一定程度会造成每个波形周期的采样点数不足,引起失真。
高端示波器还有第三种方法:分段存储功能。分段存储功能将存储划分为较小分段。用户可以指定存储应被划分为几个分段,每个分段均具备同等长度。
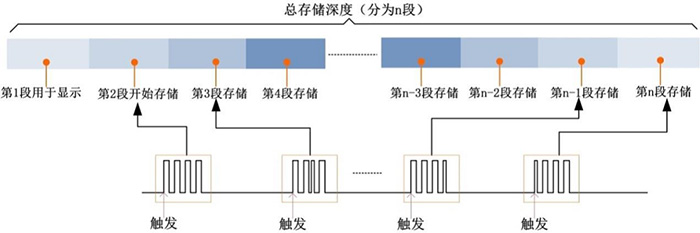
当示波器观察到第一个触发事件时,会开始在采集存储的第一个分段中存储采样点,直至第一个分段存储满。之后示波器会重新做好触发准备,开始寻找下一个出现的触发事件。当触发事件发生时,示波器会在下一个存储分段中存储采样点。示波器会不断重复这一过程,直至所有存储分段均存储满。 在捕获停滞时间较长的突发信号时,分段存储模式尤其有用。许多串行总线和通信信号均属于此类信号。通过分段存储,示波器可以维持高采样率,同时捕获长达数分钟数小时或数天。
LOTO示波器为OSCA02及更高型号的产品提供了多种灵活的存储方式,对产品的性能做出了权衡和兼顾,既可以小存储深度快速刷新,保持高的波形更新速率,又可以设置成长时间采集模式连续采集,还可以进行分段存储。
我们来逐个功能介绍:
1 示波器模式:
