Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD!
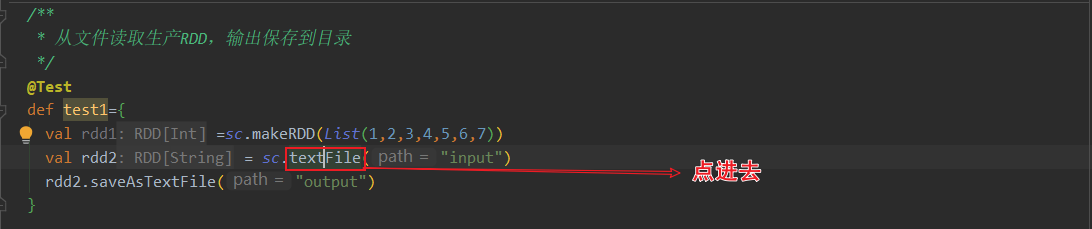
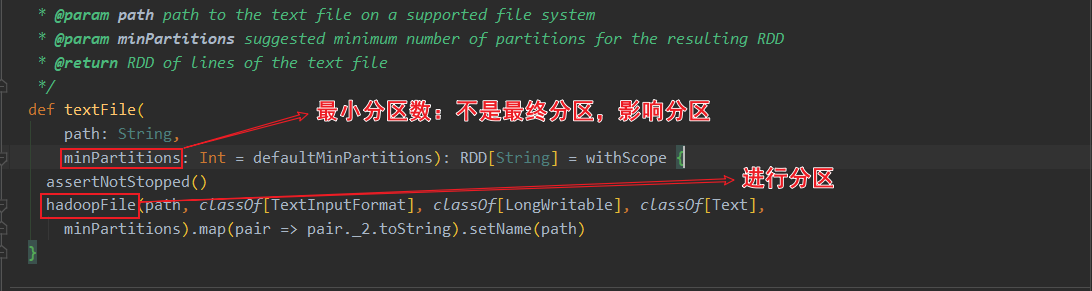
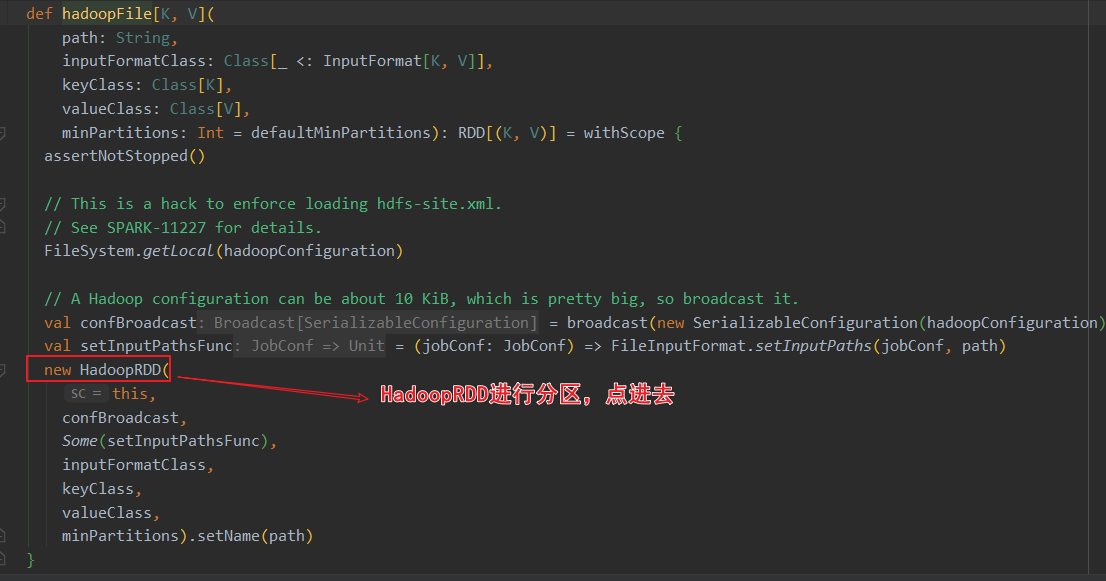
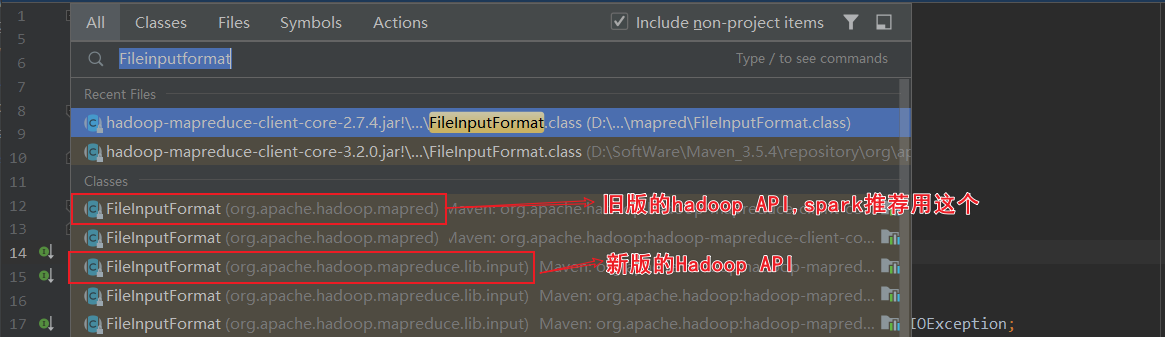
关于HadoopRDD的官方介绍,使用的是旧版的hadoop api

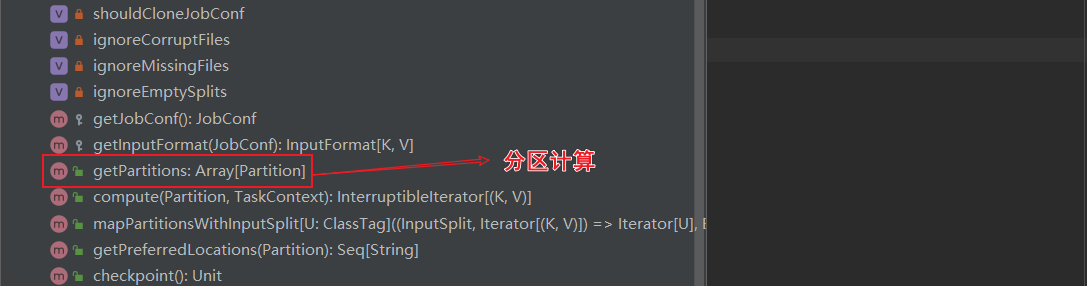
ctrl+F12搜索 HadoopRDD的getPartitions方法,这里进行了分区计算
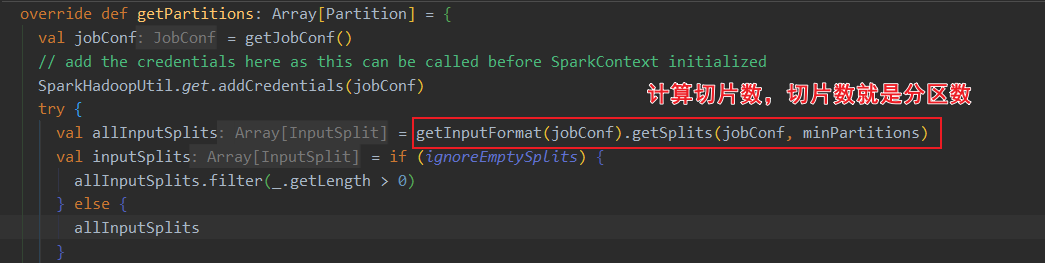
读取的是txt文件,用的是TextInputFormat的切片规则
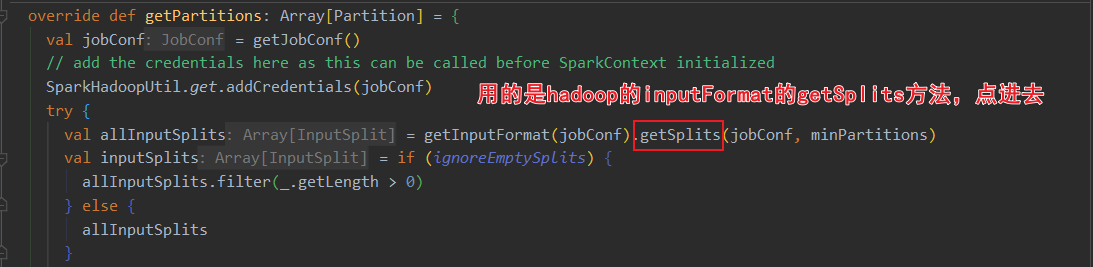
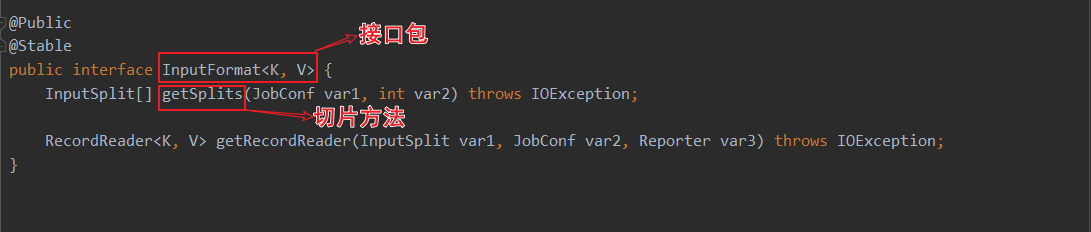
当前spark3.0的HadoopRDD依赖于hadoop的切片规则。其中HadoopRDD用的是旧版hadoop API,还有个NewHadoopRDD用的是新版hadoop API

