【1】paddle飞桨框架高层API使用讲解
1.高层API简介
飞桨框架2.0全新推出高层API,是对飞桨API的进一步封装与升级,提供了更加简洁易用的API,进一步提升了飞桨的易学易用性,并增强飞桨的功能。
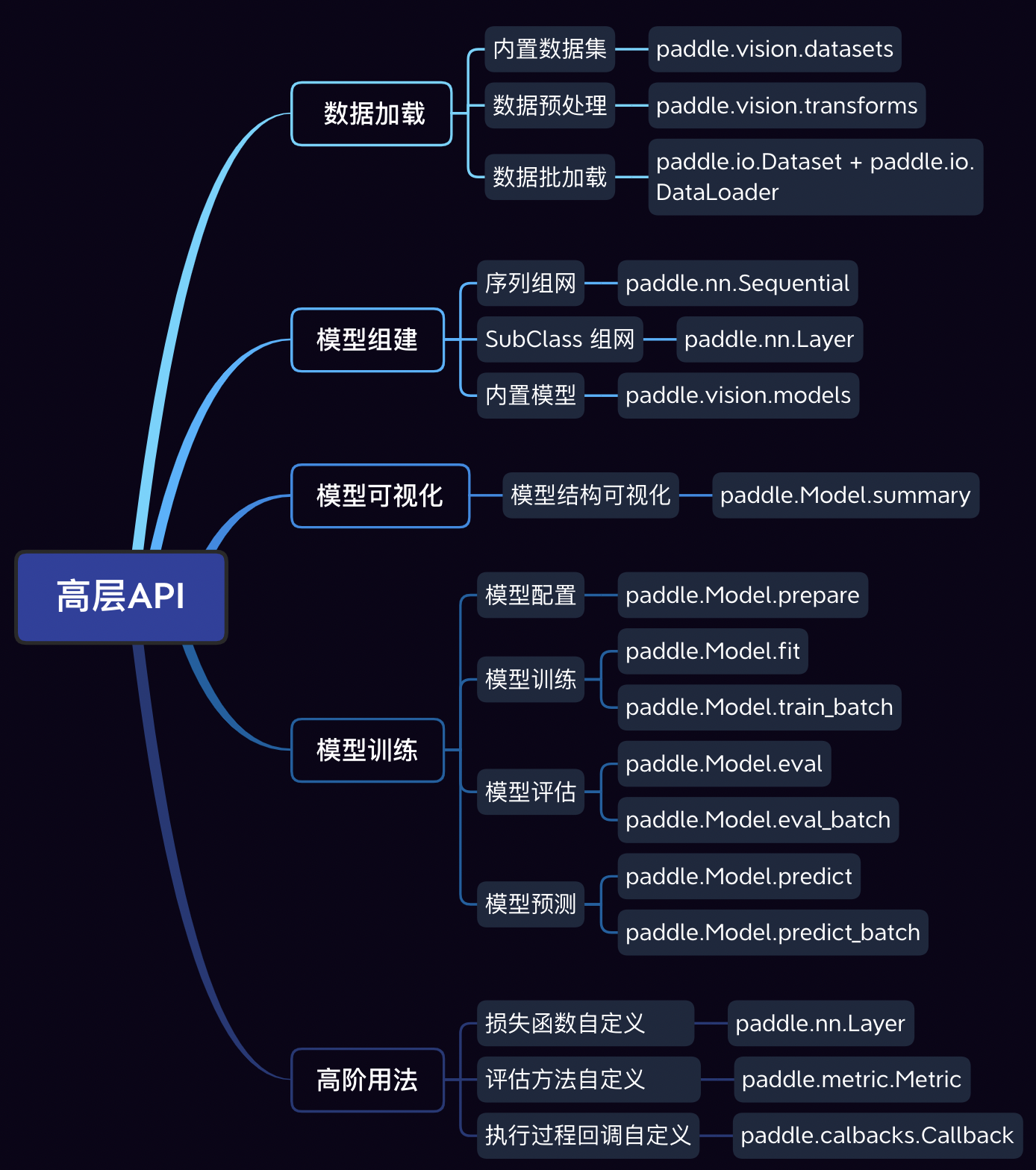
飞桨高层API由五个模块组成:数据加载、模型组建、模型训练、模型可视化和高阶用法。
下面以MNIST分类器为例子,来感受一下便捷吧!