大部分客户的大部分应用场景下,应选择LOTO示波器的示波器模式,这也是我们软件的默认模式。这种模式优先使用固定的128K的存储深度,从而保障波形的快速更新和显示及运算。
这种模式下,客户可以自行调整波形刷新的帧率。也可以自由设置触发方式和位置,并得到快速的波形响应。
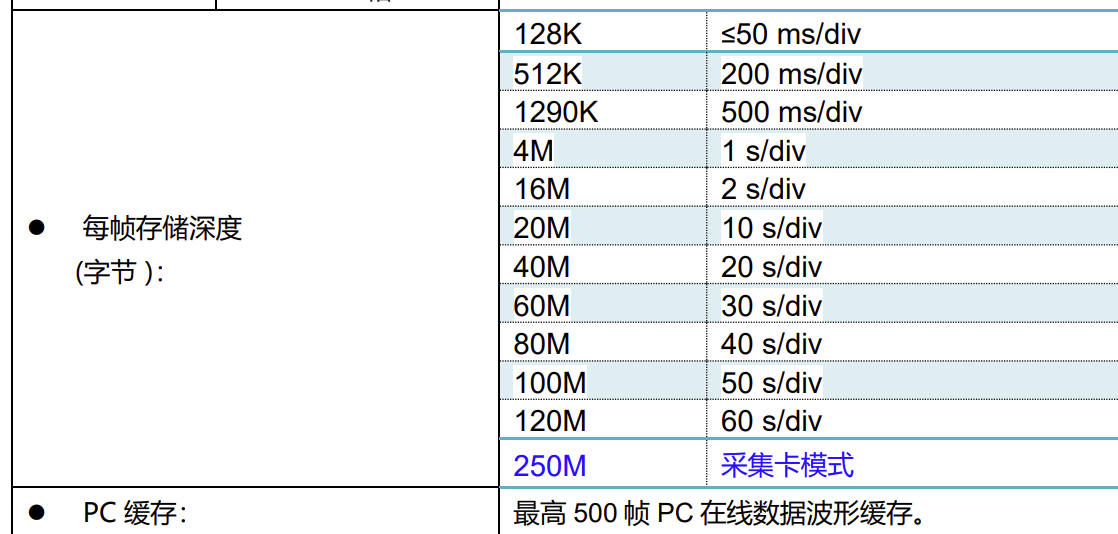
在示波器模式下,客户不需要考虑采样率和存储深度,只需要考虑当前屏幕显示的时间跨度,也就是时间档位就可以。示波器会根据当前的时间档位自动调整采样率和存储深度达到最合适的效果,兼顾效率和准确。所以LOTO示波器的存储深度是变长的。
在这个模式下,LOTO示波器还提供了500帧的PC缓存功能,还提供了余晖功能。这两个功能记录多帧的数据和波形,分别横向排开显示以及垂直叠加显示。相当于500个当前存储深度的存储,比如当前是128K的存储深度的话,打开PC缓存功能相当于60M的深度了。并且这些数据可以导出到电脑文件,也可以导入到LOTO示波器的软件中重现出波形进行分析,也可以逐帧导出成文本文件或者电子表格文件。
