【0基础学爬虫】爬虫基础之自动化工具 Playwright 的使用

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为自动化工具 playwright 的使用。
概述
上期文章中讲到了自动化工具 Selenium 的基本使用方法,也介绍了 Selenium 的优缺点。Selenium的功能非常强大,支持所有现代浏览器。但是 Selenium 使用起来十分不方便,我们需要提前安装好浏览器,然后下载对应版本的驱动文件,当浏览器更新后驱动文件也得随之更新。如果想要大规模且长期的采集数据,那么部署 Selenium 时环境配置会是一个大问题。因此本期我们将介绍一款更加好用的自动化工具 Playwright 。
Playwright 的使用
介绍
Playwright是一个用于自动化Web浏览器测试和Web数据抓取的开源库。它由Microsoft开发,支持Chrome、Firefox、Safari、Edge和WebKit浏览器。Playwright的一个主要特点是它能够在所有主要的操作系统(包括Windows、Linux和macOS)上运行,并且它提供了一些强大的功能,如跨浏览器测试、支持无头浏览器、并行执行测试、元素截图和模拟输入等。它主要有以下优势:
- 兼容多个浏览器,而且所有浏览器都使用相同的API。
- 速度快、稳定性高,即使在大型、复杂的Web应用程序中也可以运行。
- 支持无头浏览器,因此可以在没有可见界面的情况下运行测试,从而提高测试效率。
- 提供了丰富的 API,以便于执行各种操作,如截图、模拟输入、拦截网络请求等。
安装
使用 Playwright 需要 Python版本在3.7以上。
安装 Playwright 可以直接使用 pip 工具:
pip install playwright
安装完成后需要进行初始化操作,安装所需的浏览器。
playwright install
执行上述指令时,Playwright 会自动安装多个浏览器(Chromium、Firefox 和 WebKit)并配置驱动,所以速度较慢。
使用
Playwright 支持同步与异步两种模式,这里分开来进行讲解。
同步
使用 Playwright 时可以选择启动安装的三种浏览器(Chromium、Firefox 和 WebKit)中的一种。
from playwright.sync_api import sync_playwright
# 调用sync_playwright方法,返回浏览器上下文管理器
with sync_playwright() as p:
# 创建谷歌浏览器示例,playwright默认启动无头模式,设置headless=False,即关闭无头模式
browser = p.chromium.launch(headless=False)
# 新建选项卡
page = browser.new_page()
# 跳转到目标网址
page.goto("http://baidu.com")
# 获取页面截图
page.screenshot(path='example.png')
# 打印页面的标题,也就是title节点中的文本信息
print(page.title())
# 关闭浏览器
browser.close()
# 输出:百度一下,你就知道
可以看到,Playwright 的使用也比较简单,语法比较简洁,而且浏览器的启动速度以及运行速度也很快。
异步
