【论文阅读】Exploring the Limitations of Behavior Cloning for Autonomous Driving
Column: January 16, 2022 11:11 PM
Last edited time: January 21, 2022 12:23 PM
Sensor/组织: 1 RGB
Status: Finished
Summary: carla leaderboard的前身,首次提出 IL BC的几点问题 及较为简单的解决办法 实验结果证明较为有效
Type: ICCV
Year: 2019
引用量: 148
参考与前言
ICCV Open Source:
ICCV 2019 Open Access Repository
code: https://github.com/felipecode/coiltraine
Youtube Oral 复制下面的已经是跳转到对应的time了:
https://youtu.be/2ntDYowHbZs?t=6329
IEEE 定稿:
Exploring the Limitations of Behavior Cloning for Autonomous Driving
熟悉一下缩写:
BC = behavior cloning 行为学习
IL = imitation learning 模仿学习
1. Motivation
摘要问题描述写的挺好的,首先说明 driving 不是一件容易的事,然后数千种专家策略对应场景是不现实的,所以behaviour cloning就出来了 (其实感觉和imitation learning说的是同一件事)
BC 有很多都已经实现不错了,但是呢:scaling to the full spectrum of driving behaviors 还是一个未解的问题,所以本文主要就是提出benchmark去调研 scalability and limitationss of BC
这是啥?scaling to the full?
也就是模型的扩展性,能学习到所有的行为方式 [google 翻译真是个好东西:扩展到全方位的驾驶行为]
简述版:有很多论文都在讲怎么建立end2end IL agent,怎样训练等,将这些模块化进行测试等,但没有论文专门去说 这种技术存在怎样的问题
- 不是我说的.. 是作者在oral上说的 没人调研这件事
问题场景
1. Dataset Biases
现实世界中的大多数驾驶都包含一些简单的行为或对罕见事件的复杂反应。 因此,随着收集更多数据,这可能导致性能下降,因为与 main mode of demonstrations 相比,数据集的多样性增长速度不够快。
也就是数据多样性不够主要体现在每个动作的分布情况,做出简单行为和复杂行为的分布情况不一样?但是这点 不能作为论据吧,因为在实际驾驶中 做val的数据也是分布情况不一致,或者是遇到 复杂行为启动的概率更低一点,大多数时候都还是正常行驶吧