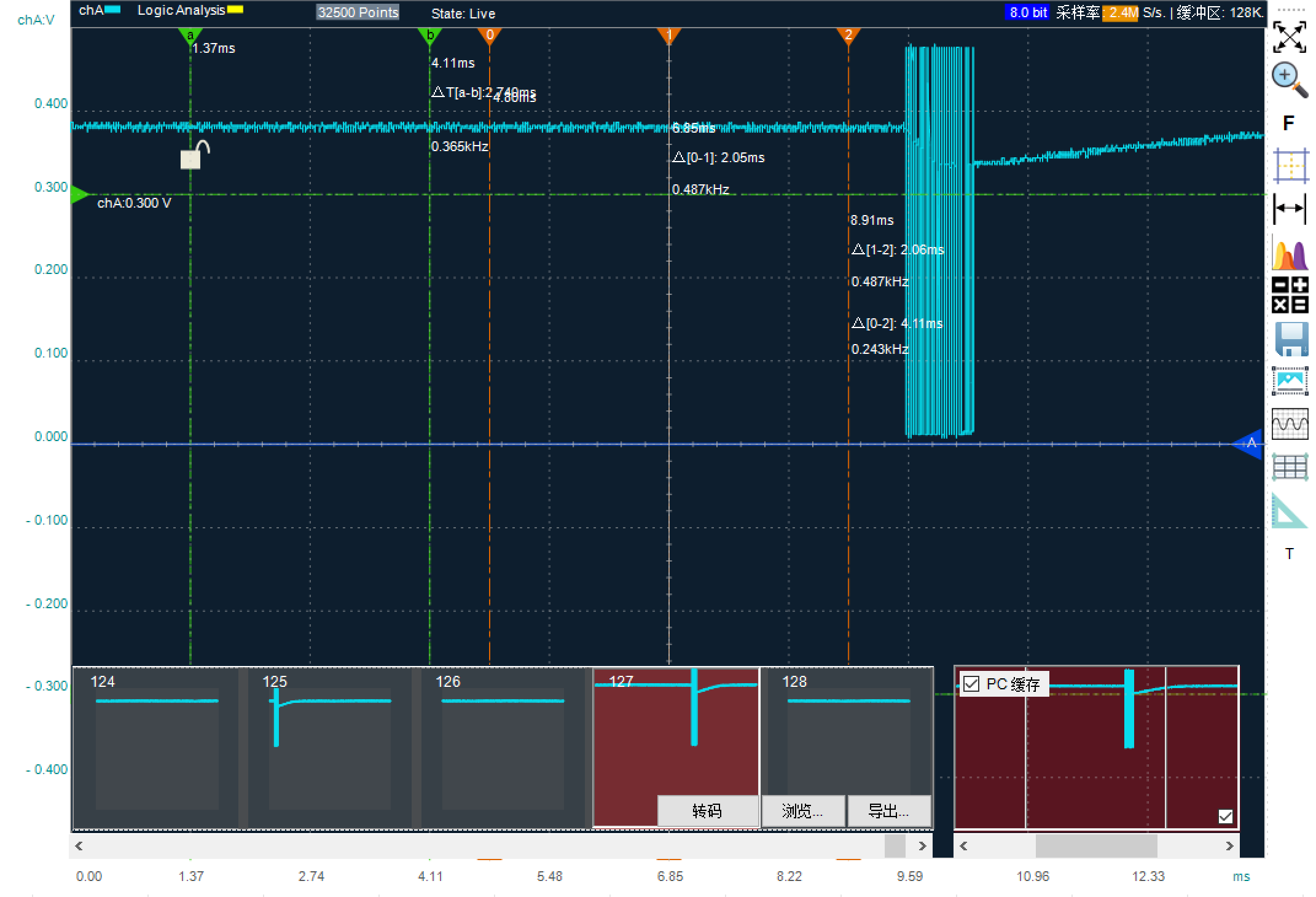
这500个存储深度之间仍然是有死区时间的,采用高的波形刷新速率时,这个功能可以极大提高异常波形的发现概率。这就有点像下一个模式分段存储模式了,我们后面介绍。
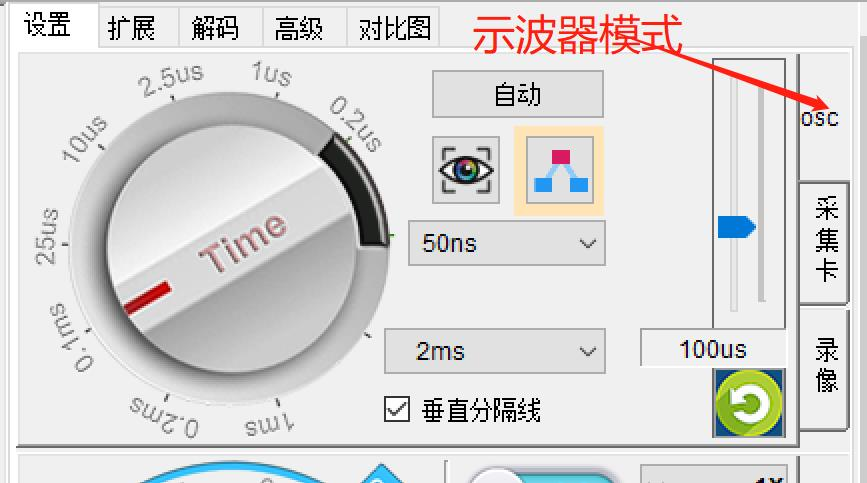
2 采集卡模式(传统长存储模式):
LOTO示波器可以选择将示波器模式切换为采集卡模式,如下图所示:
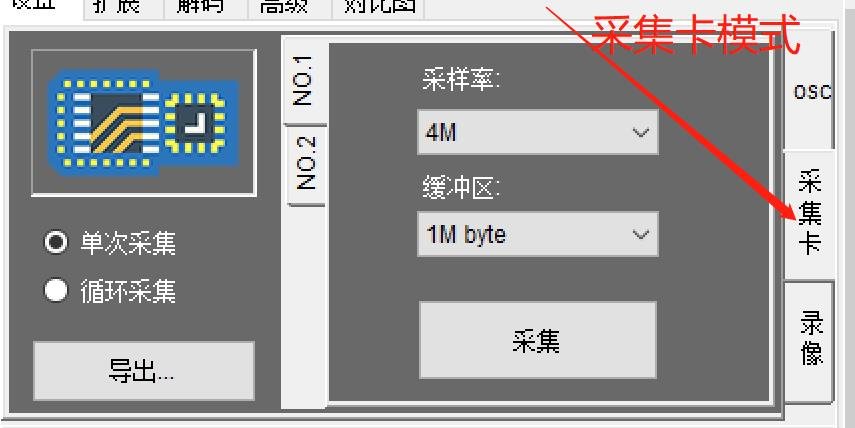
,
这个模式下,客户手动选择采样率,以及选择适合的缓冲区(相当于存储深度)大小进行采集。选择好之后点击采集,就开始持续长时间采集,直到填满整个选定的缓冲区。缓冲区最长可以设定为250兆字节,如果是双通道采集,那么整个采集过程所需要的时间为缓冲区大小除以2再除以采样率。比如,使用2.4M采样率,缓冲区为250M,采集1KHZ的正弦波,那么会持续采集60秒,大约1分钟的波形数据并绘制在屏幕上,采集过程中会显得很卡顿,设置长时间不更新波形,会有进行中的指示标识:
需要耐心等待采集结束,结束后如下图所示。
