Redis——set,hash与列表
一.List列表
基于Linked List实现 元素是字符串类型
列表头尾增删快,中间增删慢,增删元素是常态
元素可以重复出现
最多包含2^32-1元素
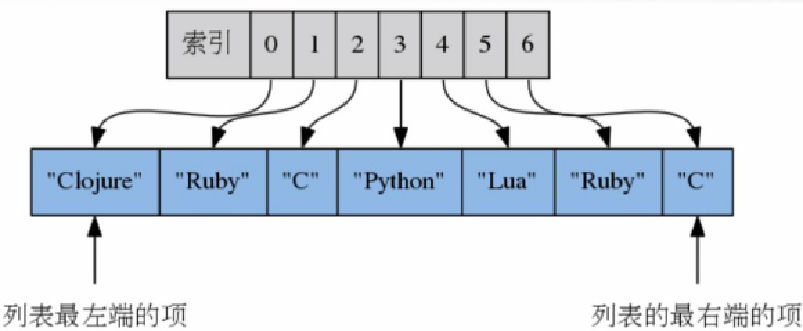
列表的索引
从左至右,从0开始
从右至左,从-1开始

1.左右或者头尾压入元素
LPUSH key value [value ...]
LPUSHX key value
RPUSH key value [value ...]
RPUSHX key value

2.左右或者头尾弹出元素
LPOP key RPOP key

3.从一个列表尾部弹出元素压入到另一个列表的头部
RPOPLPUSH source destination
4.返回列表中指定范围元素
LRANGE key start stop LRANGE key 0 -1表示返回所有元素
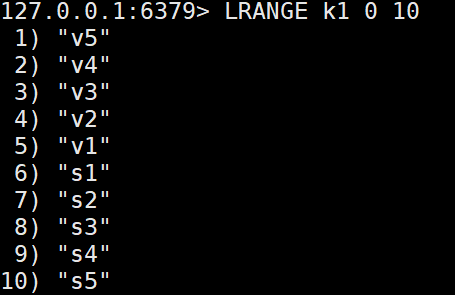
5.获取指定位置的元素
LINDEX key index
6.设置指定位置元素的值
LSET key index value
7.列表长度,元素个数
LLEN key
8.从列表头部开始删除值等于value的元素count次
LREM key count value
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count
count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值
count = 0 : 移除表中所有与 value 相等的值

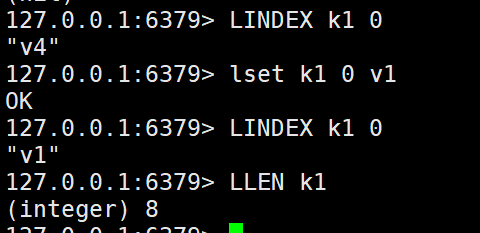
9.去处指定范围外元素
LTRIM key start stop
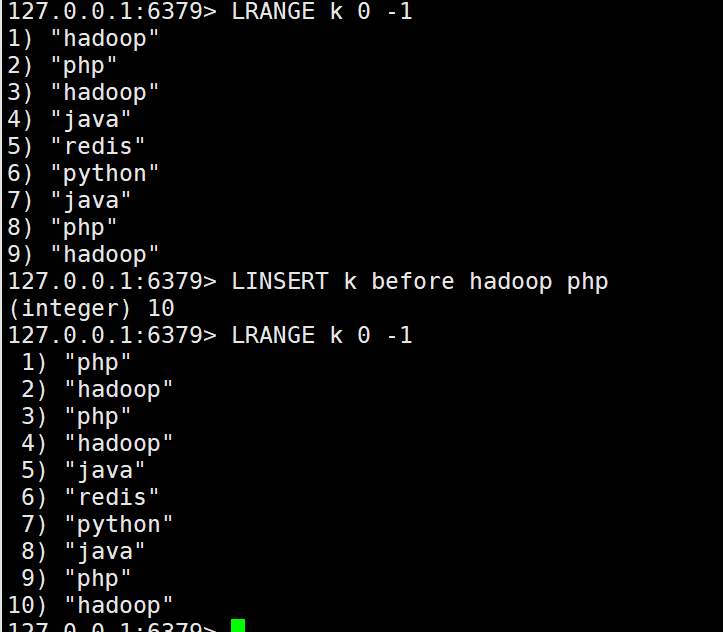
10.在列表中某个存在的值(pivot)前或后插入元素
LINSERT key BEFORE|AFTER pivot value
key和pivot不存在,不进行任何操作
11.阻塞
如果弹出的列表不存在或者为空,就会阻塞
超时时间设置为0,就是永久阻塞,直到有数据可以弹出
如果多个客户端阻塞在同一个列表上,使用First In First Service原则,先到先服务
左右或者头尾阻塞弹出元素
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout
二. Hsh散列
1.特点
由field和关联的value组成的map键值对
field和value是字符串类型一个hash中
最多包含2^32-1键值对