实际上从实验结果的表格中 可知 说的是:如果在同一个场景不断训练 并不会对新场景的运行成功率有显著提高,相反可能效果还会变差,过拟合
2. causal confusion 因果混淆
会产生 Inertia Problem 描述:比如会把训练中的low speed识别成没有油门往上踩, low speed → No Throttling;所以特别是在不熟悉的场景中,训练出的agent通常会无理由的直接停下来

oral ppt 中的示意图
- 我也不知道为啥叫这样一个问题名字 惯性问题?
同时也和dataset biases 也有关系,比如:当车辆停止时,例如在红灯处,训练集中车辆保持静止的概率非常高。然后这会使得模型在low speed和 no throttling 之间产生虚假的相关性,从而在模仿学习的模型会产生过度停止和难以重新启动的问题。
其他模型,比如先将交通信号灯等,提前进行一层感知 则就没有inertia problem了,但它们在无约束环境中的端到端学习仍然表现不佳,而且并非所有原因都可以被建模(例如,一些潜在的障碍) 并且感知层的错误(例如,漏检)是不可恢复的。
3. high variance 高方差
描述:对于网络初始化的不同和图像采样顺序的不一样都会造成结果的不一致导致模型稳定性较低,另外对于输出的动作也可以看到有高方差的分布情况
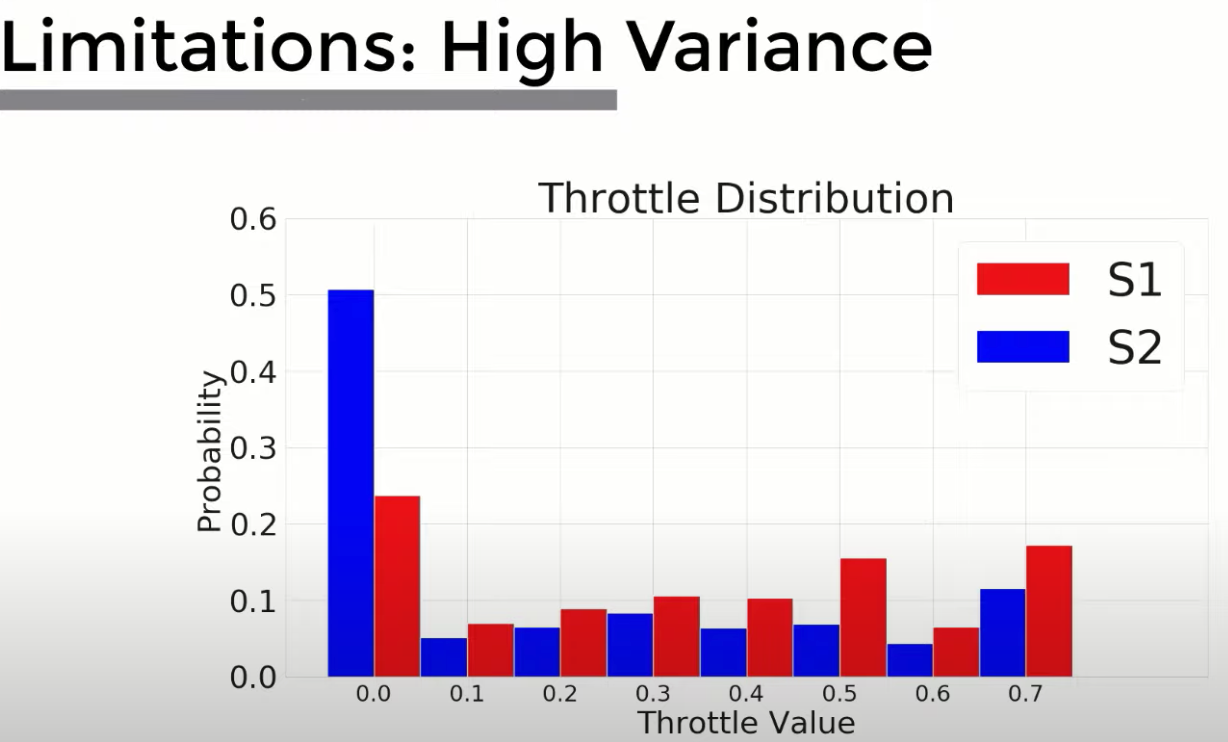
oral ppt 中的示意图
但是我感觉从输出动作去说明这点不太切实际,毕竟有时候城镇上的表现就是需要低速 少油门,主要取决于当时的场景
实验上其实写的是,在不同的random seed下 统一训练超参数和数据,训练出来的模型 S1,S2。可以看到 S1 更有可能具有更高的油门值
数据集和初始化之间的合起来 判断方差计算为:
\]
其中\(I\) 为不同的随机初始化,\(D\) 为不同的数据集
Contribution
提出了一个新benchmark → NoCrash 主要是针对Town01 但是动态障碍物较多的场景测试环境
调研、分析并总结了 端到端模仿学习中出现的问题及相关原因
配合CILRS(提出的端到端的框架)证明在大规模 off-policy dataset BC 可以在泛化性能方面大大提高现有技术 ,比如与带有额外监督的感知方法(非端到端 而是在中间感知结果输出做一层loss 有点像)比如GRI和MaRLn的方案
这要归功于使用更深层次的Resnet以及额外的速度预测目标和良好的正则化
2. Method
主要是根据CIL[12],基于模型更为泛化的 模块思路[26] 、affordance based [37]、RL [27] 改进而成
2.1 输入及输出
输入
仅相机图片 + 测量所得速度,论文中并没有介绍详细输入信息
代码中,x=2.0,y=0.0,z=1.4, FOV=100,原照片尺寸800x600,然后经过处理到,看到网络输入那边是256x256
sensor = sensors[name][g_conf.IMAGE_CUT[0]:g_conf.IMAGE_CUT[1], ...]