import paddle
from paddle.vision.transforms import Compose, Normalize
from paddle.vision.datasets import MNIST
import paddle.nn as nn
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test', transform=transform)
# 模型组网
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 模型训练,
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 模型评估,
model.evaluate(test_dataset, verbose=1)通过上面十来行代码,就能轻松完成一个MNIST分类器的训练、评估与保存。可以看出,飞桨框架高层对数据预处理、数据加载、模型组网、模型训练、模型评估、模型保存等都进行了封装,能够快速高效地完成模型的训练。
效果如下:
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/5
step 20/938 [..............................] - loss: 0.7650 - acc: 0.5492 - ETA: 16s - 18ms/ste
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 938/938 [==============================] - loss: 0.2835 - acc: 0.9030 - 10ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.1457 - acc: 0.9502 - 17ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0215 - acc: 0.9600 - 17ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 0.0241 - acc: 0.9645 - 17ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.1283 - acc: 0.9675 - 18ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 10000/10000 [==============================] - loss: 7.1526e-07 - acc: 0.9761 - 1ms/step
Eval samples: 10000
{'loss': [7.15256e-07], 'acc': 0.9761}2.高层API详解
2.1 数据预处理与数据加载
对于数据预处理与数据加载,飞桨框架提供了许多API,列表如下:
- 1、 飞桨框架内置数据集:paddle.vision.datasets内置包含了许多CV领域相关的数据集,直接调用API即可使用;
- 2、 飞桨框架数据预处理:paddle.vision.transforms飞桨框架对于图像预处理的方式,可以快速完成常见的图像预处理的方式,如调整色调、对比度,图像大小等;
- 3、 飞桨框架数据加载:paddle.io.Dataset与paddle.io.DataLoader飞桨框架标准数据加载方式,可以”一键”完成数据的批加载与异步加载;
2.1.1 飞桨框架内置数据集
首先,飞桨框架将常用的数据集作为领域API对用户开放,对应API所在目录为paddle.vision.datasets包含的数据集如下所示。
print("飞桨框架CV领域内置数据集:" + str(paddle.vision.datasets.__all__))
飞桨框架CV领域内置数据集:['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST', 'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']飞桨提供的数据集API包含计算机视觉领域中常见的数据集,完全可以满足我们在数据集方面的需求。 我们给出一个数据集的加载示例方便理解。
train_dataset = paddle.vision.datasets.MNIST(mode='train')
test_dataset = paddle.vision.datasets.MNIST(mode='test')
# 取其中的一条数据看一下,如图所示:
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0], train_dataset[0][1]
train_data0 = np.array(train_data0).reshape([28,28])
%matplotlib inline
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))结果如下:
train_data0 label is: [5]

2.1.2 飞桨框架预处理方法
飞桨框架提供了20多种数据集预处理的接口,都集中在 paddle.vision.transforms 目录下,具体包含的API如下:
print('视觉数据预处理方法:' + str(paddle.vision.transforms.__all__))视觉数据预处理方法:['BaseTransform', 'Compose', 'Resize', 'RandomResizedCrop', 'CenterCrop', 'RandomHorizontalFlip', 'RandomVerticalFlip', 'Transpose', 'Normalize', 'BrightnessTransform', 'SaturationTransform', 'ContrastTransform', 'HueTransform', 'ColorJitter', 'RandomCrop', 'Pad', 'RandomRotation', 'Grayscale', 'ToTensor', 'to_tensor', 'hflip', 'vflip', 'resize', 'pad', 'rotate', 'to_grayscale', 'crop', 'center_crop', 'adjust_brightness', 'adjust_contrast', 'adjust_hue', 'normalize']飞桨框架的预处理方法实现了图像的色调、对比度、饱和度、大小等各种数字图像处理的方法。而这些数据预处理方法非常方便,只需要先创建一个数据预处理的transform,在其中存入需要进行的数据预处理方法,然后在数据加载的过程中,将transform作为参数传入即可,具体如下:
# 首先,我们创建一个transform, 用于存储数据预处理的接口组合。
# 数据预处理
from paddle.vision.transforms import Compose, ColorJitter
from paddle.vision.datasets import Cifar10
transform = Compose([ColorJitter()]) # transform用于存储数据预处理的接口组合 ColorJitter()实现随机调整亮度、对比度和饱和度
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = Cifar10(mode='train', transform=transform)
test_dataset = Cifar10(mode='test')随机处理与未随机处理的对比图如下:
import numpy as np
import matplotlib.pyplot as plt
index = 326
def show_img(img_array):
img_array = img_array.astype('float32') / 255.
