Saliency maps
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
问题
这篇文章和ZFnet相似,旨在研究网络可视化的问题,根据分裂网络最后的向量来反推出最原始的图像,如果假设输入(input)是\(I\), 而输入图像对应的标签是\(c\), 而分类器的得分是\(S_c(I)\)(也就是第\(c\)个分量),那么我们希望找到一个\(I\)使得\(S_c(I)\)足够大,说明这个输入很有可能是这个类的:
\]
不过,论文实际上是研究下面的问题:
\]
其实就是加了一个正则化项,我想这应该是处于实际角度出发的,因为在处理图像的时候往往有一个Normlize的过程,所以如果\(I\)太过“巨大”那肯定是不合适的——起码它都不能称为一个图像.
细节
变量
需要注意的是,上面的问题是关于\(I\),也就是图像来说的,如果有\(k\)个类,那么理论上应该有\(k\)张对应的图像(同一个\(\lambda\)).
然后论文的结果是这样的:

我的结果是这样的(CIFAR10):
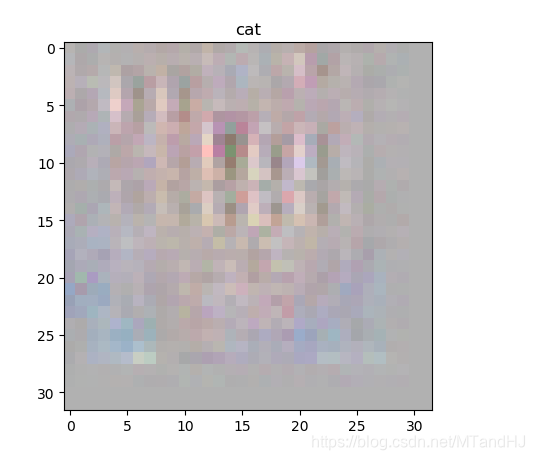
相差甚远, 是\(\lambda =0.1\)不合适?
\(S_c(I)\)
需要一提的是,这个\(S_c(I)\)不是sigmoid后的值,而是之前的分数,作者是这么解释的,因为sigmoid:
\]
我们的目的是提高\(S_c\),而如果是\(P_c\), 那么我们可以通过降低别的\(S_c\)来间接提高\(P_c\),而非提高\(S_c\), 有点道理吧,试了一下,在原来的参数条件下几乎不学习了...
扩展
作者提到这个方案可以用于定位, 首先要说明的是,通过这种方法,我们可以“定位”(虽然可能是臆想)敏感地带.
输入一张图片,计算
\]
结果是一个“矩阵”(张量?), 其中的元素的绝对值大小可以衡量对类别判断的重要,即越大越是敏感地带.

那个简单例子,感觉没能和好的说服我. 如果网络就是一个线性判别器,那么照此思路,其敏感程度就是权重,直观上这样似乎如此,但是感觉就像是抛开了数据本身...但的确是有道理的. 还有一个问题是,对于一张图片,如果它被误判了, 那么是选择其本身的标签,还是网络所判断的那个\(c\)呢?
在我的实验中,二者似乎没有太大的差别.
回到定位的话题,计算出梯度的矩阵后,如果有\(C\)个通道,\(C\)个通道的每个元素的绝对值的最大作为那个位置的敏感程度,如此,如果图片是\((C, H, W)\), 那么最后会得到一个\((1, H, W)\)的矩阵,其中的元素则反应了敏感程度.