- 但是如果单单是cut来讲的话,有点... 截太多了吧
测量所得速度值
- 但是简略看代码时并没有发现速度值到底是谁的速度值,是周边所有车辆的还是仅仅自身速度
输出
同一个resnet34 会一条线的输出为 预测的车辆速度 \(v_p\)
然后resnet32后flatten后 + 测量速度后几层全连接、ReLU激活后flatten 合在一起,进入CM层加入command得出action
model_outputs = self._model.forward_branch(self._process_sensors(sensor_data), norm_speed,directions_tensor)
steer, throttle, brake = self._process_model_outputs(model_outputs[0]) def _process_model_outputs(self, outputs):
steer, throttle, brake = outputs[0], outputs[1], outputs[2]
2.2 框架
非常简单的框架图,直接输入的image 用resnet34来走,原因可以减少bias和方差,特别是由于网络宽度和深度的训练集采样而保持恒定的方差
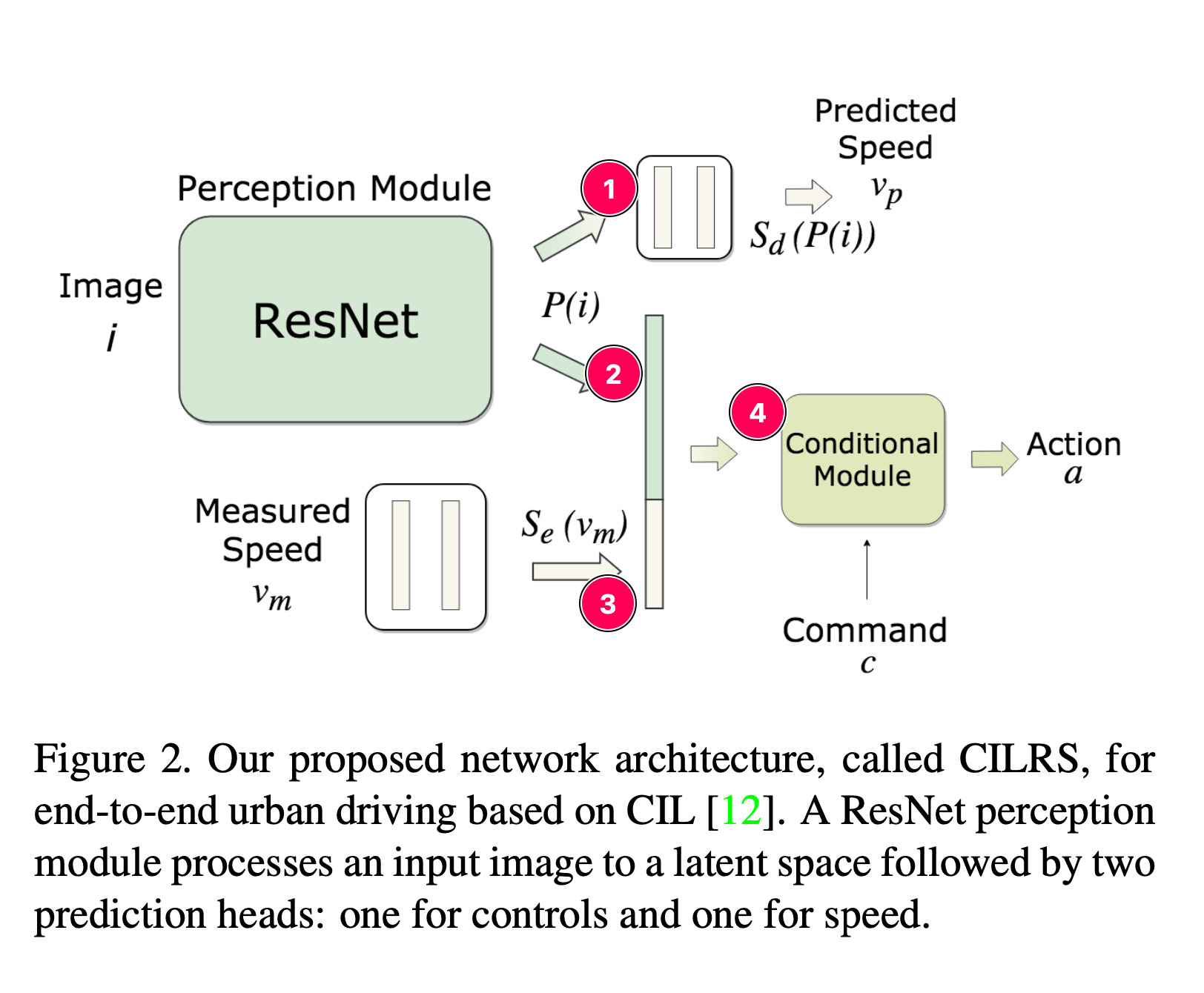
这块论文并没有仔细解释,代码中看起来更快一点,但是因为没运行就没写出准确的输入输出的大小了,Image进来 b x 3 x 256 x 256,然后经过resnet输出为B x flatten后长度
①:经过几层全连接 最后输出预测速度
②:从resnet输出的flatten 配合 ③全连接输出的 合在一起
③:测量得到的速度值经过几层全连接 拉平后和②合在一起
④:合在一起后进入CM(实际在代码中也是几层全连接层)最后输出动作
maintaining in particular a constant variance due to training set sampling with both network width and depth [31].
这个due to 有点迷啊?难道还会根据网络的宽深进行不同的训练集采样?
command C是什么?
在代码中是车辆的运行方向,作为一开始的输入进去的
directions_tensor = torch.cuda.LongTensor([directions])
3. 实验及结果
首先是场景:
- Empty Town:指环境中没有动态障碍物
- Regular Traffic:环境中有适量的车和行人
- Dense Traffic:环境中有大量的车和行人
专家数据使用的是ground truth得到的信息进行的,但是文章并没有过多解释专家数据的建立,只说专家数据在Nocrash这个benchmark中保证不会有错误数据,比如撞车现象发生。
一共收集了100个小时的驾驶数据 CARLA100,然后每个模型仅用10个小时的子集进行训练。训练中详情:
- 使用120个minnibatch,用的Adam进行训练,初始的学习率为0.0002
- 每1000个iter没有检测到train error下降,则将学习率除10
- 每20k个iter做一次2小时的val,如果val error在3个迭代次数中上升 则停止这个训练并使用此次退出来的模型参数进行测试
metric 评判标准:不是现在的leaderboard上的碰撞扣分制,而是只要有碰撞超过固定时间就算失败 不继续下面的任务,以此来计算成功次数
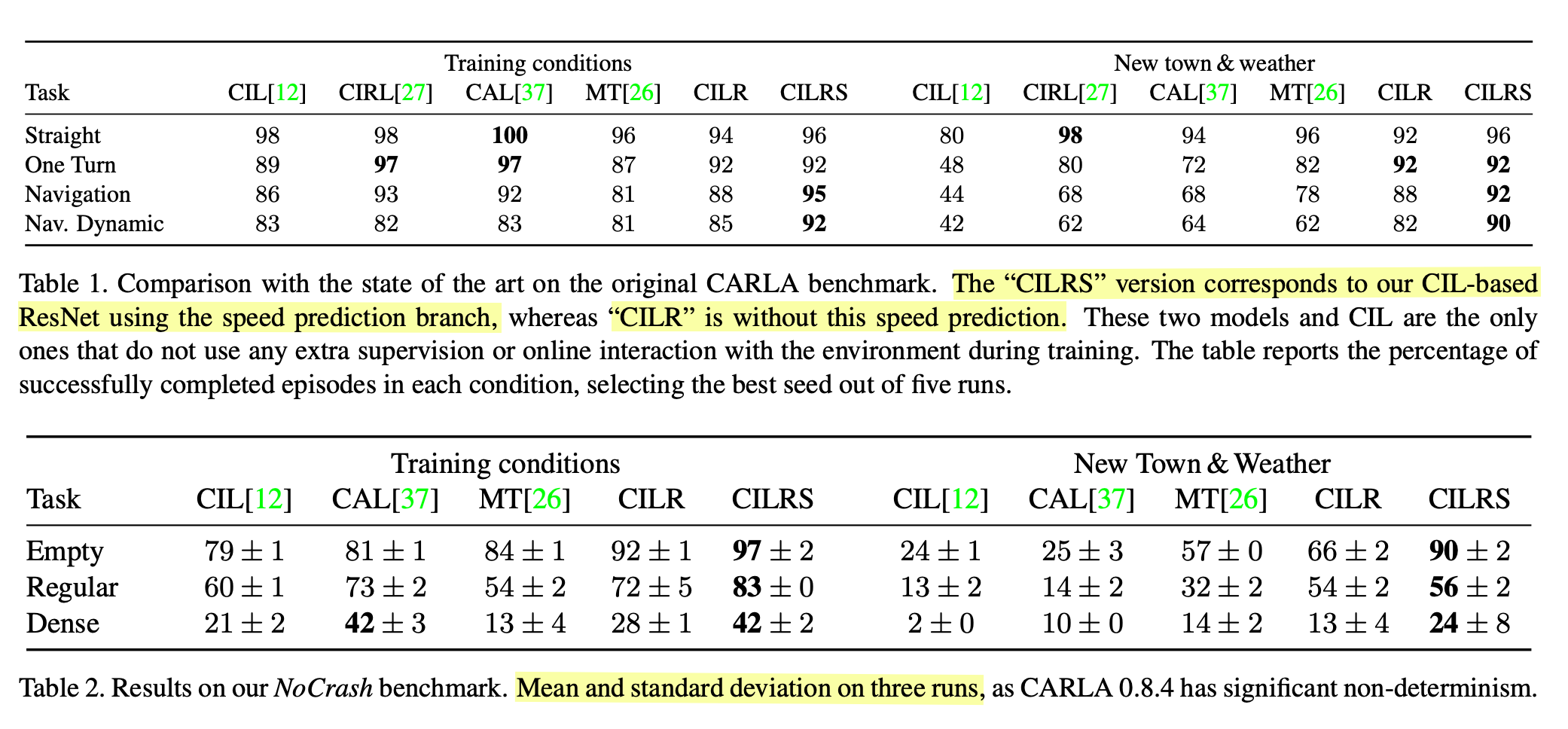
表2,主要是证明CILRS在动态障碍物数据集上的泛化性
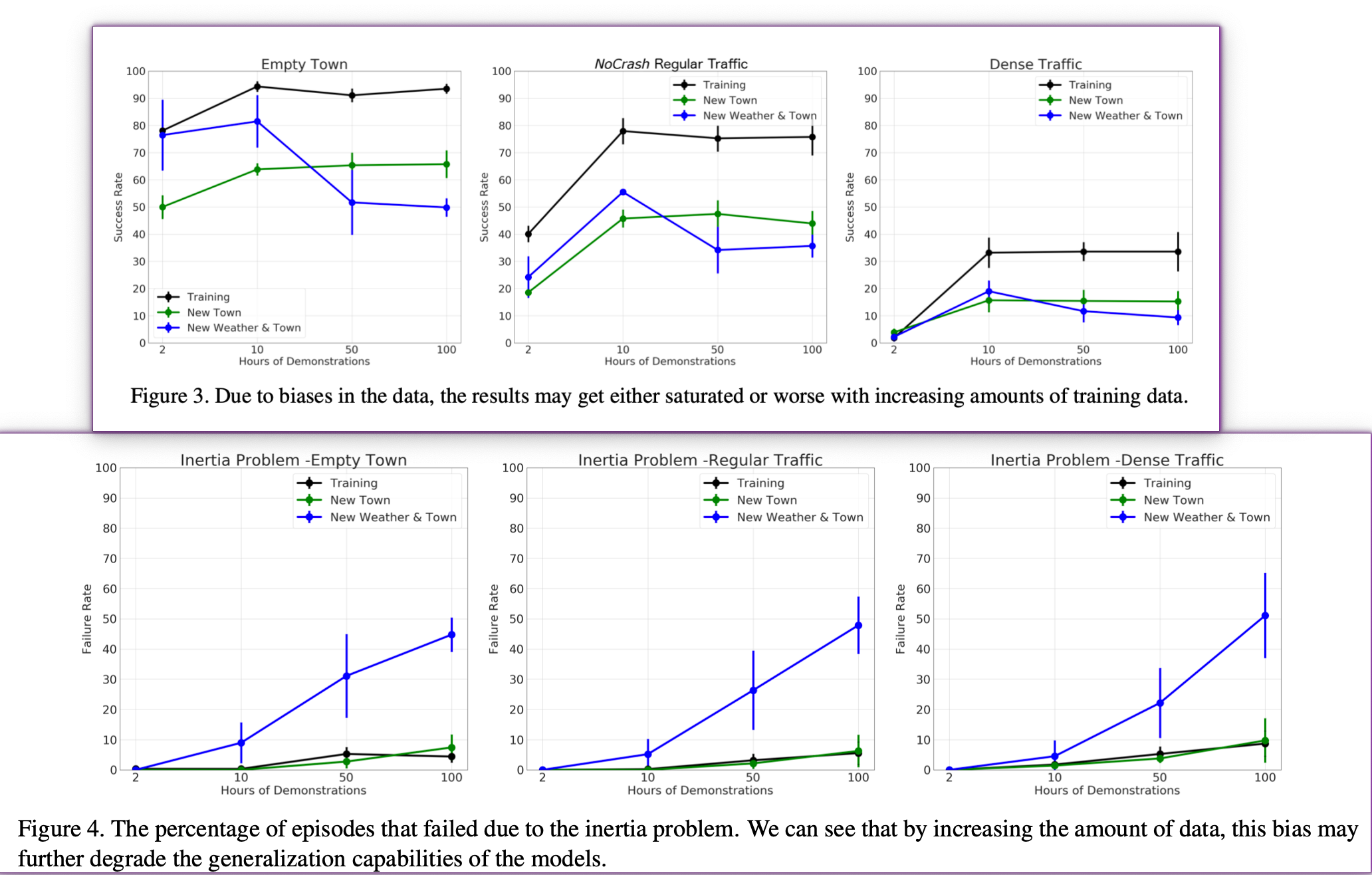
