Rank & Sort Loss for Object Detection and Instance Segmentation 论文解读(含核心源码详解)
第一印象
Rank & Sort Loss for Object Detection and Instance Segmentation 这篇文章算是我读的 detection 文章里面比较难理解的,原因可能在于:创新的点跟普通的也不太一样;文章里面比较多公式。但之前也有跟这方面的工作如 AP Loss、aLRPLoss 等。它们都是为了解决一个问题:单阶段目标检测器分类和回归在训练和预测不一致的问题。那么 Rank & Sort Loss 又在以上的工作进行了什么改进呢?又解决了什么问题呢?
关于训练预测不一致的问题
简单来说,就是在分类和回归在训练的时候是分开的训练,计算 loss 并进行反向优化。但是在预测的时候却是用分类分数排序来进行 nms 后处理。这里可能导致一种情况就是分类分数很高,但是回归不好(这个问题在 FCOS 中有阐述)。
之前的工作
常见的目标检测网络一般会使用 nms 作为后处理,这时我们常常希望所有正样本的得分排在负样本前面,另外我们还希望位置预测更准确的框最后被留下来。之前的 AP Loss 和 aLRP Loss 由于需要附加的 head 来进行分类精度和位置精度综合评价(其实就是为了消除分类和回归的不一致问题,如 FCOS 的 centerness、IoU head 之类的),确实在解决类别不均衡问题(正负样本不均衡)等有着不错的效果,但是需要更多的时间和数据增强来进行训练。
Rank & Sort Loss
Rank & Sort Loss (RS Loss) 并没有增加额外的辅助 head 来进行解决训练和预测不一致的问题,仅通过 RS Loss 进行简单训练:
- 通过 Sort Loss 加上 Quality Focal Loss 的启发(避免了增加额外的 head),使用 IoU 来作为分类 label,使得可以通过连续的数值 (IoU) 来作为标签给预测框中的正样本进行排序。
- 通过 Rank Loss 使得所有正样本都能排序在负样本之前,并且只选取了较高分数的负样本进行计算,在不使用启发式的采样情况下解决了正负样本不均衡的问题。
- 不需要进行多任务的权重或系数调整。
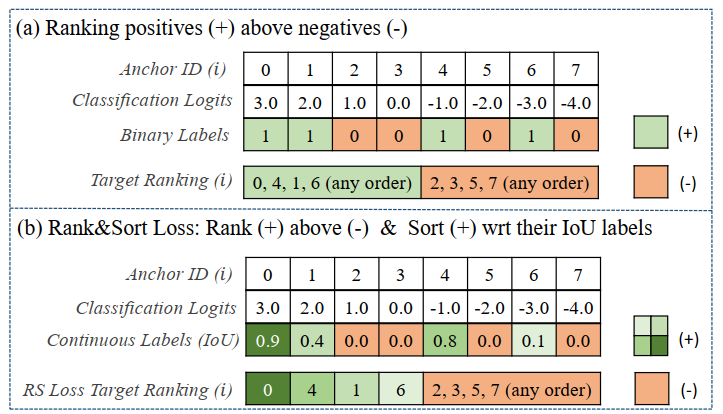
由上图可以看出,一般的标签分配正样本之间是没有区分的,但是在 RS Loss 里面正样本全部大于负样本,然后在正样本之间也会有排序,排序的依据就是 Anchor 经过调整后跟 GT 的 IoU 值。
对基于 rank 的 loss 的回顾
由于基于排序的特性,它不是连续可微。因此,常常采用了误差驱动的方式来进行反向传播。以下来复习一下如何将误差驱动优化融进反向传播:
Loss 的定义
\(\mathcal{L} = \frac{1}{Z} \underset{i \in \mathcal{P}}{\sum} \ell(i)\) ,其中 \(Z\) 是用来归一化的常数,\(\mathcal{P}\) 则是所有正样本的集合,\(\ell(i)\) 是计算正样本 \(i\) 的误差项。
Loss 的计算

Step 1. 如上图所示,误差 \(x_{ij}\) 的值为样本 \(i\) 与样本 \(j\) 的预测概率值之差。
Step 2. 用每一对样本的误差值 \(x_{ij}\) 来计算这对样本对样本 \(i\) 产生的 loss 值,由下述公式计算得到:
\[L_{ij} = \begin{cases}
\ell(i)p(j|i),\quad for\ i \ \in \mathcal{P},j \ \in \ \mathcal{N} \\
0,\qquad \qquad \ otherwise,
\end{cases}
\]其中 \(p(j|i)\) 是 \(\ell(i)\) 分布的概率密度质量函数,\(\mathcal{N}\) 则是所选负样本的集合。一般借鉴了感知学习(感知机)来进行误差驱动,因此使用了阶跃函数 \(H(x)\) 。对于第 \(i\) 个样本,\(rank(i)=\underset{j \in \mathcal{P\cup N}}{\sum} H(x_{ij})\) 为该样本在所有样本的位次,\(rank^{+}(i)=\underset{j \in \mathcal{P}}{\sum} H(x_{ij})\) 为该样本在所有正样本中的位次,\(rank^{-}(i)=\underset{j \in \mathcal{N}}{\sum} H(x_{ij})\) 为该样本在较大概率分数负样本中的位次,这个位次真值应该为 0 ,否则将产生 loss (因为所有正样本需要排在所有负样本之前),对于 AP Loss 来说 \(\ell(i)\) 和 \(p(j|i)\) 可以分别表示为 \(\frac{rank^{-}(i)}{rank(i)}\) 和 \(\frac{H(x_{ij})}{rank^{-}(i)}\) 。其中可以推断出 \(L_{ij}=\frac{H(x_{ij})}{rank(i)}\) 即样本 \(j\) 对 \(i\) 产生的 loss,这里只会在其概率分数大于样本 \(i\) 时会产生 loss。