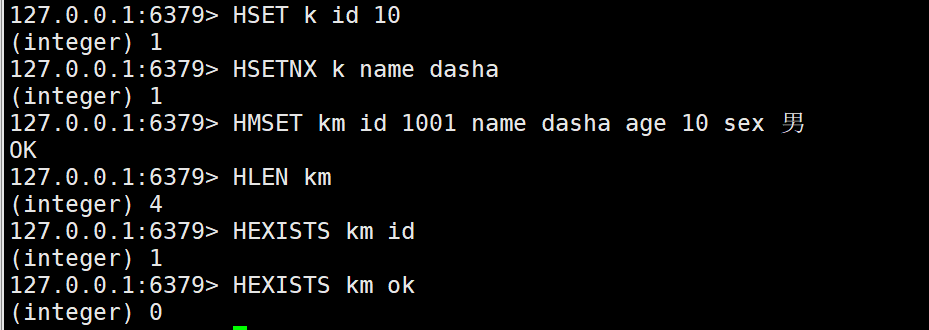
2.设置单个字段
HSET key field value
HSETNX key field value
key的filed不存在的情况下执行,key不存在直接创建
3.设置多个字段
HMSET key field value [field value ...]
4.返回字段个数
HLEN key
5.判断字段是否存在
HEXISTS key field
key或者field不存在,返回0
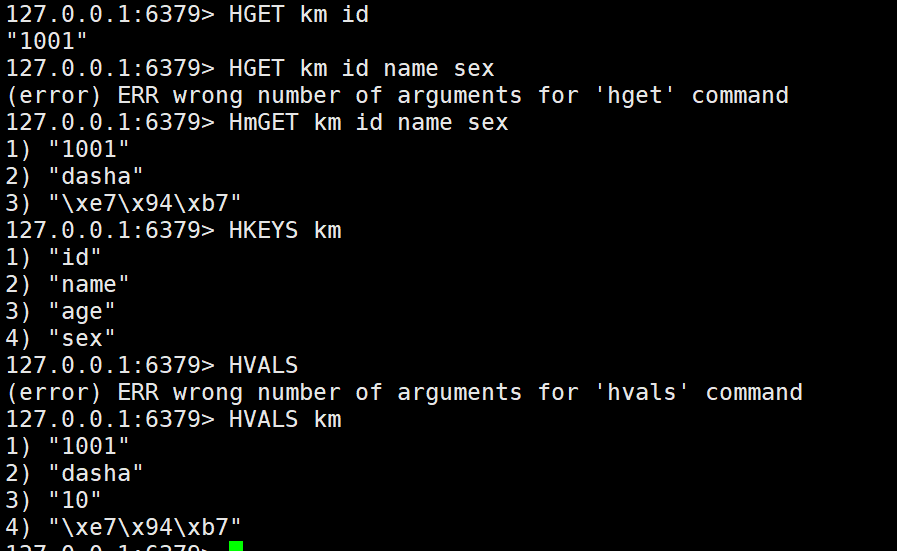
6.返回字段值
HGET key field
7.返回多个字段值
HMGET key field [field ...]
8.返回所有的键值对
HGETALL key
9.返回所有字段名
HKEYS key
10.返回所有值
HVALS key
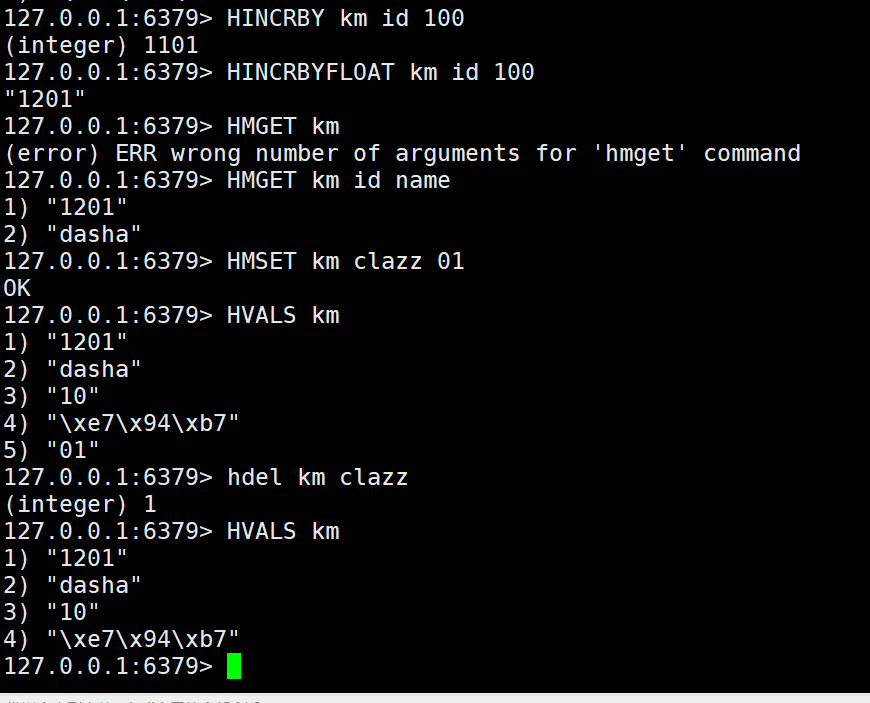
11.在字段对应的值上进行整数的增量计算
HINCRBY key field increment
12.在字段对应的值上进行浮点数的增量计算
HINCRBYFLOAT key field increment
13.删除指定的字段
HDEL key field [field ...]
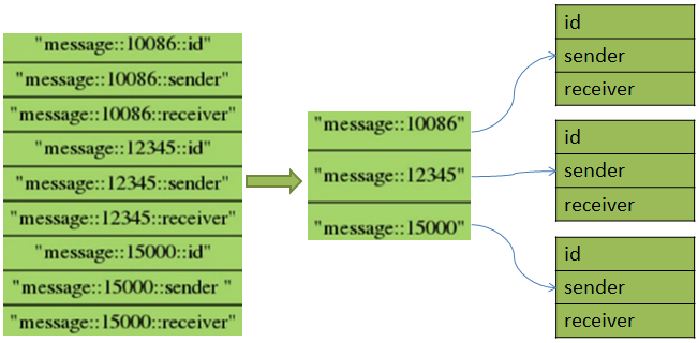