plt.figure(figsize=(2, 2))
plt.imshow(img_array, cmap=plt.cm.binary)
dataset_without_transform = Cifar10(mode='train')
show_img(np.array(dataset_without_transform[index][0]))
dataset_with_transform = Cifar10(mode='train', transform=ColorJitter(0.4, 0.4, 0.4, 0.4))
show_img(np.array(dataset_with_transform[index][0]))结果如下:


2.1.3 自定义数据集加载
飞桨框架标准数据加载方式,可以”一键”完成数据的批加载与异步加载; 如何进行数据集的定义,飞桨为用户提供了paddle.io.Dataset基类,让用户通过类的集成来快速实现数据集定义。示例如下
from paddle.io import Dataset
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
# 下面的traindata1,label1之类的只是一个示例,不能直接用于DataLoader加载,大家可以改成自己的实际数据
if mode == 'train':
self.data = [
['traindata1', 'label1'],
['traindata2', 'label2'],
['traindata3', 'label3'],
['traindata4', 'label4'],
]
else:
self.data = [
['testdata1', 'label1'],
['testdata2', 'label2'],
['testdata3', 'label3'],
['testdata4', 'label4'],
]
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = self.data[index][0]
label = self.data[index][1]
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
# 测试定义的数据集
train_dataset = MyDataset(mode='train')
val_dataset = MyDataset(mode='test')
print('=============train dataset=============')
for data, label in train_dataset:
print(data, label)
print('=============evaluation dataset=============')
for data, label in val_dataset:
print(data, label)
=============train dataset=============
traindata1 label1
traindata2 label2
traindata3 label3
traindata4 label4
=============evaluation dataset=============
testdata1 label1
testdata2 label2
testdata3 label3
testdata4 label4这样就实现了创建一个自己的数据集,然后,将train_dataset 与 val_dataset 作为参数,传入到DataLoader中,即可获得一个数据加载器,完成训练数据的加载。 对于数据集的定义上,飞桨框架同时支持map-style和interable-style两种类型的数据集定义,只需要分别继承paddle.io.Dataset和paddle.io.IterableDataset即可。
2.2 网络构建
在网络构建模块,飞桨高层API与基础API保持完全的一致,都使用paddle.nn下的API进行组网。飞桨框架 paddle.nn 目录下包含了所有与模型组网相关的API,如卷积相关的 Conv1D、Conv2D、Conv3D,循环神经网络相关的 RNN、LSTM、GRU 等。
对于组网方式,飞桨框架统一支持 Sequential 或 SubClass 的方式进行模型的组建。根据实际的使用场景,来选择最合适的组网方式。如针对顺序的线性网络结构我们可以直接使用 Sequential ,相比于 SubClass ,Sequential 可以快速的完成组网。 如果是一些比较复杂的网络结构,我们可以使用 SubClass 定义的方式来进行模型代码编写,在 init 构造函数中进行 Layer 的声明,在 forward 中使用声明的 Layer 变量进行前向计算。通过这种方式,我们可以组建更灵活的网络结构。
2.2.1 Sequential 的组网方式
使用 Sequential 进行组网的实现如下:
# Sequential形式组网
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)2.2.2 SubClass 的组网方式
使用 SubClass 进行组网的实现如下:
# SubClass方式组网
class Mnist(paddle.nn.Layer):
def __init__(self):
super(Mnist, self).__init__()
self.flatten = nn.Flatten()
self.linear_1 = nn.Linear(784, 512)
self.linear_2 = nn.Linear(512, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, inputs):
y = self.flatten(inputs)
y = self.linear_1(y)
y = self.relu(y)
y = self.dropout(y)
y = self.linear_2(y)
return y上述的SubClass 组网的结果与Sequential 组网的结果完全一致,可以明显看出,使用SubClass 组网会比使用Sequential 更复杂一些。不过,这带来的是网络模型结构的灵活性。我们可以设计不同的网络模型结构来应对不同的场景。
2.2.3 飞桨框架内置模型
除了自定义模型结构外,真正的一行代码实现深度学习模型。目前,飞桨框架内置的模型都是CV领域领域的模型,在paddle.vision.models目录下,具体包含如下的模型:
print("视觉相关模型: " + str(paddle.vision.models.__all__))
视觉相关模型: ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152', 'VGG', 'vgg11', 'vgg13', 'vgg16', 'vgg19', 'MobileNetV1', 'mobilenet_v1', 'MobileNetV2', 'mobilenet_v2', 'LeNet']只需要一行即可完成模型的构建,具体如下:
lenet = paddle.vision.models.LeNet()这样我们就完成了Lenet模型的搭建,然后就可以开始下一步的模型训练了。