图3 主要是证明 dataset biases
图4 主要说明因果混淆和inertia problem 车辆无故停止的概率
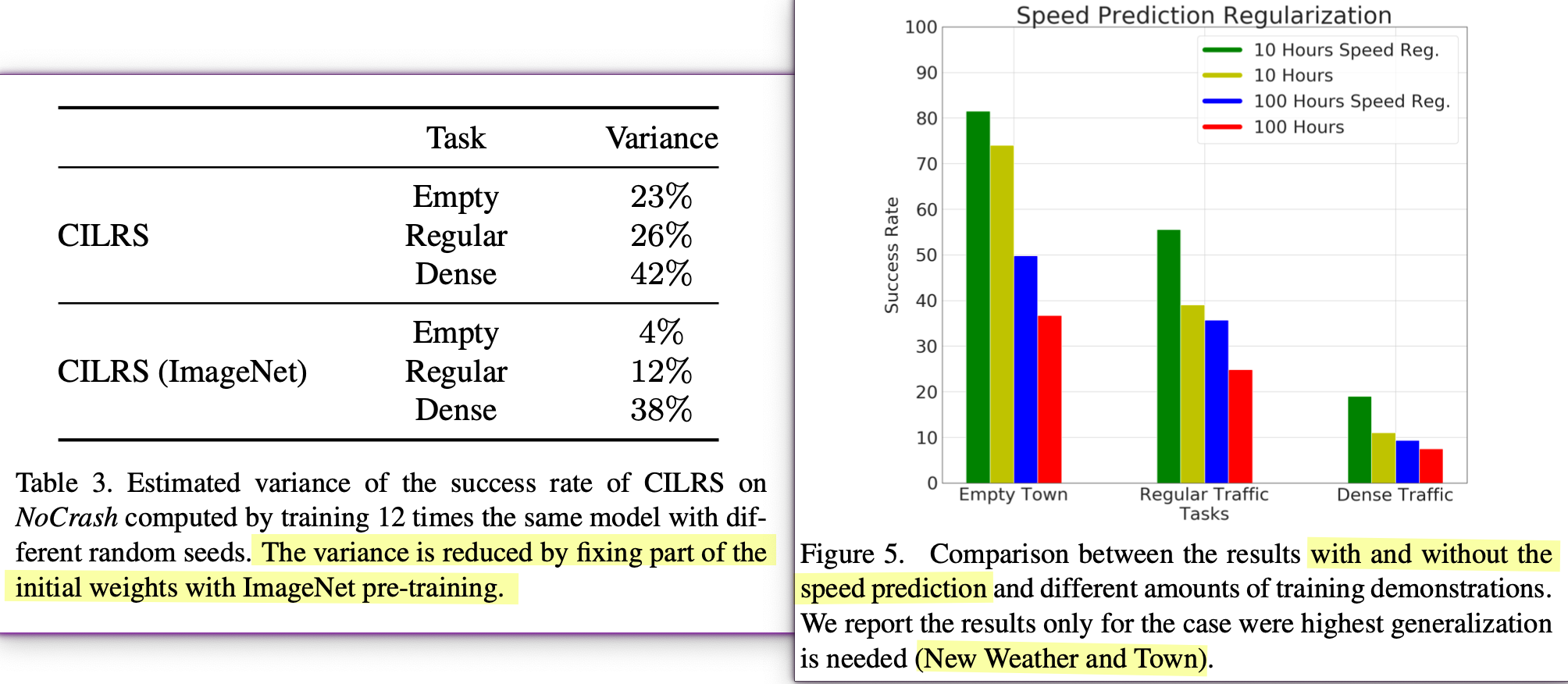
表3 主要说明使用resnet34中 imagenet中预训练的参数 可以降低成功率的方差
图5 说明 1 速度预测正则化模块加入的效果很好;2 在老城镇训练100小时的数据更能在新场景取得的成功率不如只训练10小时的 → 应该是老城镇里过拟合了,导致interia problem 或 不熟悉场景的静止情况发生
4. Conclusion
和contribution一致,总结了论文干了什么:
- 提出benchmark 主要针对 动态障碍物多的场景对 模型构成的问题,用来验证自身模型的泛化性
- 提出一个baseline,指出e2e的方案 带残差模型的时候,比其他中途输出感知再拉平add的效果会更好
然后以此为基点后的问题还有什么,原因是什么:
- 场景中动态对象的数量直接伤害了所有policy learning,因为multi-agent dynamics不是直接捕获的。
- BC的自我监督性质使其能够扩展到large dataset,但会出现 diminishing returns 所需对特定 驾驶数据集偏差 进行处理,特别是造成因果混淆的偏差 (intertia problem)、收益递减。现有的缓解方法是获取更多的 informative intermediate representations,either learning[3],or using strong domian knowledge[5]
- 初始化和采样顺序导致的巨大差异表明,在相同的 off-policy 数据上多次运行是确定最佳策略的关键。This is a part of the broader deep learning challenges regrading non-convexity and initialization, curriculum learning, and traing stability
informative intermediate representations 是啥意思?又回到了中途输出感知结果的那种端到半端 判断后 再到输出?
为什么这种可以缓解驾驶数据集偏差的问题? → 知道了 这里的感知 是单独作为一层结果感知输出,并不是 中途感知结果network结果 add一起
针对学习的非凸性?是啥?