进去TextInputFromat的查看split方法
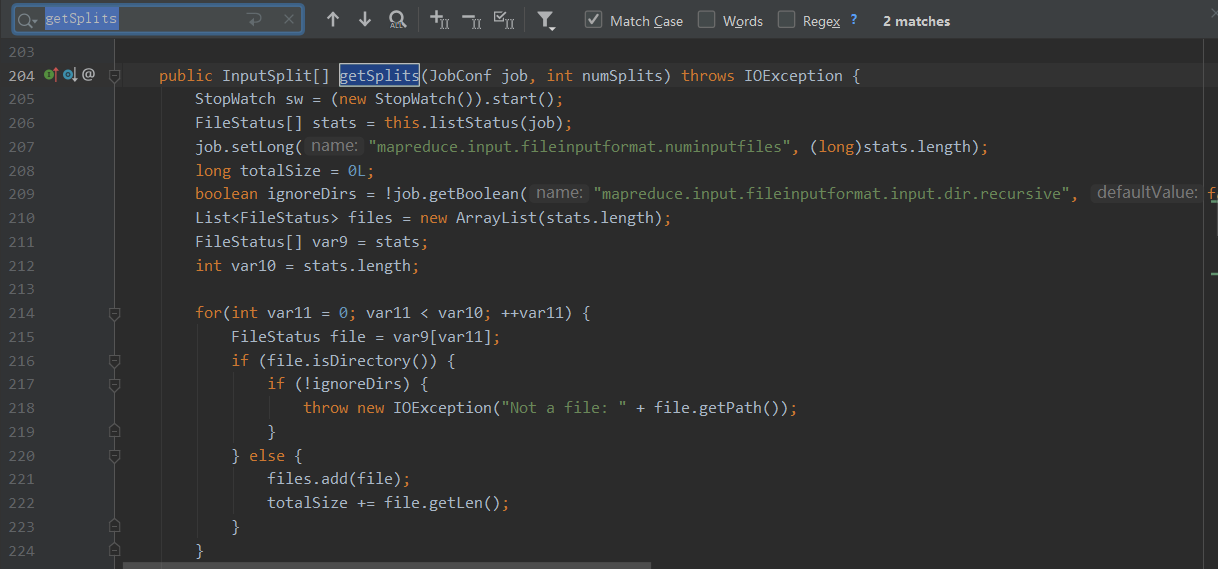
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
// 获取要操作的所有文件的属性信息
FileStatus[] files = listStatus(job);
// 所有文件的总大小
long totalSize = 0; // compute total size
// 目标切片大小 numSplits=defaultMinPartitions
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//默认为1
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
// 切片是以文件为单位切
for (FileStatus file: files) {
//获取文件大小
long length = file.getLen();
//文件不为空
if (length != 0) {
// 文件是否可切,一般普通文件都可切,如果是压缩格式,只有lzo,Bzip2可切
if (isSplitable(fs, path)) {
// 获取文件的块大小 默认128M
long blockSize = file.getBlockSize();
// 计算片大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
// 循环切片,以splitSize为基础进行切片 , 切的片大小,最后一片有可能小于片大小的1.1倍
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
// makeSplit()切片
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//剩余部分,不够一片,全部作为1片
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
// 文件为空,创建一个空的切片
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
计算片大小:片大小的计算以所有文件的总大小计算,切片时以文件为单位进行切片。
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
// minSize默认为1
return Math.max(minSize, Math.min(goalSize, blockSize));
}
总结:在大数据的计算领域,一般情况下,块大小就是片大小!
