飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节。因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推理实现,于是我就在C下把这个方案的部署实现了。需要说明的是目前完成的是浮点实现,真正部署时要用的是定点实现,后面要做的是从浮点到定点的转换。浮点实现也做了两个版本。一是跟python下的实现完全一致的版本,做这个版本的目的是方便与python版本的结果比较,确保每个模块的实现完全正确。二是将模型中的卷积层和对应的batchNormal(BN)层合并为一个卷积层的版本,将卷积层和对应的BN层合并为一个卷积层一是可以减少参数的个数,二是可以减少运算量(BN里有求方差等运算)。做定点化时也是要基于这个版本来做的。下面就讲讲我是怎么做C下的实现的。
语音唤醒的推理过程如下图所示:

从上图可以看出主要分两步,一是做特征提取,二是做模型推理。将提取出来的特征值作为模型的输入,推理后得到模型的输出,从而给出是否是关键词的结果。
1, 特征提取
特征提取的步骤如下图所示:

做这一步时主要基于两份开源的代码: FFT 和 MFCC。Fbank是MFCC的一部分,因此需要对代码进行裁剪。做时从分帧开始到得到特征值,每一步处理都要跟python下的保持完全一致,如分帧时用的是什么窗,用的是能量谱还是对数谱等。调试时基于一个具体的WAV文件来调。每一步执行后python下有一个输出,在C下也有一个输出,要确保这两个输出在误差允许范围内保持一致,否则就是C的实现有问题。经过调试后特征提取部分就完成了,python下的结果和C下的结果保持小数点后面前四位相同,误差还是非常小的。
2, 模型推理
模型推理可以分为如下几个步骤:在Python下获取模型参数并保存进文件给C实现用,跟python完全一致的浮点实现,将卷积层和对应的BN层合并为一个卷积层的浮点实现。
2.1 模型参数获取
在paddlespeech下先用API获取每层的参数,代码大致如下:

然后将每层的参数按事先规定的格式保存在一个文件里,供C实现去解析参数。我用的参数保存格式如下:

即参数一层一层的放。在每一层里,先是层名,然后是weight参数的个数和bias参数的个数,最后是weight和bias具体的参数值。在C中就根据这个规则去解析从而得到每一层的参数。
2.2 跟python推理完全一致的浮点实现
模型的框图如下:
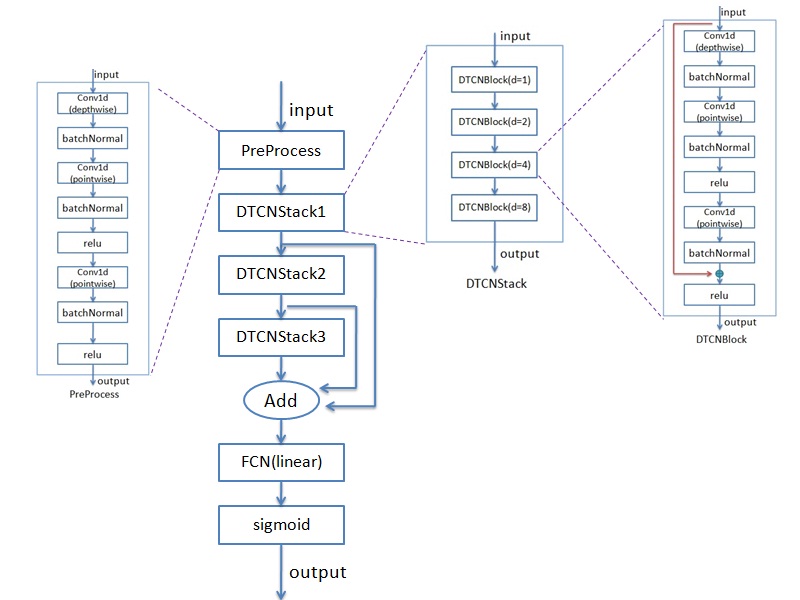
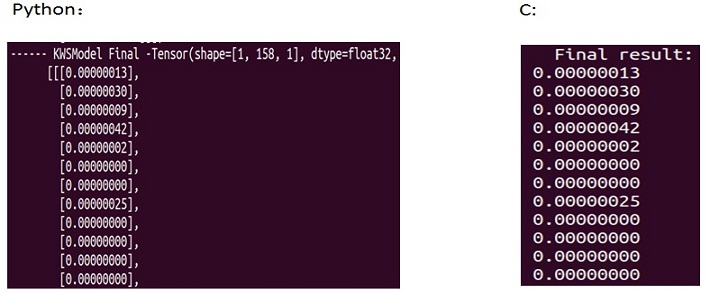
主要有PreProcess/DTCNStack等模块。先实现模型用到的神经网络里的基本单元,有depthwise_conv1d/pointwise_conv1d/relu/batch_normal/sigmoid等。再将这些基本单元组成pre_process模块来调试。依旧是用调试特征提取时的方法来调,确保每一步的输出跟python下的在误差允许范围内保持一致。PreProcess模块调好后再来调DTCNStack等模块,最终形成一个完整的推理实现。下图给出了我调试时用的wav的最终每帧的在python下和C下的后验概率(有多个值,限于长度,这里只截取了部分),可以看出python下和C下的结果是保持一致的。
2.3将卷积层和对应的BN层合并为一个卷积层的浮点实现
为了减少参数个数和运算量,可以将将卷积层和对应的BN层合并为一个卷积层。具体原理如下:
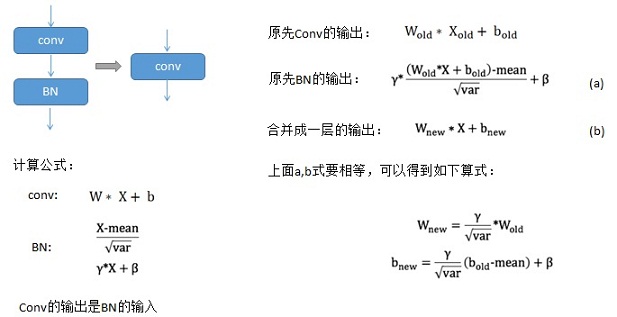
对于C实现来说,只要把banch_normal()函数去掉就可以了。但是在保存参数时卷积层的参数要根据上面的公式做个换算,同时把BN层的去掉。下图是做最后linear以及后验概率运算时有没有BN层的结果(有多个值,限于长度,这里只截取了部分)。
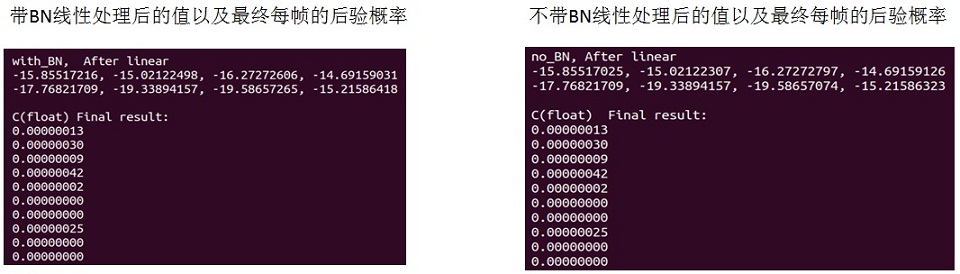
从上两图看出将卷积层和BN层合并为一层对最终结果的影响是非常小的,但是省掉了2.5K的参数以及原先BN层要做的运算量。
飞桨paddlespeech语音唤醒推理C实现的更多相关文章
- 讯飞语音唤醒SDK集成流程
唤醒功能,顾名思义,通过语音,唤醒服务,做我们想做的事情. 效果图(开启应用后说讯飞语音或者讯飞语点唤醒) 源码下载 地址:http://download.csdn.net/detail/q48788 ...