Step 3. 计算最终的 Loss,\(\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P}}{\sum} \ell(i)=\frac{1}{Z}\underset{i \in \mathcal{P}}{\sum} \underset{j \in \mathcal{N}}{\sum} L_{ij}\) 。
Loss 的优化
优化其实就是一个求梯度的过程,这里我们可以使用链式求导法则,然而 \(L_{ij}\) 是不可微的,因此其梯度可以使用 \(\Delta x_{ij}\) ,我们可以结合上图进行以下推导:
\[\begin{aligned}
\frac{\partial \mathcal{L}}{\partial s_i} &= \sum_{j} \frac{\partial \mathcal{L}}{\partial L_{ij}} \Delta x_{ij} \frac{\partial x_{ij}}{\partial s_i} + \sum_{j} \frac{\partial \mathcal{L}}{\partial L_{ji}} \Delta x_{ji} \frac{\partial x_{ji}}{\partial s_i}\\
& = -\frac{1}{Z}\sum_{j} \Delta x_{ji} + \frac{1}{Z}\sum_{j} \Delta x_{ij} \\
& = \frac{1}{Z} \Big( \sum_{j}\Delta x_{ji} - \sum_{j}\Delta x_{ij}\Big)
\end{aligned}
\]其中 \(\Delta x_{ij}\) 可以由 \(-(L^{*}_{ij} - L_{ij})\) 计算得到并进行误差驱动更新值,其中 \(L^{*}_{ij}\) 是 GT。AP Loss 和 aLRP Loss 都是通过这种方式进行优化的。
文章对以上的部分一些改进
RS Loss 认为:
\(L^{*}_{ij}\) 不为 0 时解释性比较差(因为 \(L\) 为排序误差产生的 loss,按理来说应该没有误差是最好的,也就是 loss 为 0,那么 GT 应该为 0 才对)
关于 \(L_{ij}\) 的计算来说,只有样本 \(i\) 为正样本,\(j\) 为负样本的时候才会产生非零值,其忽略了其他情况的一些误差。
因此对 Loss Function 进行了重定义为:
\[\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P \cup N}}{\sum} (\ell(i) - \ell^{*}(i))
\]其中 \(\ell^{*}(i)\) 是期望的误差,这里其实考虑了 \(i\) 属于正负样本的不同情况,另外直接使用与期望的误差之间差值作为 loss 的值,使得目标 loss 只能向着 0 优化,解决了上述两个问题。
关于 Loss 的计算则改为:
\[\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P \cup N}}{\sum} (\ell(i) - \ell^{*}(i))p(j|i)
\]最后的 Loss 的优化,由于我们的最终 loss 目标是 0,所以 \(\Delta x_{ij} = -(L^{*}_{ij} - L_{ij}) = L_{ij}\) ,最终优化可以简化为:
\[\frac{\partial \mathcal{L}}{\partial s_i} = \frac{1}{Z} \Big( \sum_{j}L_{ji} - \sum_{j}L_{ij} \Big)
\]
Rank & Sort Loss
Loss 的定义
\]
其中 \(\ell(i)_{RS}\) 是当前 rank error 和 sort error 的累积起来的和,其可以用下式表示