分区数过多,会导致切片大小 < 块大小。
分区数过少,task个数也会少,数据处理效率低,合理设置分区数。
Spark(二)【sc.textfile的分区策略源码分析】的更多相关文章
- RocketMQ中Broker的HA策略源码分析
Broker的HA策略分为两部分①同步元数据②同步消息数据 同步元数据 在Slave启动时,会启动一个定时任务用来从master同步元数据 if (role == BrokerRole.SLAVE) ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- Netty源码分析 (十二)----- 心跳服务之 IdleStateHandler 源码分析
什么是心跳机制? 心跳说的是在客户端和服务端在互相建立ESTABLISH状态的时候,如何通过发送一个最简单的包来保持连接的存活,还有监控另一边服务的可用性等. 心跳包的作用 保活Q:为什么说心跳机制能 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十二:EurekaServer集群模式源码分析
前言 前情回顾 上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题. 哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博 ...
- Java - "JUC线程池" 线程状态与拒绝策略源码分析
Java多线程系列--“JUC线程池”04之 线程池原理(三) 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基本概念"中,我们介绍过,线程有5种状态:新建 ...
- java容器二:List接口实现类源码分析
一.ArrayList 1.存储结构 动态数组elementData transient Object[] elementData; 除此之外还有一些数据 //默认初始容量 private stati ...
- okhttp缓存策略源码分析:put&get方法
对于OkHttp的缓存策略其实就是在下一次请求的时候能节省更加的时间,从而可以更快的展示出数据,那在Okhttp如何使用缓存呢?其实很简单,如下: 配置一个Cache既可,其中接收两个参数:一个是缓存 ...
- 小记--------spark的Master的Application注册机制源码分析及Master的注册机制原理分析
原理图解: Master类位置所在:spark-core_2.11-2.1.0.jar的org.apache.spark.deploy.master下的Master类 //截取了部分代码 //处理 ...
- Spring Ioc源码分析系列--Bean实例化过程(二)
Spring Ioc源码分析系列--Bean实例化过程(二) 前言 上篇文章Spring Ioc源码分析系列--Bean实例化过程(一)简单分析了getBean()方法,还记得分析了什么吗?不记得了才 ...
随机推荐
- hdu 1847 Good Luck in CET-4 Everybody! (简单博弈)
题意: n张牌,双方轮流抓取.每人每次抓取的牌数必须是2的幂次(1,2,4,8...). 最后抓完的人胜. 思路 : 考虑剩3张牌,后手胜. 考虑3的倍数.假设先抓者当轮抓2x 张,2x %3等于1或 ...
- 我为啥开始用CSDN博客
今晚开通CSDN博客,并且决定以后每天都使用这个不错的东西.与此同时,在博客园也开通了一个:http://www.cnblogs.com/fish7/ 我原本是把做过的题都用WPS整理的,然后每次打印 ...
- 非对称加密和linux上的 ssh-keygen 工具使用
rsa :创造非对称加密的三个人名.原理是两个1024到2048之间的素数,以此为乘积.等... a*b=c 一般a*b为私钥端,c为公钥端.因为 c非常难算出a和b. ssh-keygen -t ...
- java解析Excel日期格式转换问题
Excel上传导入,Excel里面单元格是日期的会解析出来数字,比如2020-07-11会解析为44023解决方法一: Excel单元格格式设置为文本格式.解决方法二: 使用代码处理,把解析出来的44 ...
- SpringCloud微服务实战——搭建企业级开发框架(十六):集成Sentinel高可用流量管理框架【自定义返回消息】
Sentinel限流之后,默认的响应消息为Blocked by Sentinel (flow limiting),对于系统整体功能提示来说并不统一,参考我们前面设置的统一响应及异常处理方式,返回相同的 ...
- Python基础(sorted)
arr1 = [1,2,3,-30,4,5,-6] arr2 = sorted(arr1)#sorted()函数就可以对list进行排序 arr3 = sorted(arr1,key=abs)#可以接 ...
- WinForm训练一_改变窗体大小
1 //引用系统命名空间 2 using System; 3 //项目命名空间 4 using System.Collections.Generic; 5 using System.Component ...
- <C#任务导引教程>练习五
//27,创建一个控制台应用程序,声明两个DateTime类型的变量dt,获取系统的当前日期时间,然后使用Format格式化进行规范using System;class Program{ sta ...
- 一文带你吃透CLR垃圾回收机制
前言 今天我们来共同学习一下CLR的垃圾回收机制,这对我们写出健壮性的代码很有帮助,也许有人会认为多此一举,认为垃圾回收交给CLR就行,我不用关心这个,诚然,大多数情况下是这样的,但是,我们今天讨论的 ...
- Kotlin小测试
fun main(args: Array<String>) { var a=1 a=2 println(a)//2 println(a::class)//int (Kotlin refle ...