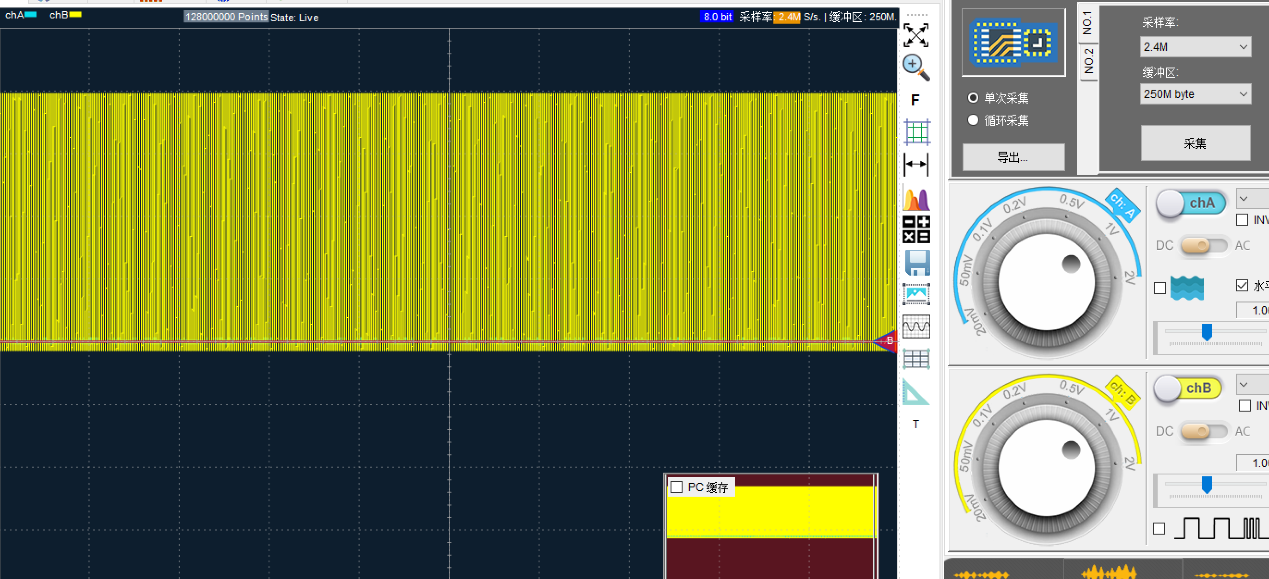
这样1分钟的数据放在屏幕上,多数情况下会显得非常密集,比如图上就有6万多个周期的波形,我们可以放大了逐个观察分析一般凭借肉眼和工程师耐心,人最多看不超过1000个周期就崩溃,也就是说你可查看的最大波形周期是1000个,也就是千分之一的概率,对于1ppm的异常,肯定无法看到。现在可以按照条件搜索,但是条件呢?是脉冲,还是边沿缺陷,还是过冲?你无法预知,也就无法搜索,按照各种条件搜索,需要花费不少时间,也会出差错。有些情况下,使用模式1的示波器模式快速刷新波形,一旦看到波形异常闪过,可以立刻停下采集,在过去的500帧缓存里面找到它。
长存储会带来计算处理要求的提高,如果同样的处理器,数据多了处理时间会变长,波形捕获率就会变得非常慢。为了方便这种长时间大数据量的采集后期分析,我们可以把采集到的数据导出成数据文件,如下图所示:
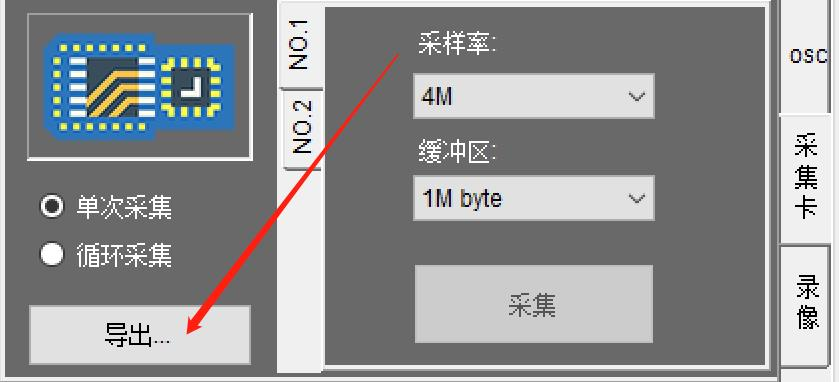
然后在1示波器模式下导入进来,变成500帧的分段波形,总数据量是250M字节,可以方便的逐一查看分析,如下图所示:
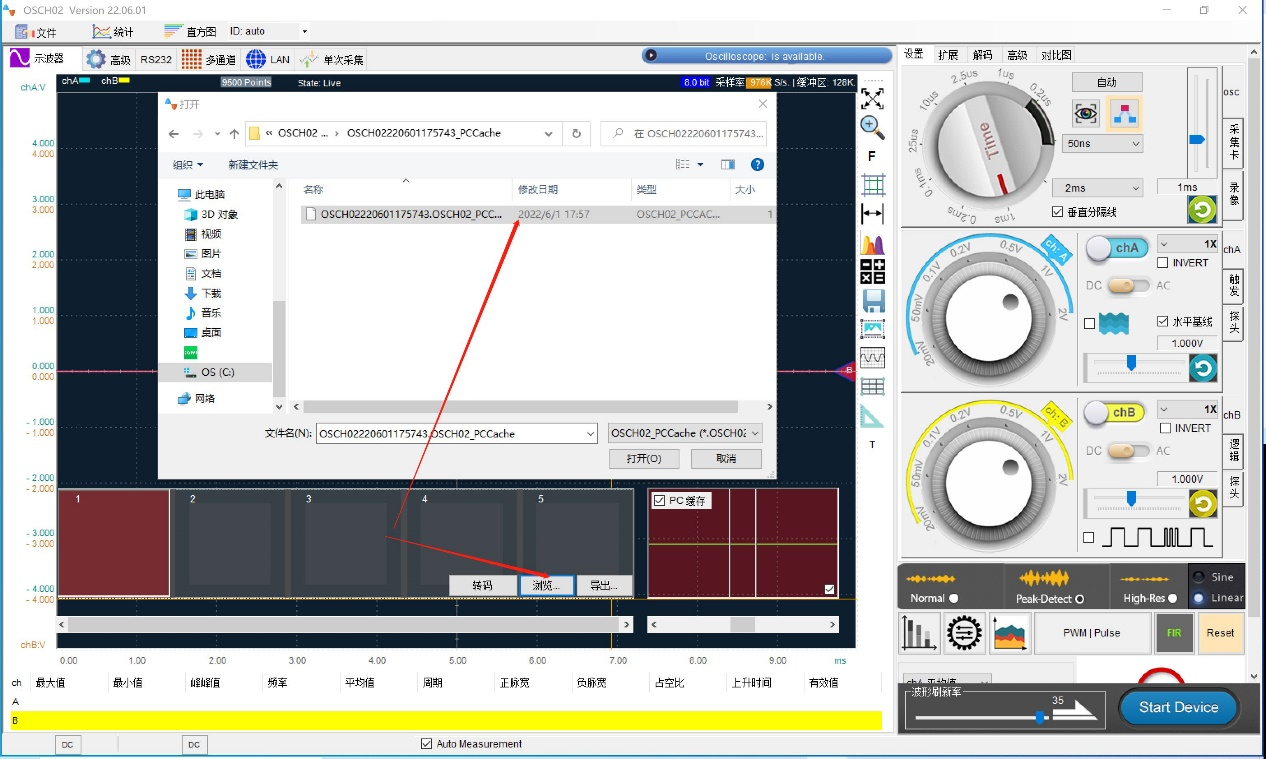
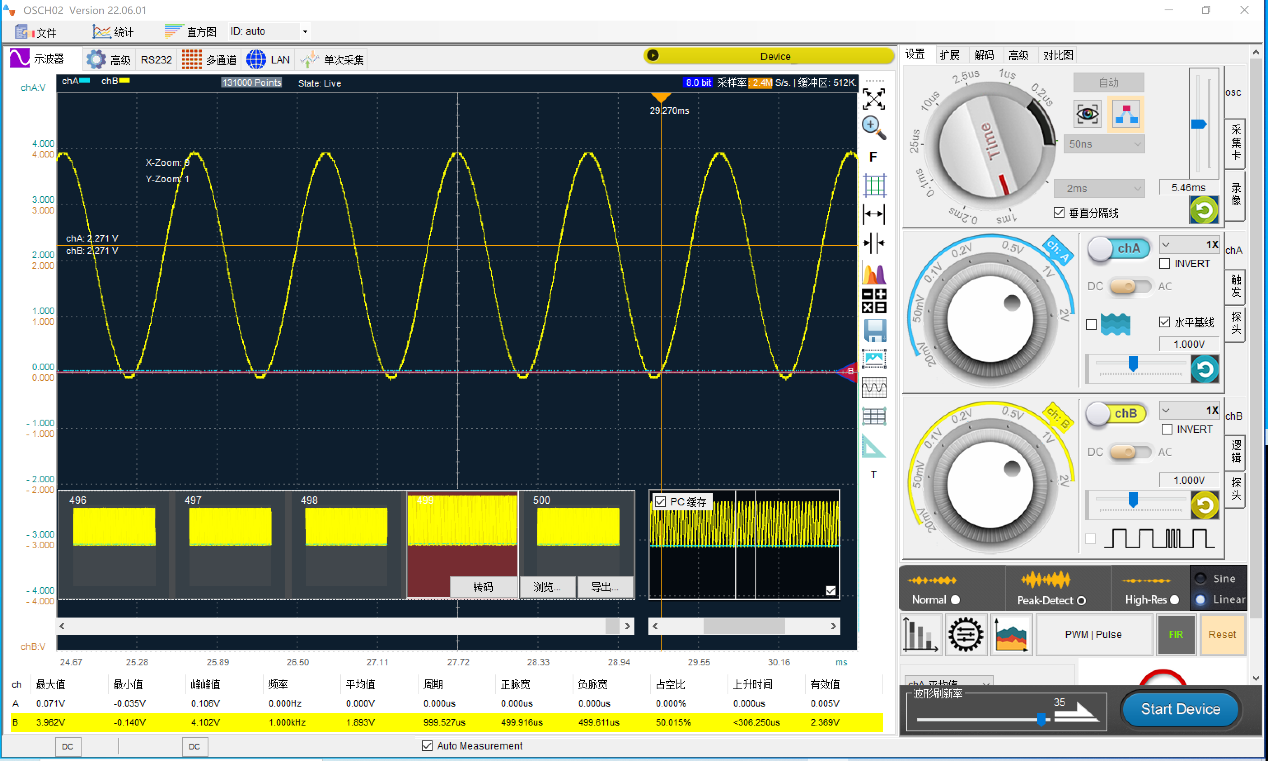
如上图所示,LOTO示波器这样的设计兼顾了长时间采集的优点,又尽量弥补了后续分析查看的不便。LOTO示波器不但可以将采集卡模式使用在2通道示波器模拟信号输入情况下,也可以使用在双通道合并采集的情况下,也可以使用在逻辑分析仪数字通道输入的情况下,并且都可以导出文件并导入到PC缓存里分段分析。一旦导入到PC缓存里,就可以重现出波形进行分析,也可以逐帧导出成文本文件或者电子表格文件。
3 分段存储模式:
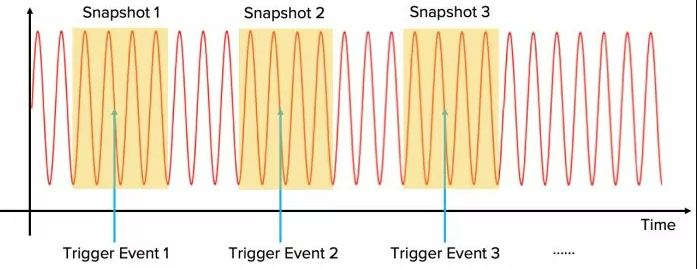
在前面提到过,在示波器模式下,开启PC缓存功能,基本上就相当于有了500段的分段存储能力了。这种分段存储模式有一个特别典型的应用场景:低占空比脉冲或猝发信号。