14. hash的用途
1)节约内存空间
2)每创建一个键,它都会为这个键储存一些附加的管理信息(比如这个键的类型,这个键最后一次被访问的时间等等)
3)所以数据库里面的键越多,redis数据库服务器在储存附加管理信息方面耗费的内存就越多,花在管理数据库键上的CPU也会越多在字段对应的值上进行浮点数的增量计算
15.不适合hash的情况
1)使用二进制位操作命令:因为Redis目前支持对字符串键进行SETBIT、GETBIT、BITOP等操作,如果你想使用这些操作,那么只能使用字符串键,虽然散列也能保存二进制数据
2)使用过期键功能:Redis的键过期功能目前只能对键进行过期操作,而不能对散列的字段进行过期操作,因此如果你要对键值对数据使用过期功能的话,那么只能把键值对储存在字符串里面
三.set集合
1.特点
无序的、去重的
元素是字符串类型
最多包含2^32-1元素
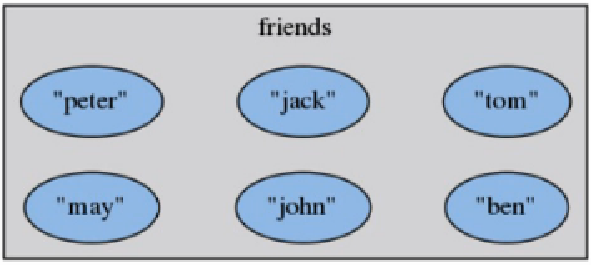
2.增加一个或多个元素
SADD key member [member ...]
如果元素已经存在,则自动忽略
3. 移除一个或者多个元素
SREM key member [member ...]
元素不存在,自动忽略
4.返回集合包含的所有元素
SMEMBERS key
如果集合元素过多,例如百万个,需要遍历,可能会造成服务器阻塞,生产环境应避免使用