\]
前一项为 rank error,后一项为 sort error,后一项对分数大于 \(i\) 的样本乘以了一个 \(1-y\) 的权重,这里的 \(y\) 是分数标签(即该样本与 GT 的 IoU 值)。这里其实使得那些分数比样本 \(i\) 大,但是分数的标签又不是特别大(回归质量不是特别好)的样本进行了惩罚使其产生较大的 error。对于误差的标签,首先 rank error 我们希望所有正样本都排在负样本之前,而这时 rank error 为 0,而对于 sort error 我们则希望只有标签分数大于样本 \(i\) 的预测分数可以比它大,从而产生 error,此时产生期望的误差(也就是回归比 \(i\) 好的样本,我们是可以容忍分数比它高的),这部分样本由于有期望的误差,在计算 loss 时会产生更小的 loss。那些分数的标签不行,但预测分数又比较大的会产生更大的 loss:
\]
同时论文还将 \(H(x_{ij})\) 平滑进入区间 \([-\delta_{RS},\delta_{RS}]\) 中,其中 \(x_{ij} = x_{ij}/2\delta_{RS} + 0.5\) 。
Loss 的计算
关于 loss 的计算同上面也是进行三部曲,最后得到:
(\ell_{R}(i) - \ell_{R}^{*}(i))p_{R}(j|i),\quad for\ i \in \mathcal{P},j\ \in \mathcal{N} \\
(\ell_{S}(i) - \ell_{S}^{*}(i))p_{S}(j|i),\quad for\ i \in \mathcal{P},j\ \in \mathcal{P} \\
0, \quad \qquad \qquad \qquad \qquad \ ohterwise
\end{cases}
\]
其中
p_{R}(j|i)&=\frac{H(x_{ij})}{\underset{k \in \mathcal{N}}{\sum} H(x_{ik})} =\frac{H(x_{ij})}{rank^{-}(i)} \\
p_{S}(j|i)&=\frac{H(x_{ij})[y_j < y_i]}{\underset{k \in \mathcal{P}}{\sum} H(x_{ik})[y_k < y_i]}
\end{aligned}
\]
这里对于 rank 的概率质量函数只会统计分数大于 \(i\) 的样本,这里其实和之前没有什么区别;对于 sort 而言概率质量函数只会统计分数大于 \(i\) 且分数的标签小于 \(i\) 的样本。
以上的 loss 计算则变为:
\frac{rank^{-}(i)}{rank(i)}\frac{H(x_{ij})}{rank^{-}(i)},\quad \qquad \qquad \ \qquad \qquad \ \qquad \qquad \qquad \quad \ for\ i \in \mathcal{P},j\ \in \mathcal{N} \\
\Big(\frac{\underset{j \in \mathcal{P}}{\sum} H(x_{ij})(1 - y_j)}{rank^{+}(i)} - \frac{\underset{j \in \mathcal{P}}{\sum} H(x_{ij})[y_j\ge y_i](1 - y_j)}{H(x_{ij})[y_j\ge y_i]}\Big)\frac{H(x_{ij})[y_j < y_i]}{\underset{k \in \mathcal{P}}{\sum} H(x_{ik})[y_k < y_i]},\quad for\ i \in \mathcal{P},j\ \in \mathcal{P} \\
0, \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \ ohterwise
\end{cases}
\]
Loss 的优化
对于 \(i \in \mathcal{N}\) 时,
根据上式中的 \(L_{ij}\) 的计算规则,实际上我们只需要计算 rank 产生的 loss 就好,因为 sort 产生的 loss 只会在正样本之间计算,而 rank 产生的 loss 需要正样本对所有负样本的计算,因此只有 \(j\ \in \mathcal{P}, i \ \in \mathcal{N}\) 符合(注意这里的顺序噢,\(i,j\) 就不行噢):