信号与信号之间有较长的空闲时间,很多情况下,即使有较大的存储,或者通过降低采样率的方式也很难达到想要的采集时长,想象一下,一天之内可能出现100次,每次出现的信号很尖锐很短促需要很高的采样率去抓取,示波器有再大的存储也不可能存储一天数据,采样率降的再低也不可能抓到所有的100次信号,而分段存储却可以很好的完成。
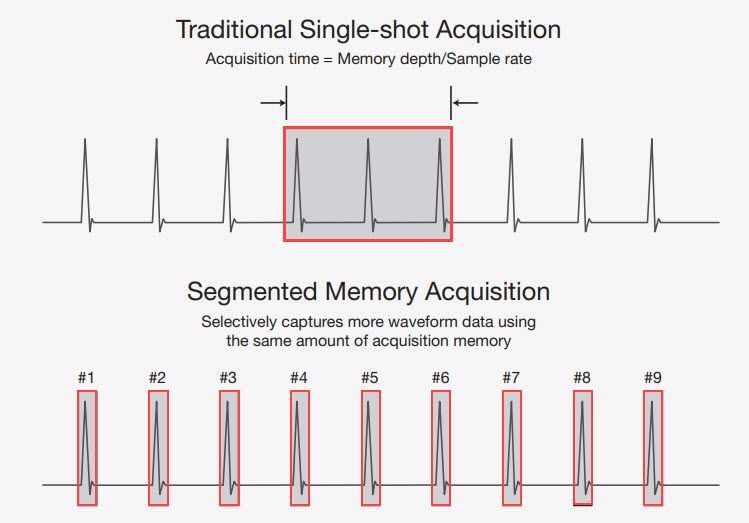
如上图所示,分段存储在高采样率采集过程中进行多次触发,对每次触发采样得到的数据存放到将存储空间分成的一段一段小的存储中。示波器触发一次填充一个段,段与段之间的空闲信号或信号不感兴趣的部分没有被采集和存储。
还有一种常见的场景特别适合分段存储功能发挥独特作用的是串行总线分析——串行总线以数据包的方式进行传输,包与包之间空闲时间会占用示波器宝贵的存储资源,采用分段存储,示波器可以只采集数据包,空闲时间不采样。在保持较高采样率下,还可以采集较多的数椐包,方便解码分析。接下来我么看一个LOTO示波器使用分段存储采集和解码这样的串行总线的案例。
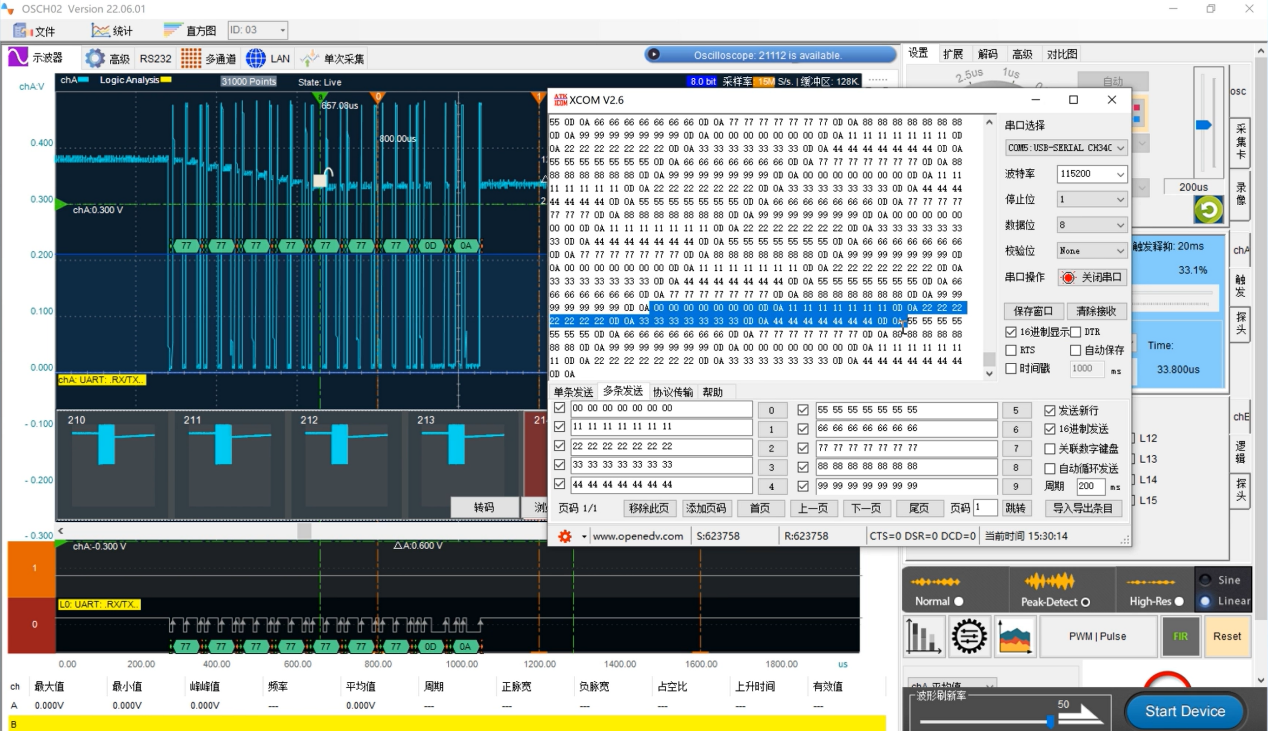