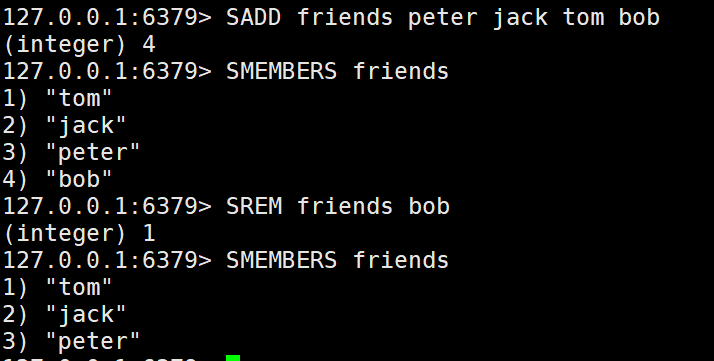
5.集合的无序性 ‘
SADD friends "peter" "jack" "tom" "john" "may" "ben"
SADD anotherfriends "peter" "jack" "tom" "john" "may" "ben"
SMEMBERS friends
SMEMBERS anotherfriends
注意, SMEMBERS 有可能返回不同的结果,所以,如果需要存储有序且不重复的数据使用有序集合,存储有序可重复的使用列表
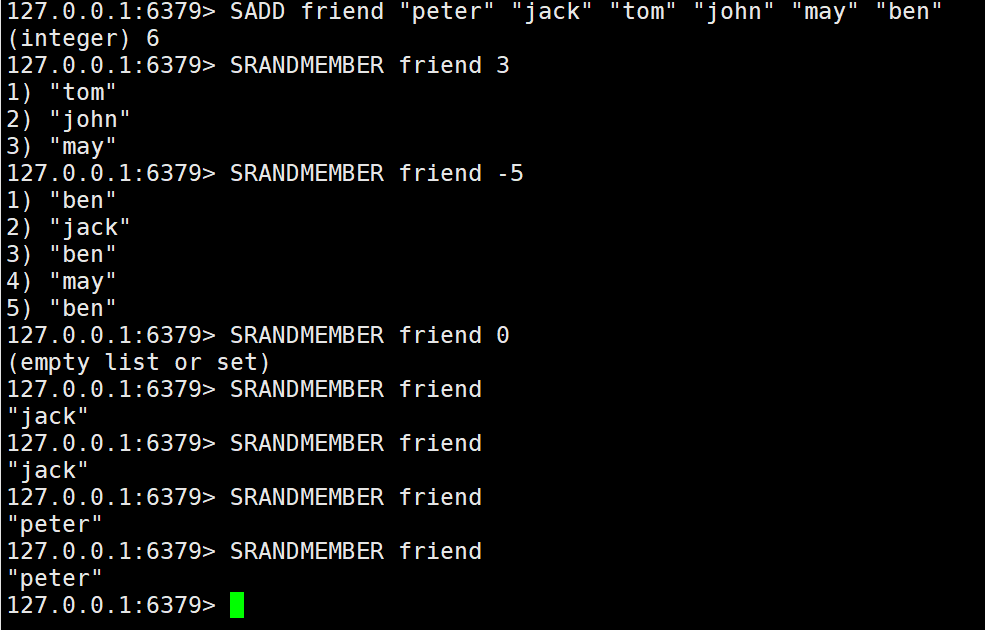
6. 随机返回集合中指定个数的
SRANDMEMBER key [count]
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。
如果 count 大于等于集合基数,那么返回整个集合
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值
如果 count 为 0,返回空 如果 count 不指定,随机返回一个元素
7. 返回集合中元素的个数
SCARD key 键的结果会保存信息,集合长度就记录在里面,所以不需要遍历
8. 随机从集合中移除并返回这个被移除的元素
SPOP key