\frac{\partial L_{RS}}{\partial s_i} &= \frac{1}{|\mathcal{P}|} \Big(-\underset{j \in \mathcal{P}}{\sum}L_{ij}+\underset{j \in \mathcal{P}}{\sum}L_{ji}-\underset{j \in \mathcal{N}}{\sum}L_{ij}+\underset{j \in \mathcal{N}}{\sum}L_{ji}\Big) \\
&= \frac{1}{|\mathcal{P}|}\underset{j \in \mathcal{P}}{\sum}\Big(\ell_{R}(i)-\ell^{*}_{R}(i)\Big)p_{R}(i|j) \\
&= \frac{1}{|\mathcal{P}|}\underset{j \in \mathcal{P}}{\sum}\ell_{R}(i)p_{R}(i|j)
\end{aligned}
\]
对于 \(i \in \mathcal{P}\) 时,
这时候只有 \(j\ \in \mathcal{N}, i \ \in \mathcal{P}\) 这种情况是不行的(因为这样就是计算每一个负样本与所有正样本的 loss 了):
\frac{\partial L_{RS}}{\partial s_i} &= \frac{1}{|\mathcal{P}|} \Big(-\underset{j \in \mathcal{P}}{\sum}L_{ij}+\underset{j \in \mathcal{P}}{\sum}L_{ji}-\underset{j \in \mathcal{N}}{\sum}L_{ij}+\underset{j \in \mathcal{N}}{\sum}L_{ji}\Big) \\
&= \frac{1}{|\mathcal{P}|}\Big(-\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(i) - \ell_{S}^{*}(i))p_{S}(j|i)+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) - \ell_{S}^{*}(j))p_{S}(i|j)-\underset{j \in \mathcal{P}}{\sum}(\ell_{R}(i) - \ell_{R}^{*}(i))p_{R}(j|i)+0\Big) \\
&= \frac{1}{|\mathcal{P}|}\Big(-(\ell_{S}(i) - \ell_{S}^{*}(i))\underset{j \in \mathcal{P}}{\sum}p_{S}(j|i)+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) - \ell_{S}^{*}(j))p_{S}(i|j)-(\ell_{R}(i) - \ell_{R}^{*}(i))\underset{j \in \mathcal{P}}{\sum}p_{R}(j|i)+0\Big) \\
&=\frac{1}{|\mathcal{P}|}\Big(-(\ell_{S}(i) - \ell_{S}^{*}(i))+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) - \ell_{S}^{*}(j))p_{S}(i|j)-(\ell_{R}(i) - \ell_{R}^{*}(i))+0\Big) \\
&=\frac{1}{|\mathcal{P}|}\Big((\ell_{RS}^{*}(i) - \ell_{RS}(i))+\underset{j \in \mathcal{P}}{\sum} \big(\ell(i)_{S} - \ell_{S}^{*}(i)\big)p_{S}(i|j)\Big)
\end{aligned}
\]
需要记住的是,rank 中的 loss \(L_{kl}\) 其中必须满足 \(k \in \mathcal{P},l\ \in \mathcal{N}\) ,sort 中的 loss \(L_{kl}\) 其中必须满足 \(k \in \mathcal{P},l\ \in \mathcal{P}\) 其余情况均为 0,因此一对样本要么产生 rank loss(一正样本一负),要么产生 sort (两正)
关于多任务的权重,使用下述方法避免了人工设置权重:
\]
其中 \(\lambda_{box} = \left|\mathcal{L}_{RS}/\mathcal{L}_{box} \right|\)