如上图所示,串口RS232每隔200ms(如果要效果更明显可以设置更长,比如1分钟间隔)会发送一串数字,0000000一直到999999999并且循环发送。我们开始触发和500帧的PC缓存功能作为分段存储。
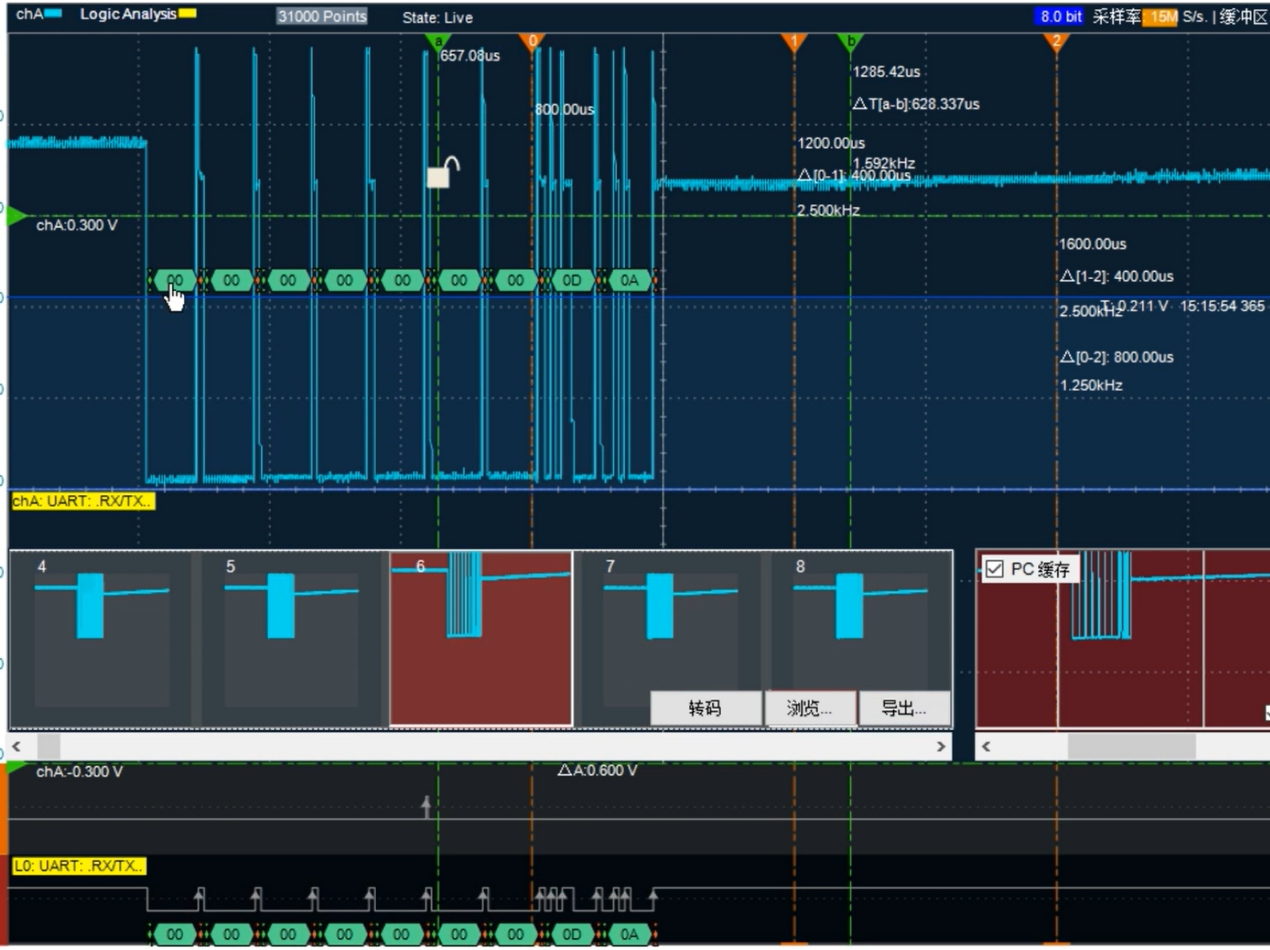
我们看到上图所示,分段存储的第6帧,数据是0000000,并且解码出来了。下图第7帧,数据是1111111,并且解码出来了。
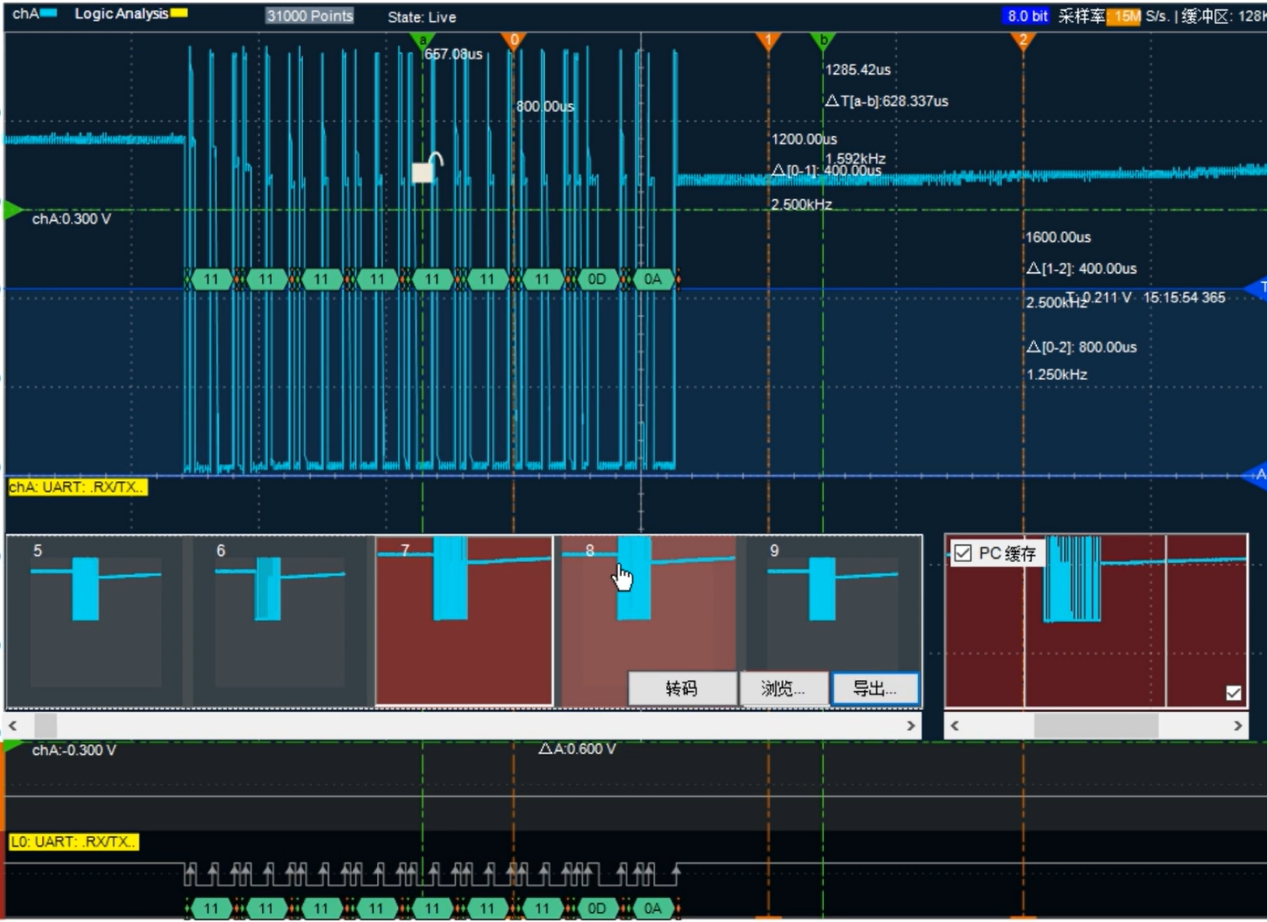
下图分段存储的第8帧,数据是2222222,并且解码出来了…
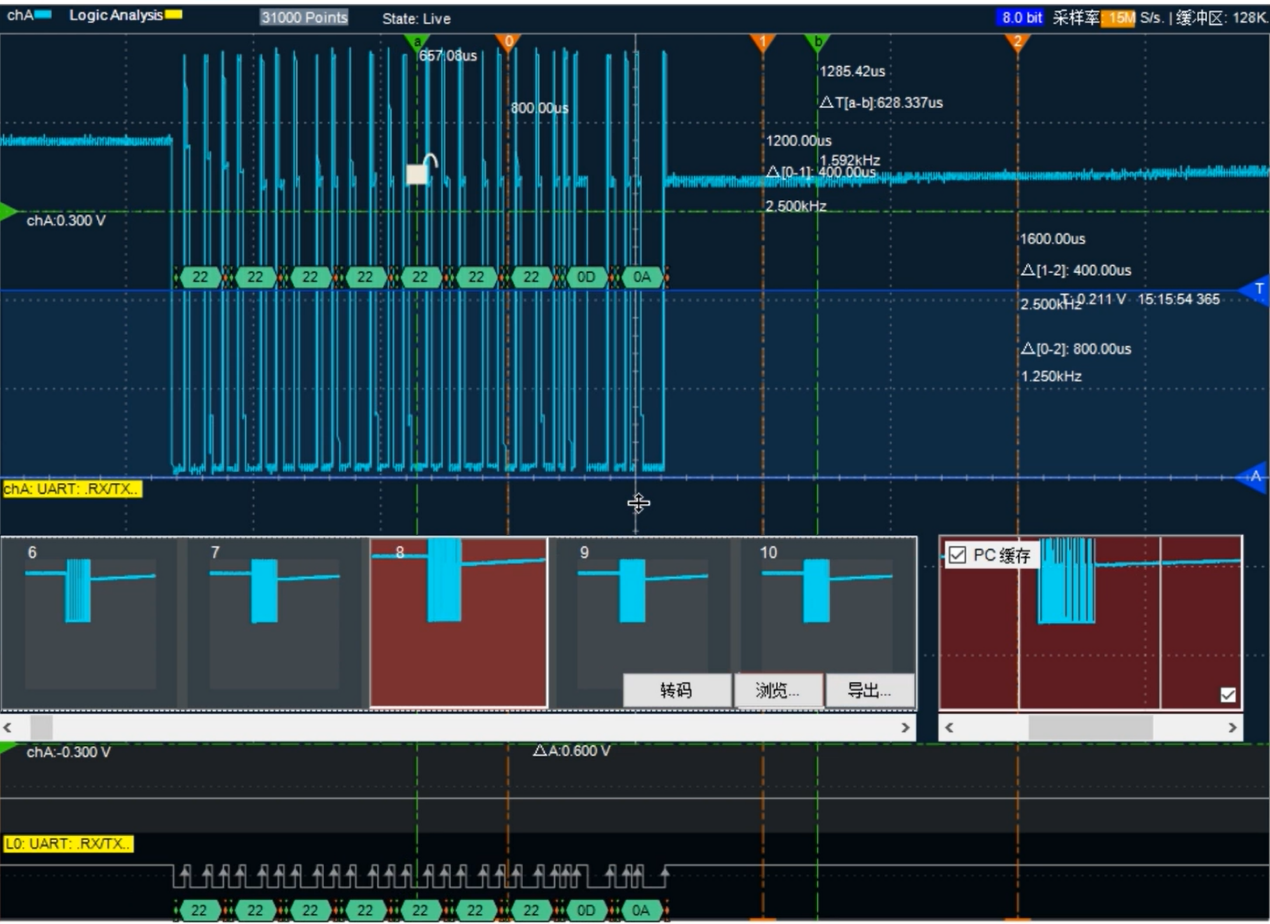
这样一直到最后,每帧被捕获一个数据包,并且解码出来,一直可以捕获500帧不遗漏,不论整个发送过程如何漫长。
LOTO示波器的变长存储深度和分段存储的更多相关文章
- C99中的变长数组(VLA)
处理二维数组的函数有一处可能不太容易理解,数组的行可以在函数调用的时候传递,但是数组的列却只能被预置在函数内部.例如下面这样的定义: #define COLS 4 int sum3d(int ar[] ...