但是,其中的敏感程度指示反应了物体所在的大概位置,作者说还要通过一种颜色的连续来更为细致地框定范围,那种技术我不知道,就简单地做个实验:
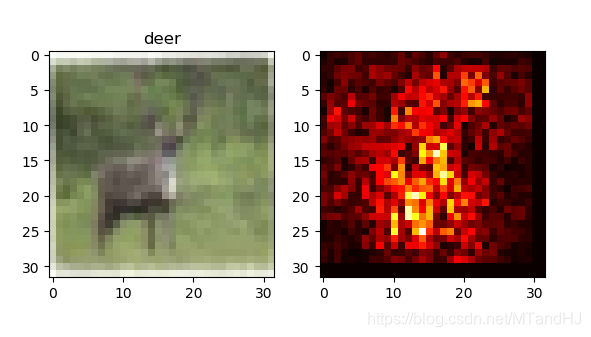
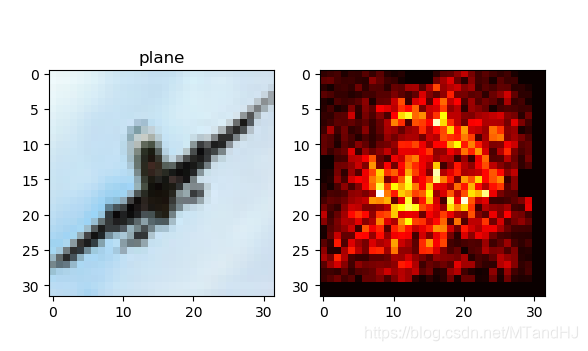
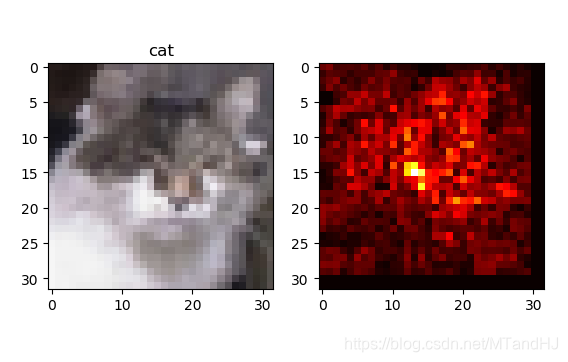
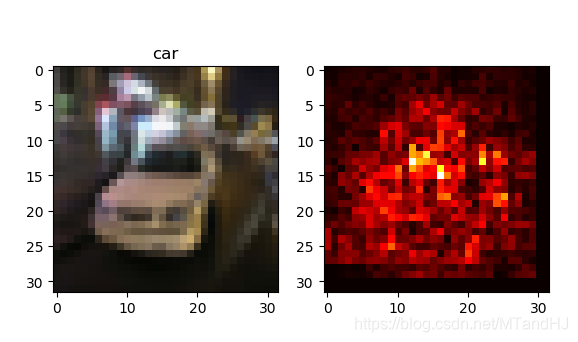
细看,我觉得还是有那么点感觉的.
代码
找\(I\)的时候,不知道怎么利用已有的梯度方法,就自己写了一个. 网络的测试成功率为60%,因为是一个比较简单的网络,大的网络实在难以下手.
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self, num):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 16, 4, 2), #3x32x32 --> 8x15x15
nn.ReLU(),
nn.MaxPool2d(2, 2), # 15 --> 7
nn.Conv2d(16, 64, 3, 1, 1), #16x7x7 --> 64x7x7
nn.ReLU(),
nn.MaxPool2d(2, 1) #7-->6
)
self.dense = nn.Sequential(
nn.Linear(64 * 6 * 6, 256),
nn.ReLU(),
nn.Linear(256, num)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
out = self.dense(x)
return out
class SGD:
def __init__(self, lr=1e-3, momentum=0.9):
self.v = 0
self.lr = lr
self.momentum = momentum
def step(self, x, grad):
self.v = self.momentum * self.v + grad
return x + self.lr * self.v
class Train:
def __init__(self, trainset, num=10, lr=1e-4, momentum=0.9,loss_function=nn.CrossEntropyLoss()):
self.net = Net(num)
self.trainset = trainset
self.criterion = loss_function
self.opti = torch.optim.SGD(self.net.parameters(), lr=lr, momentum=momentum)
def trainnet(self, iterations, path):
running_loss = 0.0
for epoch in range(iterations):
for i, data in enumerate(self.trainset):
imgs, labels = data
output = self.net(imgs)
loss = self.criterion(output, labels)
self.opti.zero_grad()
loss.backward()
self.opti.step()
running_loss += loss
if i % 10 == 9:
print("[epoch: {} loss: {:.7f}]".format(
epoch,
running_loss / 10
))
running_loss = 0.0
torch.save(self.net.state_dict(), path)
def loading(self, path):
self.net.load_state_dict(torch.load(path))
self.net.eval()
def visual(self, iterations=100, digit=0, gamma=0.1, lr=1e-3, momentum=0.9):
def criterion(out, x, digit, gamma=0.1):
return out[0][digit] - gamma * torch.norm(x, 2) ** 2
opti = SGD(lr, momentum)
x = torch.zeros((1, 3, 32, 32), requires_grad=True, dtype=torch.float)
for i in range(iterations):
output = self.net(x)
loss = criterion(output, x, digit, gamma)
print(loss.item())
loss.backward()
x = torch.tensor(opti.step(x, x.grad), requires_grad=True)
img = x[0].detach()
img = img / 2 + 0.5
img = img / torch.max(img.abs())
img = np.transpose(img, (1, 2, 0))
print(img[0])
plt.imshow(img)
plt.title(classes[digit])
plt.show()
return x
def local(self, img, label):
cimg = img.view(1, 3, 32, 32).detach()
cimg.requires_grad = True
output = self.net(cimg)
print(output)
print(label)
s = output[0][label]
s.backward()
with torch.no_grad():
grad = cimg.grad.data[0]
graph = torch.max(torch.abs(grad), 0)[0]
saliency = graph.detach().numpy()
print(np.max(saliency))
img = img.detach().numpy()
img = img / 2 + 0.5
img = np.transpose(img, (1, 2, 0))
fig, ax = plt.subplots(1, 2)
ax[0].set_title(classes[label])
ax[0].imshow(img)
ax[1].imshow(saliency, cmap=plt.cm.hot)
plt.show()
def testing(self, testloader):
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = self.net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
root = "C:/Users/pkavs/1jupiterdata/data"
#准备训练集
trainset = torchvision.datasets.CIFAR10(root=root, train=True,
download=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
train_loader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root=root, train=False,
download=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
path = root + "/visual1.pt"
test = Train(train_loader, lr=1e-4)
test.loading(path)
#test.testing(testloader) 60%
data = next(iter(train_loader))
imgs, labels = data
img = imgs[0]
label = labels[0]
test.local(img, label)
#test.visual(1000, digit=3)
Saliency maps的更多相关文章
- Learning to Promote Saliency Detectors
Learning to Promote Saliency Detectors 原本放在了思否上, 但是公式支持不好, csdn广告太多, 在博客园/掘金上发一下 https://github.com/ ...