算法的表现
RS Loss 解决训练预测不一致以及类别不均衡等问题,思路还是挺新颖的,而且具有较好的表现。
单阶段网络的性能

两阶段网络的性能
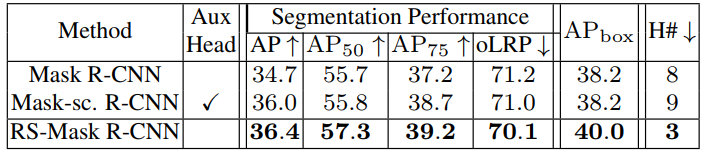
可以看到还是在下游任务上还是又不小的提升的,只得大家借鉴其思路,创新自己的工作。
核心源码解读
Rank & Sort Loss for Object Detection and Instance Segmentation 论文解读(含核心源码详解)的更多相关文章
- Sparse R-CNN: End-to-End Object Detection with Learnable Proposals 论文解读
前言 事实上,Sparse R-CNN 很多地方是借鉴了去年 Facebook 发布的 DETR,当时应该也算是惊艳众人.其有两点: 无需 nms 进行端到端的目标检测 将 NLP 中的 Transf ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- [Arxiv1706] Few-Example Object Detection with Model Communication 论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #042eee } p. ...
- Minimum Barrier Salient Object Detection at 80 FPS 论文阅读笔记
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
随机推荐
- Yarn【架构、原理、多队列配置】
目录 一.什么是yarn 二.yarn的基本架构和角色 三.yarn的工作机制 四.任务提交流程 五.资源调度器 FIFO 容量调度器 公平调度器 六.容量调度器多队列提交案例实操 1.案例:配置de ...
- Hive(七)【内置函数】
目录 一.系统内置函数 1.查看系统自带内置函数 2.查看函数的具体用法 二.常用内置函数 1.数学函数 round 2.字符函数 split concat concat_ws lower,upper ...
- 数组实现堆栈——Java实现
1 package struct; 2 3 4 //接口 5 interface IArrayStack{ 6 //栈的容量 7 int length(); 8 //栈中元素个数(栈大小) 9 int ...
- 监控Linux服务器网站状态的SHELL脚本
1,监控httpd状态码的shell脚本代码. #!/bin/sh #site: www.jquerycn.cn # website[0]=www.jquerycn.cn/chuzu/' #网站1 m ...
- 1.Thmeleaf模板引擎
1.Thmeleaf的基本语法 大部分的Thmeleaf表达式都直接被设置到HTML节点中,作为HTML节点的一个属性存在,这样同一个模板文件既可以使用浏览器直接打开,也可以放到服务器中用来显示数据, ...
- PostgreSql数据库安全加固
1.确保通过"主机" TCP / IP套接字登录已正确配置 描述 大量的身份验证方法可用于使用 TCP / IP套接字,包括: ?信任 ? 拒绝 ?md5 ?scram-sha-2 ...
- Jenkins 报错合集
目录 一.启动项目显示,没有接受许可之前不能够自动安装 二.明明配置了jdk但还是说找不到 三.jenkins-RestAPI调用出现Error 403 No valid crumb was incl ...
- 时间同步——TSN协议802.1AS介绍
前言之前的主题TSN的发展历史和协议族现状介绍了TSN技术的缘起,最近一期的主题TSN协议导读从定时与同步.延时.可靠性.资源管理四个方面,帮助大家了解TSN协议族包含哪些子协议,以及这些子协议的作用 ...
- 转:Android preference首选项框架
详解Android首选项框架ListPreference 探索首选项框架 在 深入探讨Android的首选项框架之前,首先构想一个需要使用首选项的场景,然后分析如何实现这一场景.假设你正在编写一个应用 ...
- Python 中更安全的 eval
问题 想要将一段列表形式的字符串转为 list,但是担心这个动态的字符串可能是恶意的代码?使用 eval 将带来安全隐患.比如: # 期望是 eval('[1, 2, 3]') # 实际上是 eval ...