【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量
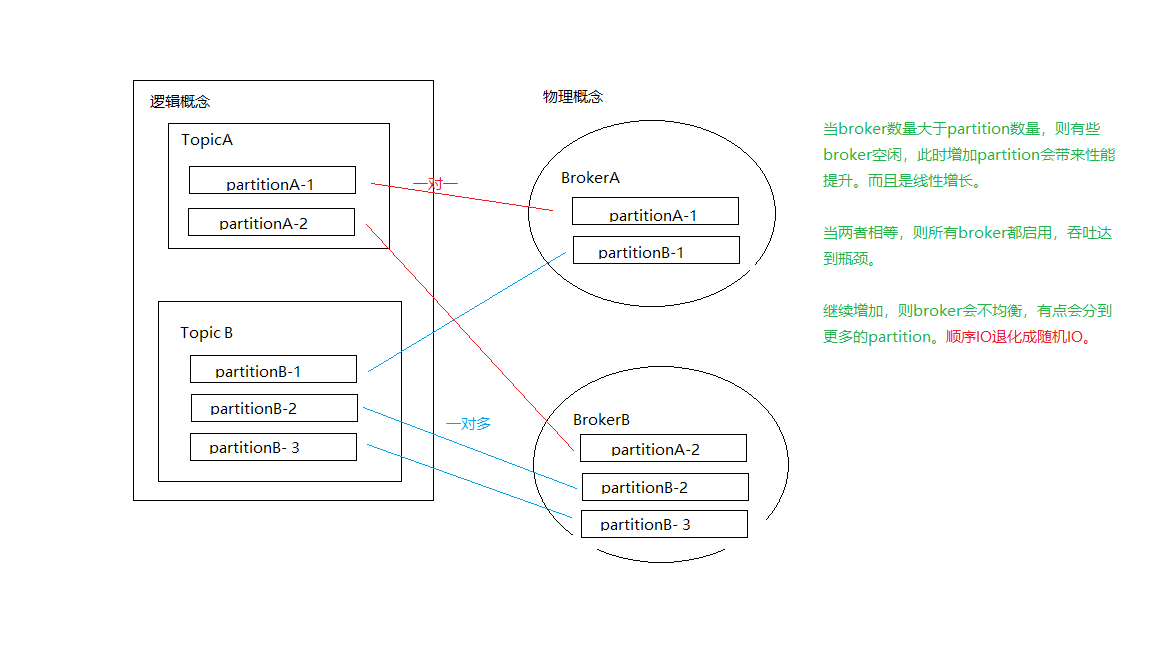
broker的数量最好大于等于partition数量
一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
一个broker如果对应多个partition,需要随机分发,顺序IO会退化成随机IO。
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
第一阶段:
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
第二阶段:
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
总结:
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
consumer数量最好和partition数量一致
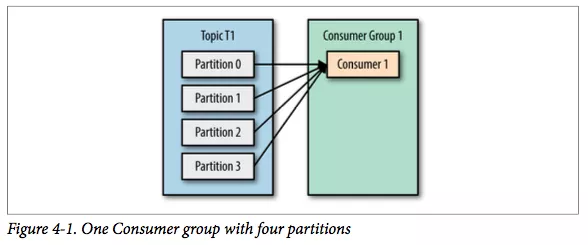
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。

如果增加到 4 个消费者,那么每个消费者将会分别��到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。
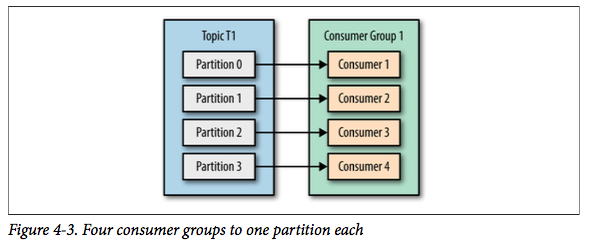
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
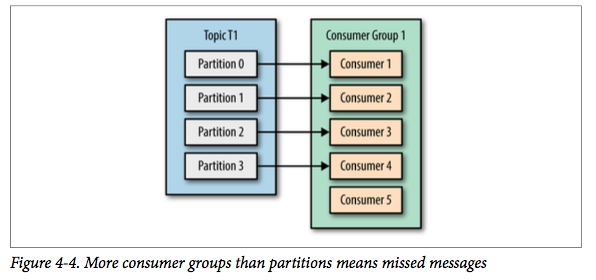
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。
这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
● 保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
● 解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
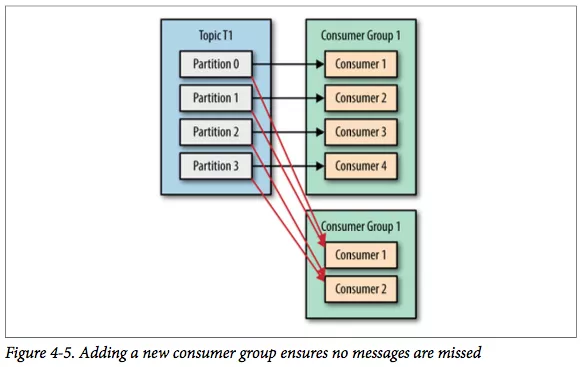
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
总结
如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
- broker的数量最好大于等于partition数量
- consumer数量最好和partition数量一致
【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量的更多相关文章
- Kafka最佳实践
一.硬件考量 1.1.内存 不建议为kafka分配超过5g的heap,因为会消耗28-30g的文件系统缓存,而是考虑为kafka的读写预留充足的buffer.Buffer大小的快速计算方法是平均磁盘写 ...
