mysql 重新整理——索引优化explain字段介绍一 [九]
前言
在七种介绍了explain这东西,那么具体来看下它是如何来运行的吧。
正文
id
来看一条语句:EXPLAIN select * from departments,dept_emp,employees

当id相同的时候:代表在同一队列里面加载,就是说他们加载不是并发的,而是有顺序的。
然后一个问题,就是说我们写的顺序是:departments,dept_emp,employees ,然後你看他们的加载顺序是:departments,employees ,dept_emp。
然后看另外一条语句:
explain SELECT * FROM temployees WHERE emp_no= (
SELECT dept_emp.emp_no
FROM dept_emp
WHERE dept_emp.dept_no=(
SELECT departments.dept_no
FROM departments
WHERE departments.dept_name="Finance"
)
)
在此注明,上面表的东西呢,是mysql 官方测试表。
那么看一下:
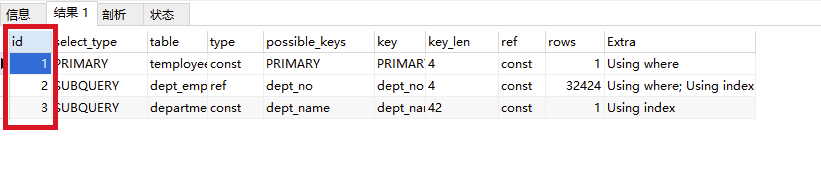
就算我们不看explain,其实我们也知道肯定是执行:departments,dept_emp,employees 。
所以是id越大越先执行。
总结一下:如果id相同,从上至下按照顺序执行,如果id不同,越大越先执行。
select_type
这个查询可以告诉我们到底是什么样的查询:
查询的类型,主要用于区别普通查询、联合查询、子查询等复杂的查询。
这里先列一下有哪些查询:
1.simple:简单的select,查询中不包含子查询或者union
2.primary:那个包含任何复杂的子查询,最外层查询则被标记为这个。
可以参考我前面这个图:
3.subquery:在select 或者 where 列表中包含子查询
4.derived 在from 中包含的子查询被标记为derived,mysql会递归执行这些子查询,把结果放在临时表中。
5.union,如果第二个select 出现在union之后,则会标记为union。
如果union 包含在from 子句中的子查询中,外层的select 被标记为:derived。
6.union result 从union获取结果的select。
table
table 就非常简单了,就是表。
后语
后面补齐。
mysql 重新整理——索引优化explain字段介绍一 [九]的更多相关文章
- MySQL中的索引优化
MySQL中的SQL的常见优化策略 MySQL中的索引优化 MySQL中的索引简介 过多的使用索引将会造成滥用.因此索引也会有它的缺点.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 ...
- MySql在建立索引优化时需要注意的问题
MySql在建立索引优化时需要注意的问题 设计好MySql的索引可以让你的数据库飞起来,大大的提高数据库效率.设计MySql索引的时候有一下几点注意: 1,创建索引 对于查询占主要的应用来说,索引显得 ...
- 一本彻底搞懂MySQL索引优化EXPLAIN百科全书
1.MySQL逻辑架构 日常在CURD的过程中,都避免不了跟数据库打交道,大多数业务都离不开数据库表的设计和SQL的编写,那如何让你编写的SQL语句性能更优呢? 先来整体看下MySQL逻辑架构图: M ...
- MySQL系列(六)--索引优化
在进行数据库查询的时候,索引是非常重要的,当然前提是达到一定的数据量.索引就像字典一样,通过偏旁部首来快速定位,而不是一页页 的慢慢找. 索引依赖存储引擎层实现,所以支持的索引类型和存储引擎相关,同一 ...
- mysql 高级和 索引优化,目的:查的好,查的快,性能好
1-事物隔离级别: 更新丢失, 并发情况下,对同一字段进行更新,就会出现更新丢失,采用乐观锁,比较版本号或时间戳可解决 读未提交 解决了更新丢失但是会引起脏读, 二个session.sessionA中 ...
- mysql 单表索引优化
建表语句 CREATE TABLE IF NOT EXISTS `article` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMEN ...
- 【MySQL 高级】索引优化分析
MySQL高级 索引优化分析 SQL 的效率问题 出现性能下降,SQL 执行慢,执行时间长,等待时间长等情况,可能的原因有: 查询语句写的不好 索引失效 单值索引:在 user 表中给 name 属性 ...
- MySQL如何利用索引优化ORDER BY排序语句
MySQL索引通常是被用于提高WHERE条件的数据行匹配或者执行联结操作时匹配其它表的数据行的搜索速度. MySQL也能利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作. 通 ...
- MySQL如何利用索引优化ORDER BY排序语句 【转载】
本文转载自:http://blog.csdn.net/ryb7899/article/details/5580624 .感谢相关作者. MySQL索引通常是被用于提高WHERE条件的数据行匹配或者执 ...
- MySQL如何利用索引优化ORDER BY排序语
MySQL索引通常是被用于提高WHERE条件的数据行匹配或者执行联结操作时匹配其它表的数据行的搜索速度. MySQL也能利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作. 通 ...
随机推荐
- Codeforces(1500板刷)
目录 写在前面 1. A. Did We Get Everything Covered?(构造.思维) 题目链接 题意 题解 代码 总结 2 F. Greetings(离散化+树状数组) 题目链接 题 ...
- 使用svgo-loader只对部分文件生效
svgo-loader配合svg-sprite-loader使用,网上教程很多,不赘述 const svgRule = config.module.rule("svg-sprite" ...
- 使用Servlet进行页面跳转的两种方式
最近在教学生学习JavaWeb相关的技术,刚好讲到Java当中的Servlet,一个服务端的小程序. 也在和学生讲使用Servlet如何进行页面跳转,一种方式是使用请求转发进行页面跳转,一种方式 是使 ...
- 接入移动手机号一键登录类的封装,app应用,php服务端类的封装与调用
需求:实现手机号一键登录,由于官方只有java的demo和jar包,没有php的sdk及demo <?php/* * 手机号一键登录加解密 */class Autophone{ const A_ ...
- stm32f103 实现LCD显示及分析
前记 stm32 f103 在很多物联网系统中,状态显示是一个很重要的部分,在配合其它的系统做物联网设备时候,有一个状态显示,不仅仅是显得高大上,并且能够让你的系统变得更加人性化,这对于做设备的来 ...
- day08-2-Thymeleaf
服务器渲染技术-Thymeleaf 1.基本介绍 官方在线文档:Read online 文档下载:Thymeleaf 3.1 PDF, EPUB, MOBI Thymeleaf 是什么 Thymele ...
- Google Chart API学习(一)
圆饼示例: <html> <head> <!--Load the AJAX API--> <script type="text/javascript ...
- window.showModalDialog与opener及returnValue
首先来看看 window.showModalDialog 的参数 vReturnValue = window.showModalDialog(sURL [, vArguments] [, sFeatu ...
- 一种OSD 简单实现 (文字反色---opencv、字体切换---freetype2(中文、空格))
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 喜讯!瑞云科技被授予“海上扬帆”5G融合应用专委会成员单位
2022年7月19日,5G应用"海上扬帆"行动计划云启航大会暨"海上扬帆"融合应用专委会成立大会在沪成功举办. 受上海信通院工创中心邀请和信任,深圳市瑞云科技有 ...