【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量
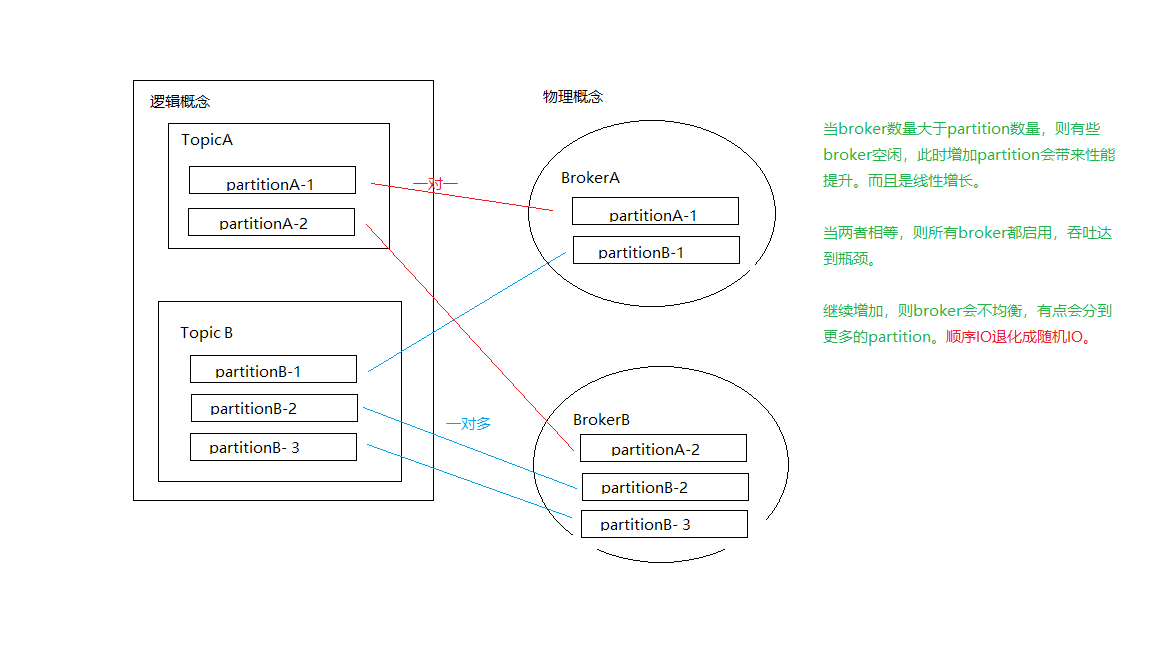
broker的数量最好大于等于partition数量
一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
一个broker如果对应多个partition,需要随机分发,顺序IO会退化成随机IO。
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
第一阶段:
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
第二阶段:
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
总结:
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
consumer数量最好和partition数量一致
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
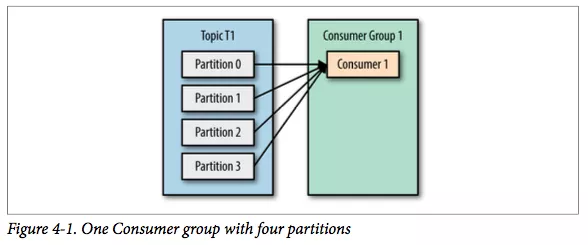
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。

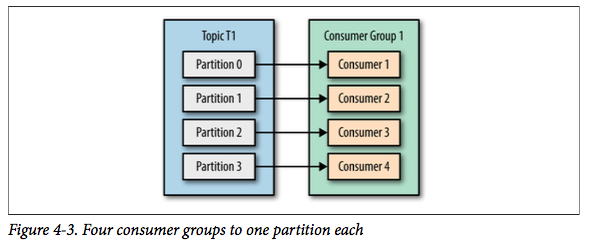
如果增加到 4 个消费者,那么每个消费者将会分别��到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。
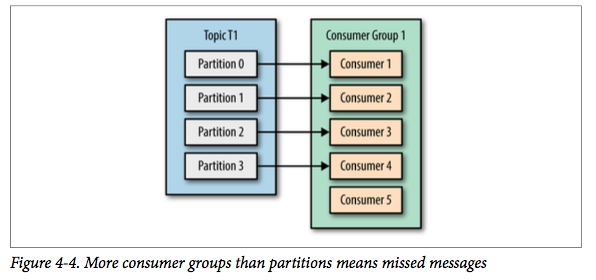
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。
这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
● 保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
● 解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
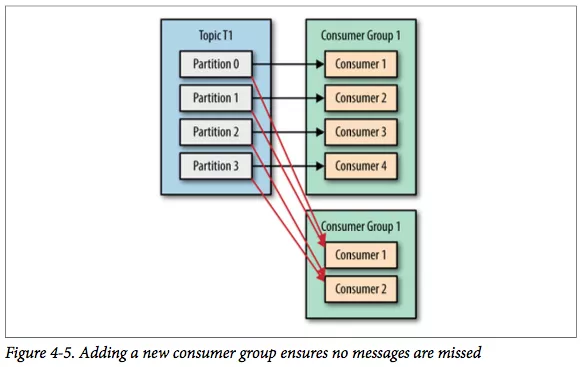
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
总结
如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
- broker的数量最好大于等于partition数量
- consumer数量最好和partition数量一致
【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量的更多相关文章
- Kafka最佳实践
一.硬件考量 1.1.内存 不建议为kafka分配超过5g的heap,因为会消耗28-30g的文件系统缓存,而是考虑为kafka的读写预留充足的buffer.Buffer大小的快速计算方法是平均磁盘写 ...