异步代码的编写方法与同步基本一致,区别在于同步调用的是 sync_playwright,异步调用的是 async_playwright。最终运行效果与同步一致。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("http://baidu.com")
# 打印网页源代码
print(await page.content())
await browser.close()
asyncio.run(main())
代码生成
Playwright 提供了代码生成功能,这个功能可以对我们在浏览器上的操作进行录制并生成代码,它可以有效提高程序的编写效率。代码生成功能需要使用 Playwright 命令行中的 codegen实现,codegen 命令存在如下主要参数:
-o :将生成的脚本保存到指定文件
--target :生成的语言,默认为 Python
--save-trace :记录会话的跟踪并将其保存到文件中
-b :要使用的浏览器,默认为 chromium
--timeout :设置页面加载的超时时间
--user-agent :指定UA
--viewport-size :指定浏览器窗口大小
我们在命令行执行命令:playwright codegen -o script.py
执行命令后会弹出一个 chromium 浏览器与脚本窗口,当我们在浏览器上进行操作时,脚本窗口会根据我们的操作生成对应代码。当我们操作结束后,关闭浏览器,在当前目录下会生成一个 script.py 文件,该文件中就是我们在进行浏览器操作时,Playwright 录制的代码。我们运行该文件,就会发现它在复现我们之前的操作。
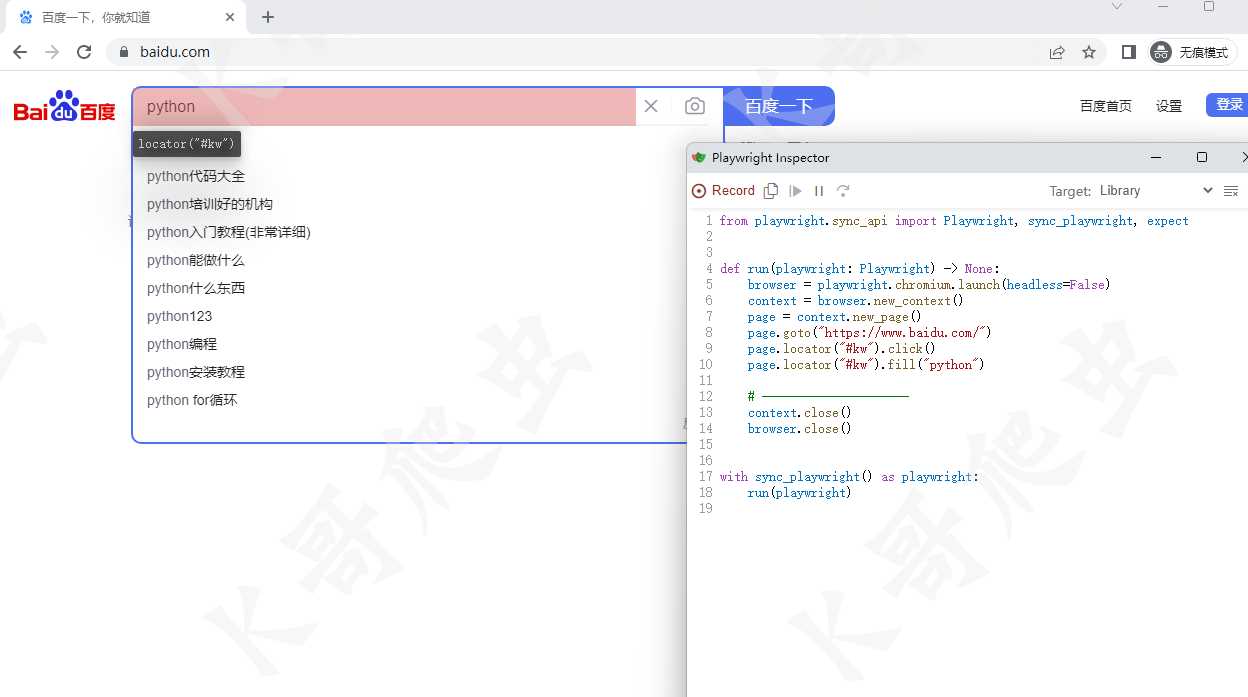
代码生成功能的实用性其实较为一般,它只能实现比较简单的操作,当遇到复杂操作时,生成的代码就容易出现问题。最好的方式是使用代码生成功能生成部分操作的代码,然后再手动去修改它生成的代码。
隔离
上一步中,我们使用代码生成功能生成了一段代码,我们会发现这段代码中使用到了一个 new_context 方法,通过这个方法创建了一个 content ,然后再去进行其它操作。这个 new_content 方法其实是为了创建一个独立的全新上下文环境,它的目的是为了防止多个测试用例并行时各个用例间不受干扰,当一个测试用例异常时不会影响到另一个。
browser = playwright.chromium.launch()
context = browser.new_context()
page = context.new_page()
定位器
Playwright 提供了多种定位器来帮助开发中定位元素。
page.get_by_role() :通过显式和隐式可访问性属性进行定位。
page.get_by_text() :通过文本内容定位。
page.get_by_label() :通过关联标签的文本定位表单控件。
page.get_by_placeholder() :按占位符定位输入。
page.get_by_alt_text() :通过替代文本定位元素,通常是图像。
page.get_by_title() :通过标题属性定位元素。
page.get_by_test_id() :根据data-testid属性定位元素(可以配置其他属性)。
page.locator():拓展选择器,可以使用 CSS 选择器进行定位
使用定位器最好的方式就是上文中讲到的利用代码生成功能来生成定位代码,然后手动去修改,这里就不做尝试。
选择器
Playwright 支持 CSS、Xpath 和一些拓展选择器,提供了一些比较方便的使用规则。
CSS 选择器
# 匹配 button 标签
page.locator('button').click()