- android 开发 讯飞语音唤醒功能
场景:进入程序后处于语音唤醒状态,当说到某个关键词的时候打开某个子界面(如:语音识别界面) 技术要点: 1. // 设置唤醒一直保持,直到调用stopListening,传入0则完成一次唤醒后,会话立 ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- 树莓派4B安装 百度飞桨paddlelite 做视频检测 (一、环境安装)
前言: 当前准备重新在树莓派4B8G 上面搭载训练模型进行识别检测,训练采用了百度飞桨的PaddleX再也不用为训练部署环境各种报错发愁了,推荐大家使用. 关于在树莓派4B上面paddlelite的文 ...
- 百度飞桨数据处理 API 数据格式 HWC CHW 和 PIL 图像处理之间的关系
使用百度飞桨 API 例如:Resize Normalize,处理数据的时候. Resize:如果输入的图像是 PIL 读取的图像这个数据格式是 HWC ,Resize 就需要 HWC 格式的数据. ...
- Ubuntu 百度飞桨和 CUDA 的安装
Ubuntu 百度飞桨 和 CUDA 的安装 1.简介 本文主要是 Ubuntu 百度飞桨 和 CUDA 的安装 系统:Ubuntu 20.04 百度飞桨:2.2 为例 2.百度飞桨安装 访问百度飞桨 ...
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
参考文章: 深度剖析知识增强语义表示模型--ERNIE_财神Childe的博客-CSDN博客_ernie模型 ERNIE_ERNIE开源开发套件_飞桨 https://github.com/Pad ...
- porcupine语音唤醒python实现
note it is not for arm pyaudio <= 3.6 version porcupine 3.5 3.6 not 3.7 code import struct import ...
- Paddle Inference原生推理库
Paddle Inference原生推理库 深度学习一般分为训练和推理两个部分,训练是神经网络"学习"的过程,主要关注如何搜索和求解模型参数,发现训练数据中的规律,生成模型.有了训 ...
随机推荐
- Java简单认识及环境下载
Java的特性和优势 简单性 面向对象 可移植性 跨平台性 write once run anywhere 高性能 分布式 动态性 反射 多线程 安全性 健壮性 Java三大版本 JavaSE:标准版 ...
- ABP vNext微服务架构详细教程——分布式权限框架
1.简介 ABP vNext框架本身提供了一套权限框架,其功能非常丰富,具体可参考官方文档:https://docs.abp.io/en/abp/latest/Authorization 但是我们使用 ...
- Unity递归查找子物体
- 在创建maven项目时提示找不到插件 'org.springframework.boot:spring-boot-maven-plugin:'
因为是版本号缺失,不过我idea自建项目没这个问题,但是从springboot官网上创建下载就出现了这个问题. 找到文件夹的打开pom.xml文件 然后找到下图位置添加版本号,我的是2.6.1 添加完 ...
- SQLServer游标(Cursor)简单例子
DECLARE @username nvarchar(50),@password nvarchar(50),@num int--声明游标变量 DECLARE myCursor CURSOR FOR s ...
- windows下使用Wireshark调试chrome浏览器的HTTP/2流量
1.在Wireshark官网(https://www.wireshark.org/#download)下载对应的Wireshark安装包,进行安装 2.增加系统环境变量设置(计算机 -- 右键 -- ...
- IBM 双队列管理器,双向传输
1. 建立队列管理器 建立[test01][test02]两个队列管理器,一直下一步即可,端口号不能一致(需要记住设置的端口号,后面会用到) [test01]端口号 1414 [test02]端口号 ...
- 摘记:找到程式中 不會被執行到的 code
定义 https://en.wikipedia.org/wiki/Unreachable_codeRemove unreachable code refactoringhttps://docs.mic ...
- 初识Node和内置模块
初识Node与内置模块 概述:了解Node.js,熟悉内置模块:fs模块.path模块.http模块 初识Node.js 浏览器中的JavaScript运行环境 运行环境是指代码正常运行所需的必要环境 ...
- nginx的location与proxy_pass配置超详细讲解及其有无斜杠( / )结尾的区别
本文所使用的环境信息如下: windows11 (主机系统) virtual-box-7.0环境下的ubuntu-18.04 nginx-1.22.1 (linux) 斜杠结尾之争 实践中,nginx ...