2.3、模型训练
2.3.1 使用高层API在全部数据集上进行训练
飞桨高层API将训练、评估与预测API都进行了封装,直接使用Model.prepare()、Model.fit()、Model.evaluate()、Model.predict()完成模型的训练、评估与预测。使用飞桨高层API,可以在3-5行内,完成模型的训练。具体代码如下:
# 定义 数据集与模型
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
from paddle.vision.datasets import MNIST
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = T.Normalize(mean=[127.5], std=[127.5])
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test', transform=transform)
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
# 使用高层API训练
# 将网络结构用 Model类封装成为模型
model = paddle.Model(mnist)
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 启动模型评估,指定数据集,设置日志格式
evaluate_result = model.evaluate(test_dataset, verbose=1)
# 启动模型测试,指定测试集
predict_result = model.predict(test_dataset)3.3.2 使用高层API在一个批次的数据集上训练、验证与测试
有时我们需要对数据按batch进行取样,然后完成模型的训练与验证,这时,可以使用 train_batch、eval_batch、predict_batch 完成一个批次上的训练、验证与测试,具体如下:
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 使用train_batch 完成训练
for batch_id, data in enumerate(train_loader()):
model.train_batch([data[0]],[data[1]])
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=True)
# 使用 eval_batch 完成验证
for batch_id, data in enumerate(test_loader()):
model.eval_batch([data[0]],[data[1]])
# 使用 predict_batch 完成预测
for batch_id, data in enumerate(test_loader()):
model.predict_batch([data[0]])3.3.3 使用基础API进行训练
由于飞桨高层API是对基础API的封装,所以我们也可以对其进行拆解,将高层API用基础API实现。拆解的步骤如下面的代码,这里我们只对fit,也就是训练过程进行拆解。
import paddle.nn.functional as F
# 加载数据
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=64, shuffle=True)
# 加载训练集 batch_size 设为 64
def train(model):
model.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()) # 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts = model(x_data)
loss = F.cross_entropy(predicts, y_data) # 计算损失
acc = paddle.metric.accuracy(predicts, y_data) # 计算精度
loss.backward() # 反向传播
if batch_id % 500 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
optim.step() # 更新参数
optim.clear_grad() # 清除梯度
model = Mnist()
train(model)2.4、高层API进阶用法
2.4.1 自定义Loss
有时我们会遇到特定任务的Loss计算方式在框架既有的Loss接口中不存在,或算法不符合自己的需求,那么期望能够自己来进行Loss的自定义,我们这里就会讲解介绍一下如何进行Loss的自定义操作,首先来看下面的代码:
class SelfDefineLoss(paddle.nn.Layer):
"""
1. 继承paddle.nn.Layer
"""
def __init__(self):
"""
2. 构造函数根据自己的实际算法需求和使用需求进行参数定义即可
"""
super(SelfDefineLoss, self).__init__()
def forward(self, input, label):
"""
3. 实现forward函数,forward在调用时会传递两个参数:input和label
- input:单个或批次训练数据经过模型前向计算输出结果
- label:单个或批次训练数据对应的标签数据
接口返回值是一个Tensor,根据自定义的逻辑加和或计算均值后的损失
"""
# 使用Paddle中相关API自定义的计算逻辑
# output = xxxxx
# return output那么了解完代码层面如果编写自定义代码后我们看一个实际的例子,下面是在图像分割示例代码中写的一个自定义Loss,主要是想使用自定义的softmax计算维度。
class SoftmaxWithCrossEntropy(paddle.nn.Layer):
def __init__(self):
super(SoftmaxWithCrossEntropy, self).__init__()
def forward(self, input, label):
loss = F.softmax_with_cross_entropy(input,
label,
return_softmax=False,
axis=1)
return paddle.mean(loss)
2.4.2 自定义metric
和Loss一样,如果遇到一些想要做个性化实现的操作时,我们也可以来通过框架完成自定义的评估计算方法,具体的实现方式如下:
### 伪代码说明
class SelfDefineMetric(paddle.metric.Metric):
"""
1. 继承paddle.metric.Metric
"""
def __init__(self):
"""
2. 构造函数实现,自定义参数即可
"""
super(SelfDefineMetric, self).__init__()
def name(self):
"""
3. 实现name方法,返回定义的评估指标名字
"""
return '自定义评价指标的名字'
def compute(self, ...)