# 根据 id 匹配,匹配 id 为 container 的节点
page.locator('#container').click()
# CSS伪类匹配,匹配可见的 button 按钮
page.locator("button:visible").click()
# :has-text 匹配任意内部包含指定文本的节点
page.locator(':has-text("Playwright")').click()
# 匹配 article 标签内包含 products 文本的节点
page.locator('article:has-text("products")').click()
# 匹配 article 标签下包含类名为 promo 的 div 标签的节点
page.locator("article:has(div.promo)").click()
Xpath
page.locator("xpath=//button").click()
page.locator('xpath=//div[@class="container"]').click()
其它
# 根据文本匹配,匹配文本内容包含 name 的节点
page.locator('text=name').click()
# 匹配文本内容为 name 的节点
page.locator("text='name'").click()
# 正则匹配
page.locator("text=/name\s\w+word").click()
# 匹配第一个 button 按钮
page.locator("button").locator("nth=0").click()
# 匹配第二个 button 按钮
page.locator("button").locator("nth=-1").click()
# 匹配 id 为 name 的元素
page.locator('id=name')
等待
当进行 click 、fill 等操作时,Playwright 在采取行动之前会对元素执行一系列可操作性检测,以确保这些行动能够按预期进行。
如对元素进行 click 操作之前,Playwright 将确保:
元素附加到 DOM
元素可见
元素是稳定的,因为没有动画或完成动画
元素接收事件,因为没有被其他元素遮挡
元素已启用
即使 Playwright 已经做了充分准备,但是也并不完全稳定,在实际项目中依旧容易出现因页面加载导致事件没有生效等问题,为了避免这些问题,需要自行设置等待。
# 固定等待1秒
page.wait_for_timeout(1000)
# 等待事件
page.wait_for_event(event)
# 等待加载状态
page.get_by_role("button").click()
page.wait_for_load_state()
事件
添加/删除事件
from playwright.sync_api import sync_playwright
def print_request_sent(request):
print("Request sent: " + request.url)
def print_request_finished(request):
print("Request finished: " + request.url)
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 添加事件 发起请求时打印URL
page.on("request", print_request_sent)