- SalGAN: Visual saliency prediction with generative adversarial networks
SalGAN: Visual saliency prediction with generative adversarial networks 2017-03-17 摘要:本文引入了对抗网络的对抗训练 ...
- saliency map [转]
基于Keras实现的代码文档 (图+说明) "Deep Inside Convolutional Networks: Visualising Image Classification Mod ...
- 四种比较简单的图像显著性区域特征提取方法原理及实现-----> AC/HC/LC/FT。
laviewpbt 2014.8.4 编辑 Email:laviewpbt@sina.com QQ:33184777 最近闲来蛋痛,看了一些显著性检测的文章,只是简单的看看,并没有深入的研究,以 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Detecting diabetic retinopathy in eye images
Detecting diabetic retinopathy in eye images The past almost four months I have been competing in a ...
- cs231n --- 3 : Convolutional Neural Networks (CNNs / ConvNets)
CNN介绍 与之前的神经网络不同之处在于,CNN明确指定了输入就是图像,这允许我们将某些特征编码到CNN的结构中去,不仅易于实现,还能极大减少网络的参数. 一. 结构概述 与一般的神经网络不同,卷积神 ...
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
论文题目是STC,即Simple to Complex的一个框架,使用弱标签(image label)来解决密集估计(语义分割)问题. 2014年末以来,半监督的语义分割层出不穷,究其原因还是因为pi ...
- 四种简单的图像显著性区域特征提取方法-----AC/HC/LC/FT。
四种简单的图像显著性区域特征提取方法-----> AC/HC/LC/FT. 分类: 图像处理 2014-08-03 12:40 4088人阅读 评论(4) 收藏 举报 salient regio ...
随机推荐
- Hive(十一)【压缩、存储】
目录 一.Hadoop的压缩配置 1.MR支持的压缩编码 2.压缩参数配置 3.开启Mapper输出阶段压缩 4.开启Reduceer输出阶段 二.文件存储 1.列式存储和行式存储 2.TextFil ...
- 商业爬虫学习笔记day6
一. 正则解析数据 解析百度新闻中每个新闻的title,url,检查每个新闻的源码可知道,其title和url都位于<a></a>标签中,因为里面参数的具体形式不一样,同一个正 ...
- JavaScript小数、百分数的转换
百分数转化为小数 function toPoint(percent){ var str=percent.replace("%",""); str= str/10 ...
- 3.3 rust HashMap
The type HashMap<K, V> stores a mapping of keys of type K to values of type V. It does this vi ...
- 【编程思想】【设计模式】【结构模式Structural】装饰模式decorator
Python版 https://github.com/faif/python-patterns/blob/master/structural/decorator.py #!/usr/bin/env p ...
- 基于阿里云ecs(centos 7) 安装jenkins
1. 安装好 jdk 2. 官网(https://pkg.jenkins.io/redhat-stable/)下载rpm包(稳定版): wget https://pkg.jenkins.io/redh ...
- 『学了就忘』Linux服务管理 — 75、Linux系统中的服务
目录 1.服务的介绍 2.Windows系统中的服务 3.Linux系统中服务的分类 4.独立的服务和基于xinetd服务的区别 5.如何查看一个服务是独立的服务还是基于xinetd的服务 (1)查看 ...
- Mysql实例 表设计
目录 一.介绍 二.设计表格 三.查询 查都有哪些公司 查A公司都放了哪些广告 查A公司10月份该交多少广告费 四.分析 表结构设置 sql语句 其它功能 一.介绍 有一个公司叫月亮集团,他们旗下有很 ...
- 安装Google BBR加速
目录 一.简介 二.安装 三.设置BBR 一.简介 Google BBR 是一款免费开源的TCP拥塞控制传输控制协议, 可以使Linux服务器显著提高吞吐量和减少TCP连接的延迟. 二.安装 1.yu ...
- Spring MVC环境搭建和配置
1. 创建Dynamic web project 2. 修改WEB-INF/web.xml,内容如下: <?xml version="1.0" encoding=" ...