"""
4. 本步骤可以省略,实现compute方法,这个方法主要用于`update`的加速,可以在这个方法中调用一些paddle实现好的Tensor计算API,编译到模型网络中一起使用低层C++ OP计算。
"""
return 自己想要返回的数据,会做为update的参数传入。
def update(self, ...):
"""
5. 实现update方法,用于单个batch训练时进行评估指标计算。
- 当`compute`类函数未实现时,会将模型的计算输出和标签数据的展平作为`update`的参数传入。
- 当`compute`类函数做了实现时,会将compute的返回结果作为`update`的参数传入。
"""
return acc value
def accumulate(self):
"""
6. 实现accumulate方法,返回历史batch训练积累后计算得到的评价指标值。
每次`update`调用时进行数据积累,`accumulate`计算时对积累的所有数据进行计算并返回。
结算结果会在`fit`接口的训练日志中呈现。
"""
# 利用update中积累的成员变量数据进行计算后返回
return accumulated acc value
def reset(self):
"""
7. 实现reset方法,每个Epoch结束后进行评估指标的重置,这样下个Epoch可以重新进行计算。
"""
# do reset action
这个是框架中已提供的一个评估指标计算接口,这里就是按照上述说明中的实现方法进行了相关类继承和成员函数实现。
2.4.3 自定义Callback
这里我们简单介绍自定义Callback。
fit接口的callback参数支持我们传一个Callback类实例,用来在每个epoch训练和每个batch训练前后进行调用,以此收集训练过程中的一些数据和参数,或者实现一些自定义操作。如对于模型保存而言,正常情况下,fit只会保存模型最后一次迭代的参数。然而实际情况中,往往我们需要保存多个模型,从中选择效果最好的那个。
这时,我们可以通过框架预定义的ModelCheckpoint回调函数,可以在fit训练模型时自动存储每轮训练得到的模型。
class ModelCheckpoint(paddle.callbacks.Callback):
def __init__(self, save_freq=1, save_dir=None):
self.save_freq = save_freq
self.save_dir = save_dir
def on_epoch_begin(self, epoch=None, logs=None):
self.epoch = epoch
def _is_save(self):
return self.model and self.save_dir and ParallelEnv().local_rank == 0
def on_epoch_end(self, epoch, logs=None):
if self._is_save() and self.epoch % self.save_freq == 0:
path = '{}/{}'.format(self.save_dir, epoch)
print('save checkpoint at {}'.format(os.path.abspath(path)))
self.model.save(path)
def on_train_end(self, logs=None):
if self._is_save():
path = '{}/final'.format(self.save_dir)
print('save checkpoint at {}'.format(os.path.abspath(path)))
self.model.save(path)
2.4.4 自定义执行过程回调
有时,我们需要保存模型训练过程中loss下降的信息,绘成图来分析网络模型的优化过程,这个在高层API中该如何实现呢?其实,这里也会用到上文提到的自定义Callback,我们只需要自定义与loss相关的Callback,然后保存loss信息,最后将其转化为图片即可。具体的实现过程如下:
# 定义 数据集与模型
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
from paddle.vision.datasets import MNIST
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = T.Normalize(mean=[127.5], std=[127.5])
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test', transform=transform)
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())# 自定义Callback 记录训练过程中的loss信息