# 请求完成时打印URL
page.on("requestfinished", print_request_finished)
page.goto("https://baidu.com")
# 删除事件
page.remove_listener("requestfinished", print_request_finished)
browser.close()
反检测
在 Selenium 的使用中,我们讲到了自动化工具容易被网站检测,也提供了一些绕过检测的方案。这里我们介绍一下 Playwright 的反检测方案。
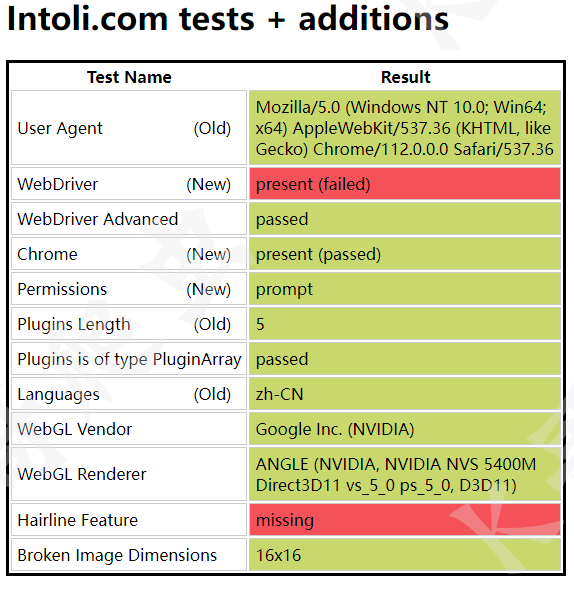
以 https://bot.sannysoft.com/ 为例,我们分别测试正常模式与无头模式下的检测结果。
正常模式:
无头模式:
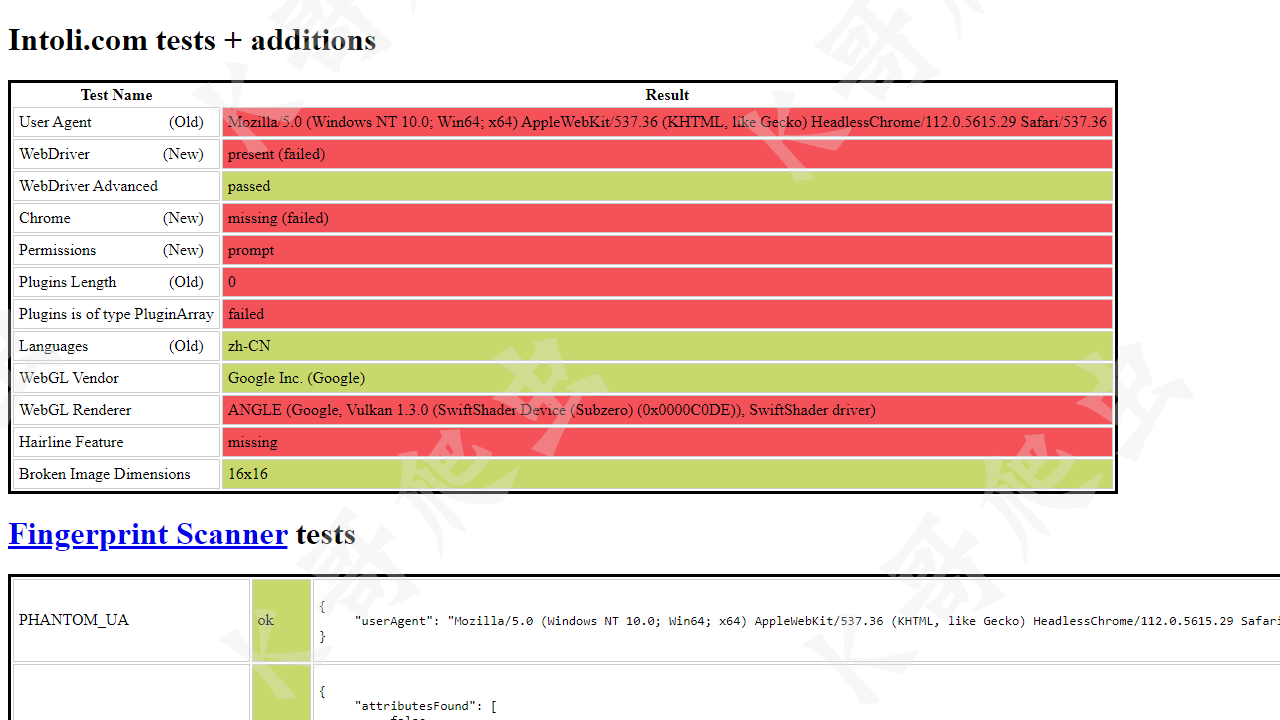
可以看到,正常模式下 WebDriver 一栏报红,而无头模式下更是惨不忍睹,基本上所有特征都被检测到了。这些还只是最基本的检测机制,自动化工具的弱点就暴露的很明显了。
与 Selenium 一样,绕过检测主要还是针对网站的检测机制来处理,主要就是在页面加载之前通过执行 JS 代码来修改一些浏览器特征。以无头模式为例:
from playwright.sync_api import sync_playwright
with open('./stealth.min.js', 'r') as f:
js = f.read()
with sync_playwright() as p:
browser = p.chromium.launch()
# 添加 UserAgent
page = browser.new_page(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
)
# 执行 JS 代码
page.add_init_script(js)
page.goto("https://bot.sannysoft.com/")
page.screenshot(path='example.png')
browser.close()
这里与 Selenium 反检测方案一样,执行 stealth.min.js 来隐藏特征( stealth.min.js 的来源与介绍参考上期文章)。最终结果如下图:
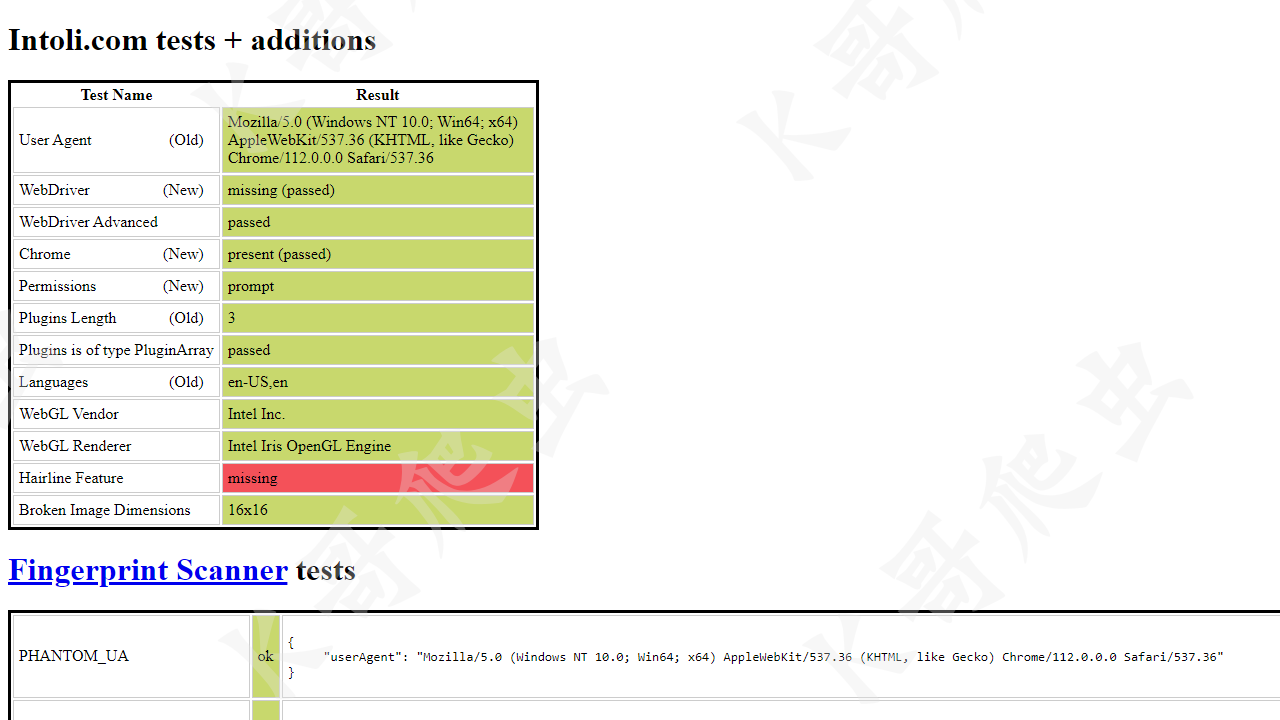
可以看到,与真实浏览器访问基本一致了。
总结
与 Selenium 相比,Playwright 最大的优点就是不需要手动安装驱动,而且它拥有更好的性能与更多的功能。因此 在爬虫领域,Playwright 是更好的选择。
【0基础学爬虫】爬虫基础之自动化工具 Playwright 的使用的更多相关文章
- 零基础学python,python视频教程
零基础学python,python视频教程 这是我收集到的互联网上的视频资源,所有内容均来自互联网.仅供学习使用. 目前我在也在学习过程中,会把学习过程中遇到问题以及解决问题的方式,总结到我的公众号[ ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 小白学 Python 爬虫(3):前置准备(二)Linux基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 Linux 基础 CentOS 官网: https: ...