碎碎念
原来nocrash的benchmark是这里来的... 看了好几篇排行榜上的论文提到这个场景下的东西 → 但是这个是0.8的老版本,看好像都是.txt的场景生成
后面仔细看发现 这个应该是carla leaderboard的前身,是Carla 团队的文章,后面才以此为基准做了整个carla leaderboard
感觉这篇文章的主要贡献就是提出了一个benchmark 给大家以后做实验 去验证自己的模型有多好,其余说的问题 说出来了,但是解决办法很简单 而且没有进行前后对比说明是这个办法解决了这个问题 emmm 直接对比的是结果
事实证明 做了 CILR 和 CILRS 就是关于有无 速度预测正则化
也就是说这个benchmark 只有一个目标点,不像现在进化的leaderboard 多个目标点 仅中途还带换道,和124个事故场景测试等等,所以就算知道ground truth也很难写出一个完全完美的专家数据 → 所以才衍生出这么多拿DRL来试的方案
这篇的benchmark其实没有现在进化版leaderboard的场景复杂且大,做单个问题/模型方法验证比较合适,但是也正因为数据集场景还是单一了 比如换道、高速别车等没考虑 所以metirc 只用success也还行 emmm
【论文阅读】Exploring the Limitations of Behavior Cloning for Autonomous Driving的更多相关文章
- 论文阅读 Exploring Temporal Information for Dynamic Network Embedding
10 Exploring Temporal Information for Dynamic Network Embedding 5 link:https://scholar.google.com.sg ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [论文阅读]阿里DIEN深度兴趣进化网络之总体解读
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 目录 [论文阅读]阿里DIEN深度兴趣进化网络之总体解读 0x00 摘要 0x01论文概要 1.1 文章信息 1.2 基本观点 1.2.1 DIN的 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
随机推荐
- 源码安装expect
1. yum安装expect 如果有外网,可以yum安装,如下: yum install expect 2.源码安装expect 下载tcl源码包 cd /tmp &&wget htt ...
- 用 C 语言开发一门编程语言 — 基于 Lambda 表达式的函数设计
目录 文章目录 目录 前文列表 函数 Lambda 表达式 函数设计 函数的存储 实现 Lambda 函数 函数的运行环境 函数调用 可变长的函数参数 源代码 前文列表 <用 C 语言开发一门编 ...
- C 编程异常 — implicit declaration of function 'free' is invalid in C99
环境:MAC pro 问题:在编译程序的触发异常. main.c:17:9: warning: implicit declaration of function 'free' is invalid i ...
- mogodb replication set复制集
replication set复制集 简要命令 replication set复制集 replicattion set 多台服务器维护相同的数据副本,提高服务器的可用性. Replication se ...
- 『手撕Vue-CLI』处理不同指令
前言 在上一篇『手撕Vue-CLI』添加自定义指令中,已经实现了自定义指令的添加,但是指令还是比较简单的,只是简单的打印一句话,那么在实际运用场景中,可能会有更多的需求,比如可能需要在指令中传递参数, ...
- Django视图的请求与响应
1.请求对象 (1)请求方式 print(request.method) (2)请求数据 (3)请求路径 # HttpRequest.path: 表示请求的路径(不含get参数) # HttpRequ ...
- 『手撕Vue-CLI』获取下载目录
开篇 在上一篇文章中,简单的对 Nue-CLI 的代码通过函数柯里化优化了一下,这一次来实现一个获取下载目录的功能. 背景 在 Nue-CLI 中,我现在实现的是 create 指令,这个指令本质就是 ...
- 使用vscode编辑c语言
在 Visual Studio Code (VSCode) 中配置 C 语言环境 步骤指南: 一,前期准备(安装扩展,软件包) 安装 C/C++ 扩展 打开 VSCode. 点击左侧边栏的扩展按钮(或 ...
- Windows10 LTSC版,比Win7还干净
在Windows操作系统的发展历程中,每一个版本都承载着微软对用户需求的深度理解和技术创新.其中,Windows 7以其稳定.高效和简洁的特点,赢得了众多用户的喜爱. 然而,随着技术的不断进步和用户需 ...
- Java求两个List集合的交集、并集、差集
在项目中经常会求解集合的交集.并集.差集,这里做个记录.首先创建两个集合list1.list2以及添加元素. List<String> list1 = new ArrayList<& ...