class LossCallback(paddle.callbacks.Callback):
def on_train_begin(self, logs={}):
# 在fit前 初始化losses,用于保存每个batch的loss结果
self.losses = []
def on_train_batch_end(self, step, logs={}):
# 每个batch训练完成后调用,把当前loss添加到losses中
self.losses.append(logs.get('loss'))
# 初始化一个loss_log 的实例,然后将其作为参数传递给fit
loss_log = LossCallback()
model.fit(train_dataset,
epochs=5,
batch_size=32,
# callbacks=loss_log,
verbose=1)
# loss信息都保存在 loss_log.losses 中,可视化后得到下图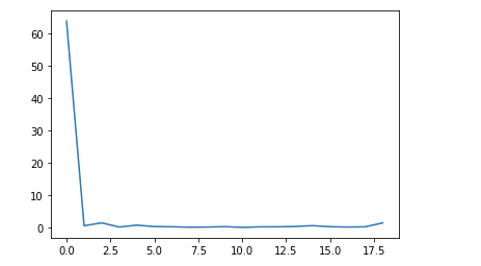
2.5、模型可视化
在我们完成模型的构建后,有时还需要可视化模型的网络结构与训练过程,来直观的了解深度学习模型与训练过程,方便我们更好地优化模型。飞桨框架高层API提供了一系列相关的API,来帮助我们可视化模型与训练过程,就让我们来看一下吧。
2.5.1 模型结构可视化
在飞桨框架中,对于我们组网的模型,只要我们用Model进行模型的封装后,只需要调用 model.summary 即可实现网络模型的可视化,具体如下:
import paddle
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
model.summary((1, 28, 28))---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Flatten-51264 [[1, 28, 28]] [1, 784] 0
Linear-9 [[1, 784]] [1, 512] 401,920
ReLU-5 [[1, 512]] [1, 512] 0
Dropout-5 [[1, 512]] [1, 512] 0
Linear-10 [[1, 512]] [1, 10] 5,130
===========================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.02
Params size (MB): 1.55
Estimated Total Size (MB): 1.57
---------------------------------------------------------------------------
{'total_params': 407050, 'trainable_params': 407050}2.5.2 使用VisualDL完成训练过程的可视化
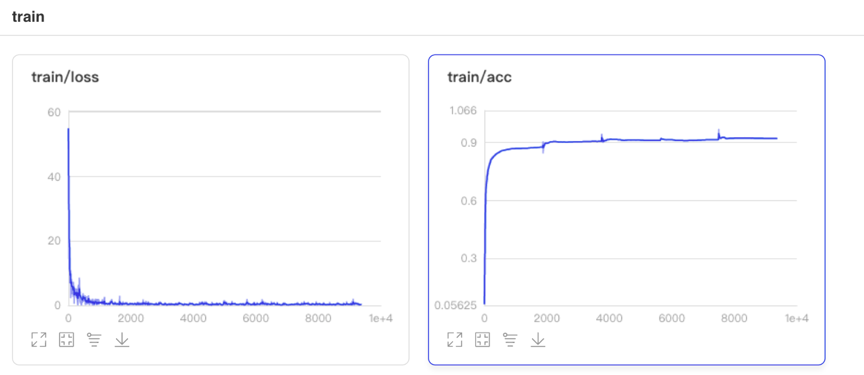
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、直方图以及PR曲线等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。是飞桨模型可视化的大杀器。飞桨高层API也做了与VisualDL的联动,也仅仅需要一行代码,就可以轻松使用VisualDL完成模型训练过程的分析。具体如下:
# 调用飞桨框架的VisualDL模块,保存信息到目录中。
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
model.fit(train_dataset,
epochs=5,
batch_size=32,
callbacks=callback,
verbose=1)然后打开VisualDL工具

【1】paddle飞桨框架高层API使用讲解的更多相关文章
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- 百度飞桨数据处理 API 数据格式 HWC CHW 和 PIL 图像处理之间的关系
使用百度飞桨 API 例如:Resize Normalize,处理数据的时候. Resize:如果输入的图像是 PIL 读取的图像这个数据格式是 HWC ,Resize 就需要 HWC 格式的数据. ...
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
参考文章: 深度剖析知识增强语义表示模型--ERNIE_财神Childe的博客-CSDN博客_ernie模型 ERNIE_ERNIE开源开发套件_飞桨 https://github.com/Pad ...