- 【译】Kafka最佳实践 / Kafka Best Practices
本文来自于DataWorks Summit/Hadoop Summit上的<Apache Kafka最佳实践>分享,里面给出了很多关于Kafka的使用心得,非常值得一看,今推荐给大家. 硬 ...
- window下Kafka最佳实践
Kafka的介绍和入门请看这里kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 当前文章从实践的角度为大家规避window下使用的坑. 1.要求: java 6+ 2.下载kafka ...
- Apache Kafka: 优化部署的10个最佳实践
原文作者:Ben Bromhead 译者:江玮 原文地址:https://www.infoq.com/articles/apache-kafka-best-practices-to-opti ...
- 【kafka学习笔记】合理安排broker、partition、consumer数量
broker的数量最好大于等于partition数量 一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势. broker如果免得是多个partition,需要随机分发,顺序IO会退 ...
- 大规模使用 Apache Kafka 的20个最佳实践
必读 | 大规模使用 Apache Kafka 的20个最佳实践 配图来源:书籍<深入理解Kafka> Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Re ...
- Kafka在大型应用中的 20 项最佳实践
原标题:Kafka如何做到1秒处理1500万条消息? Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台).Uber.Square(移动支付公 ...
- Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践
Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践 本篇博文主要提供一个在 SpringBoot 中自定义 kafka配置的实践,想象这样一个场景:你的系统 ...
- HP下kafka的实践
kafka 简介 Kafka 是一种高吞吐量的分布式发布订阅消息系统 kafka角色必知 producer:生产者. consumer:消费者. topic: 消息以topic为类别记录,Kafka将 ...
- Spark Streaming与kafka整合实践之WordCount
本次实践使用kafka console作为消息的生产者,Spark Streaming作为消息的消费者,具体实践代码如下 首先启动kafka server .\bin\windows\kafka-se ...
随机推荐
- nim 1. 安装、IDE、HelloWorld
2015年,某大神写过nim的教程,请参阅: Nim教程[一] - liulun - 博客园 (cnblogs.com) 七年过去了, nim应该更成熟了. 1.安装 下载页面:Windows ins ...
- 零知识证明: Tornado Cash 项目学习
前言 最近在了解零知识证明方面的内容,这方面的内容确实不好入门也不好掌握,在了解了一些基础的概念以后,决定选择一个应用了零知识证明的项目来进行进一步的学习.最终选择了 Tornado Cash 这个项 ...
- 不同模式下删除Oracle数据表的三个实例
首发微信公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__biz=MzI1NTQyNzg3MQ==&mid=2247485212&idx=1 ...
- java学习之旅(day.22)
CSS 前端三要素:HTML.CSS.javaScript 结构 表现 交互 相当于骨头,表皮 ,血肉吧 如何学习CSS CSS是什么 CSS怎么用(快速入门) CSS选择器(重点+难点) 美化网 ...
- webapi添加添加websocket中间件
添加位置 我按照MSDN的例子添加了一个复述客户端响应的中间件.需要注意的时,中间件采用那种方式添加,添加在哪. 哪种方式 我选择创建一条管道分支,只要时ws的连接请求,就转到这个分支 因此,我们需要 ...
- JSON数据压缩传输(一)- 无标记数组
服务端 //需要传回前端的字段string[] fields = dto.fields.Split(','); var resluts=new List<dynamic>(); //只取前 ...
- 从零开始写 Docker(十五)---实现 mydocker run -e 支持环境变量传递
本文为从零开始写 Docker 系列第十五篇,实现 mydocker run -e, 支持在启动容器时指定环境变量,让容器内运行的程序可以使用外部传递的环境变量. 完整代码见:https://gith ...
- Python爬图片(面向对象版)
import requests from lxml import etree from threading import Thread class Spider(object): def __init ...
- CSS操作——display属性
display可以指定元素的显示模式,它可以把行内元素修改成块状元素,也可以把别的模式的元素改成行内元素.diisplay常用的值有四个. 语法: /* display: block; // 声明当前 ...
- Android 13 - Media框架(8)- MediaExtractor
关注公众号免费阅读全文,进入音视频开发技术分享群! 上一篇我们了解了 GenericSource 需要依赖 IMediaExtractor 完成 demux 工作,这一篇我们就来学习 android ...