- 【译】Kafka最佳实践 / Kafka Best Practices
本文来自于DataWorks Summit/Hadoop Summit上的<Apache Kafka最佳实践>分享,里面给出了很多关于Kafka的使用心得,非常值得一看,今推荐给大家. 硬 ...
- window下Kafka最佳实践
Kafka的介绍和入门请看这里kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 当前文章从实践的角度为大家规避window下使用的坑. 1.要求: java 6+ 2.下载kafka ...
- Apache Kafka: 优化部署的10个最佳实践
原文作者:Ben Bromhead 译者:江玮 原文地址:https://www.infoq.com/articles/apache-kafka-best-practices-to-opti ...
- 【kafka学习笔记】合理安排broker、partition、consumer数量
broker的数量最好大于等于partition数量 一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势. broker如果免得是多个partition,需要随机分发,顺序IO会退 ...
- 大规模使用 Apache Kafka 的20个最佳实践
必读 | 大规模使用 Apache Kafka 的20个最佳实践 配图来源:书籍<深入理解Kafka> Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Re ...
- Kafka在大型应用中的 20 项最佳实践
原标题:Kafka如何做到1秒处理1500万条消息? Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台).Uber.Square(移动支付公 ...
- Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践
Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践 本篇博文主要提供一个在 SpringBoot 中自定义 kafka配置的实践,想象这样一个场景:你的系统 ...
- HP下kafka的实践
kafka 简介 Kafka 是一种高吞吐量的分布式发布订阅消息系统 kafka角色必知 producer:生产者. consumer:消费者. topic: 消息以topic为类别记录,Kafka将 ...
- Spark Streaming与kafka整合实践之WordCount
本次实践使用kafka console作为消息的生产者,Spark Streaming作为消息的消费者,具体实践代码如下 首先启动kafka server .\bin\windows\kafka-se ...
随机推荐
- Go语言连接Redis之go-redis使用指南
参考下面的连接: https://mp.weixin.qq.com/s?__biz=MzU5MjAxMDc1Ng==&mid=2247483899&idx=1&sn=b103c ...
- Ubuntu下MPICH的安装与配置
原创直达链接 一.MPICH的下载与安装 MPI安装文件下载地址: 博客下载地址 或 官网地址 可以下载3.4.2版本的,本文就是3.4.2版本 1.解压: sudo tar - zxvf mpich ...
- Java IO流文件
Java IO流文件 创建文件 使用File类进行创建文件操作,创建该对象包含三种构造方法 new File(String pathname); //根据路径+文件名创建一个File对象 new Fi ...
- 抽丝剥茧:详述一次DevServer Proxy配置无效问题的细致排查过程
事情的起因是这样的,在一个已上线的项目中,其中一个包含登录和获取菜单的接口因响应时间较长,后端让我尝试未经服务转发的另一域名下的新接口,旧接口允许跨域请求,但新接口不允许本地访问(只允许发布测试/生产 ...
- PageOffice在线打开office文件通过js调用vba可实现的功能
pageoffice封装的js接口有限,某些比较复杂的设置用到的客户不多,所以没有提供直接的js方法,但是pageoffice提供了Document属性和RunMacro方法,可以调vba或直接运行宏 ...
- kubeadm部署的k8s证书过期问题 k8s问题排查:the existing bootstrap client certificate in /etc/kubernetes/kubelet.conf is expired
解决问题: 估计跟移动有关,下面那个没解决问题,是因为在原有文件的基础上修改的吧?而这里直接是移走,重新生成了新的.不太清楚是不是这个原因. $ cd /etc/kubernetes/pki/ $ m ...
- TypingLearn解决了我在学习英语中的一大痛点
上一次在博客园发贴还是在上一次(2021年),那个时候博客园就遇到了危机(被罚款).彼时在疫情期间,我个人生活也受到了影响,先后去了多个城市,最终在上海找到了 .NET Web开发的岗位,还是比较幸运 ...
- FFmpeg中的常见结构体
代码基于FFmpeg5.0.1 目录 FFFormatContext AVFormatContext AVIOContext FFIOContext URLContext URLProtocol AV ...
- Qt程序运行报错
报错内容 PC环境为Ubuntu20.04,Qt版本是Qt5.12.9,AsensingViewer是编译好的程序 ./AsensingViewer: error while loading shar ...
- OpenCV笔记(6) Bitwise
源码: BitwiseAnd //dst = src1 & src2 public static void BitwiseAnd(InputArray src1, InputArray s ...