- C99新增内容之变长数组(VLA)
我们在使用多维数组是有一点,任何情况下只能省略第一维的长度.比如在函数中要传一个数组时,数组的行可以在函数调用时传递,当属数组的列却只能在能被预置在函数内部.看下面一个例子: #define COLS ...
- 变长数组(variable-length array,VLA)(C99)
处理二维数组的函数有一处可能不太容易理解,数组的行可以在函数调用的时候传递,但是数组的列却只能被预置在函数内部.例如下面这样的定义: #define COLS 4 int sum3d(int ar[] ...
- SQL Server如何在变长列上存储索引
这篇文章我想谈下SQL Server如何在变长列上存储索引.首先我们创建一个包含变长列的表,在上面定义主键,即在上面定义了聚集索引,然后往里面插入80000条记录: -- Create a new t ...
- mysql变成类型字段varchar值更新变长或变短底层文件存储原理
为了搞清楚MySQL对于可变长度字段值修改时,如何高效操作数据文件的机制.之前一直模糊不清,网上也搜不到现成的答案.经过多方资料搜集整理.写出此文供大家一起参阅.由于涉及众多非常底层的知识,我假设读者 ...
- [转帖]深度: NVMe SSD存储性能有哪些影响因素?
深度: NVMe SSD存储性能有哪些影响因素? http://www.itpub.net/2019/07/17/2434/ 之前有一个误解 不明白NVME 到底如何在队列深度大的情况下来提高性能, ...
- C++中的变长参数
新参与的项目中,为了使用共享内存和自定义内存池,我们自己定义了MemNew函数,且在函数内部对于非pod类型自动执行构造函数.在需要的地方调用自定义的MemNew函数.这样就带来一个问题,使用stl的 ...
- 报文格式:xml 、定长报文、变长报文
目前接触到的报文格式有三种:xml .定长报文.变长报文 . 此处只做简单介绍,日后应该会深入学习到三者之间如何解析,再继续更新.——2016.9.23 XML XML 被设计用来传输和存储数据. H ...
- C++内存分配及变长数组的动态分配
//------------------------------------------------------------------------------------------------ 第 ...
- C99新特性:变长数组(VLA)
C99标准引入了变长数组,它允许使用变量定义数组各维.例如您可以使用下面的声明: ; ; double sales[rows][cols]; // 一个变长数组(VLA) 变长数组有一些限制,它必须是 ...
随机推荐
- NC210520 Min酱要旅行
题目链接 题目 题目描述 从前有个富帅叫做Min酱,他很喜欢出门旅行,每次出门旅行,他会准备很大一个包裹以及一大堆东西,然后尝试各种方案去塞满它. 然而每次出门前,Min酱都会有个小小的烦恼.众所周知 ...
- 轻松玩转makefile | 变量与模式
前言 本文通过简单的几个示例,以及对同一个Makefile进行几个版本的迭代,帮助快速的理解变量和模式规则的使用. 1.回顾 在上一篇文章中,我们使用Makefile编译fun.c和main.c这两个 ...
- 【Unity3D】水波特效
1 水波特效原理 水面特效 中基于 Shader Graph 实现了模拟水面特效,包含波纹.起伏.折射.泡沫等细节,本文将基于屏幕后处理实现环形水波特效. 水波特效属于 Unity3D 后处理 ...
- pymysql基本语法,sql注入攻击,python操作pymysql,数据库导入导出及恢复数据---day38
1.pymysql基本语法 # ### python操作mysql import pymysql ''' # ### 1.基本语法 #(1) 创建连接 host user password datab ...
- jupyterlab安装和优化
说明 JupyterLab(官网https://jupyter.org)是一个交互式的代码编辑器,打开它会打开一个网页,可以在其中编写代码,即时执行,快速得到结果(包括代码返回值.统计图和界面交互图) ...
- 基于Vue(提供Vue2/Vue3版本)和.Net Core前后端分离、强大、跨平台的快速开发框架
前言 今天大姚给大家推荐一款基于Vue(提供Vue2/Vue3版本)和.Net Core前后端分离.开源免费(MIT License).强大.跨平台的快速开发框架,并且框架内置代码生成器(解决重复性工 ...
- 前后端分离项目(七):实现"添加"功能(前端视图)
好家伙,本篇用于测试"添加"接口,为后续"用户注册"功能做铺垫 (完整代码在最后) 我们要实现"添加"功能 老样子我们先来理清一下思路, ...
- mongo重启、远程连接
1.查看当前mongo启动进程 ps -ef | grep mongo 2.修改mongo启动远程连接配制文件 vi /etc/mongod.conf 将 bind_ip=127.0.0.1 这一行注 ...
- 【Azure Webjob + Redis】WebJob一直链接Azure Redis一直报错 Timeout Exception
问题描述 运行在App Service上的Webjob连接Azure Redis出现Timeout Exception. 错误截图: 参考Azure Redis对于超时问题的排查建议, 在修改Min ...
- 【Azure 存储服务】Azure Storage Account 下的 Table 查询的性能调优
问题描述 Azure Storage Account 下的 Table 查询的性能调优? 问题解答 因为Azure Storage Table服务(表服务) 与常规的关系型数据库不一样(例如:MySQ ...