- 小白学 Python 爬虫(4):前置准备(三)Docker基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(9):爬虫基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(12):urllib 基础使用(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(13):urllib 基础使用(三)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(14):urllib 基础使用(四)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(17):Requests 基础使用
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 火山引擎智能外呼联合火山引擎VeDI升级服务,让企业精准营销不再难
企业营销模式正在经历一场巨变.数字化营销早已替代传统的营销方式,成为企业营销的主流方式和发展战略中不可或缺的部分.然而随着数字化营销的普及,市场迈入存量竞争时代,获客成本也逐年攀升.面对营销过程中不断 ...
- CPU--实模式与保护模式
一.实模式(实地址访问模式) 是Intel公司80286及以后的x86(80386,80486和80586等)兼容处理器(CPU)的一种操作模式. 实模式被特殊定义为20位地址内存可访问空间上,这就意 ...
- Android 加载图片占用内存分析
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/aRDzmMlkqB14Ty67GJs9vg作者:Xu Jie 不同Android版本,对一张图 ...
- 密码加密bcrypt
- v-cloak指令用法
插值表达式存在的问题:'闪动' 如何解决该问题:使用v-cloak指令 解决该问题的原理:先隐藏,替换好值之后再显示最终的值 背后的原理:先通过样式隐藏内容,然后在内存中进行值得替换,替换好之后再显示 ...
- 使用命令行方式搭建uni-app + Vue3 + Typescript + Pinia + Vite + Tailwind CSS + uv-ui开发脚手架
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- 25-IP核简介
1.IP IP(Intellectual Property)即知识产权,在半导体产业中讲IP核定义为用于"ASIC或FPGA中的预先设计好的电路功能模块".简言之,这里的IP即电路 ...
- JVM内存用量的再学习
JVM内存用量的再学习 背景 最近解决一个SQLServer的问题耗时很久. 最终找到了一个看似合理的问题解释. 但是感觉不能只是总结于数据库方面 因为为了解决这个问题增加了很多监控措施. 所以想就这 ...
- [转帖]关于面试时HA(RAC)会问到的一些问题
1.什么是RAC(Real Application Cluster)? RAC(Real Application Cluster)是Oracle数据库的一种部署架构,它将多个数据库服务器连接在一起,共 ...
- [转帖]MySQL Decimal 的实现方法
码: 背景 数字运算在数据库中是很常见的需求, 例如计算数量.重量.价格等, 为了满足各种需求, 数据库系统通常支持精准的数字类型和近似的数字类型. 精准的数字类型包含 int, decimal 等, ...