- Flask 框架下 Jinja2 模板引擎高层 API 类——Environment
Environment 类版本: 本文所描述的 Environment 类对应于 Jinja2-2.7 版本. Environment 类功能: Environment 是 Jinja2 中的一个 ...
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- Ubuntu 百度飞桨和 CUDA 的安装
Ubuntu 百度飞桨 和 CUDA 的安装 1.简介 本文主要是 Ubuntu 百度飞桨 和 CUDA 的安装 系统:Ubuntu 20.04 百度飞桨:2.2 为例 2.百度飞桨安装 访问百度飞桨 ...
- 我做的百度飞桨PaddleOCR .NET调用库
我做的百度飞桨PaddleOCR .NET调用库 .NET Conf 2021中国我做了一次<.NET玩转计算机视觉OpenCV>的分享,其中提到了一个效果特别好的OCR识别引擎--百度飞 ...
- 最新30系显卡搭建paddle飞浆环境|含CUDA下载安装
下载CUDA 通过这个链接可以下载任意CUDA版本:CUDA Toolkit Archive | NVIDIA Developer 我下载的是这一个:https://developer.downloa ...
- 飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节.因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推 ...
- Yii2框架RESTful API教程(二) - 格式化响应,授权认证和速率限制
之前写过一篇Yii2框架RESTful API教程(一) - 快速入门,今天接着来探究一下Yii2 RESTful的格式化响应,授权认证和速率限制三个部分 一.目录结构 先列出需要改动的文件.目录如下 ...
随机推荐
- signed main 和 int main 的区别
事实上只是因为有人直接 #define int long long 了...然后int main改成signed main就行了 #define int long long ... signed ma ...
- AtCoder Beginner Contest 210 (A~E)
比赛链接:Here A - Cabbages 略 B - Bouzu Mekuri 略 C - Colorful Candies 用map维护连续一段区间的不同元素即可. int main() { c ...
- 2016年第七届 蓝桥杯A组 C/C++决赛题解
蓝桥杯历年国赛真题汇总:Here 1.随意组合 小明被绑架到X星球的巫师W那里. 其时,W正在玩弄两组数据 (2 3 5 8) 和 (1 4 6 7) 他命令小明从一组数据中分别取数与另一组中的数配对 ...
- TapTap 算法平台的 Serverless 探索之路
分享人:陈欣昊,TapTap/IEM/AI平台负责人 摘要:本文主要介绍心动网络算法平台在Serverless上的实践. <TapTap算法平台的 Serverless 探索之路> Ser ...
- 《深入理解计算机系统》实验五 —— Perfom Lab
本次实验是CSAPP的第5个实验,这次实验主要是让我们熟悉如何优化程序,如何写出更具有效率的代码.通过这次实验,我们可以更好的理解计算机的工作原理,在以后编写代码时,具有能结合软硬件思考的能力. @ ...
- shell脚本(9)-流程控制for
一.循环介绍 for循环叫做条件循环,或者for i in,可以通过for实现流程控制 二.for语法 1.for语法一:for in for var in value1 value2 ...... ...
- java基础(3)--pulic class与class的区别
1.一个类前面的public是可有可无的2.如果一个类使用 public 修饰,则文件名必须与类名一致3.如果一个类前面没有使用public修饰,则文件名可以与类名不一致.当编译成功后会生成对应类名的 ...
- MySQL 及调优
存储引擎的种类 MySQL 中存在多种存储引擎,比如: InnoDB 支持事务: 支持外键: 同时支持行锁和表锁. 适用场景:经常更新的表,存在并发读写或者有事务处理的业务场景. MyISAM 支持表 ...
- Vue2.x项目整合ExceptionLess监控
前言 一直以来我们都是用Sentry做项目监控,不过前段时间我们的Sentry坏掉了(我搞坏的) 但监控又是很有必要的,在sentry修好之前,我想先寻找一个临时的替代方案,同时发现网上关于Excep ...
- 【面试题精讲】JVM中有哪些垃圾收集器
有时博客内容会有变动,首发博客是最新的,其他博客地址可能未同步,请认准https://blog.zysicyj.top 首发博客地址 系列文章地址 在Java虚拟机(JVM)中,有以下几种常见的垃圾收 ...