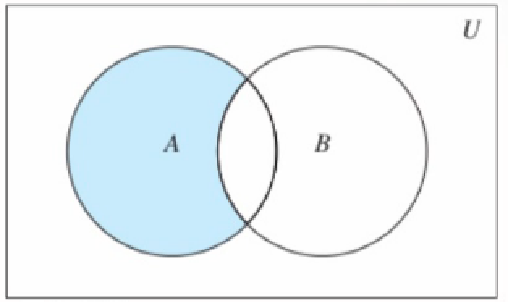
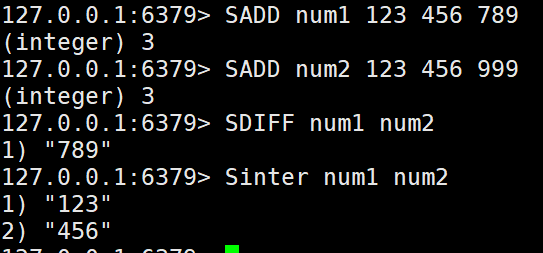
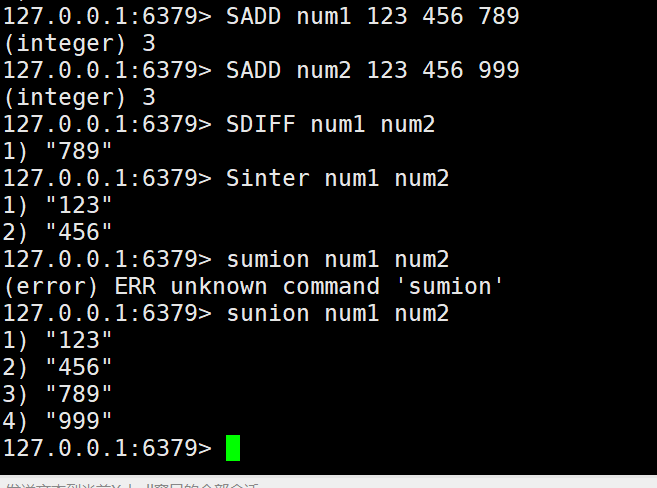
9. 差集
SDIFF key [key ...],从第一个key的集合中去除其他集合和自己的交集部分
SDIFFSTORE destination key [key ...],将差集结果存储在目标key中
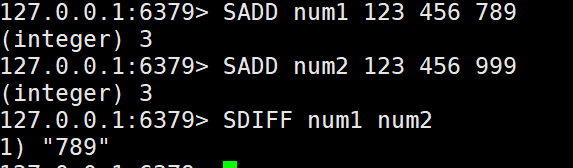
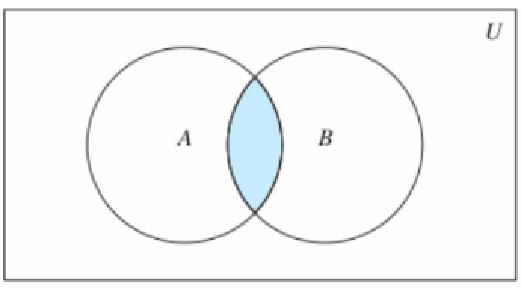
10.交集
SINTER key [key ...],取所有集合交集部分
SINTERSTORE destination key [key ...],将交集结果存储在目标key中
11. 并集
SUNION key [key ...],取所有集合并集
SUNIONSTORE destination key [key ...],将并集结果存储在目标key中
四. SortedSet有序集合
1.特点
类似Set集合
有序的、去重的
元素是字符串类型
每一个元素都关联着一个浮点数分值(Score),并按照分值从小到大的顺序排列集合中的元素。
分值可以相同 最多包含2^32-1元素
2. 增加一个或多个元素
ZADD key score member [score member ...]
如果元素已经存在,则使用新的score
举例
ZADD fruits 3.2 香蕉
ZADD fruits 2.0 西瓜
ZADD fruits 4.0 番石榴 7.0 梨 6.8 芒果

3. 移除一个或者多个元素
ZREM key member [member ...]
元素不存在,自动忽略
举例
ZREM fruits 番石榴 梨 芒果
ZREM fruits 西瓜
4.显示分值
ZSCORE key member
举例
ZSCORE fruits 芒果
ZSCORE fruits 西瓜

计算机并不能精确表达每一个浮点数,都是一种近似表达
5.增加或者减少分值
ZINCRBY key increment member increment为负数就是减少
举例 ZINCRBY fruits 1.5 西瓜 ZINCRBY fruits -0.8 香蕉

6. 返回元素的排名(索引)
ZRANK key member
举例 ZRANK fruits 西瓜
ZRANK fruits 番石榴
ZRANK fruits 芒果

7. 返回元素的逆序排名
ZREVRANK key member

8. 返回指定索引区间元素
ZRANGE key start stop [WITHSCORES]
如果score相同,则按照字典序lexicographical order 排列 默认按照score从小到大,如果需要score从大到小排列,使用ZREVRANGE

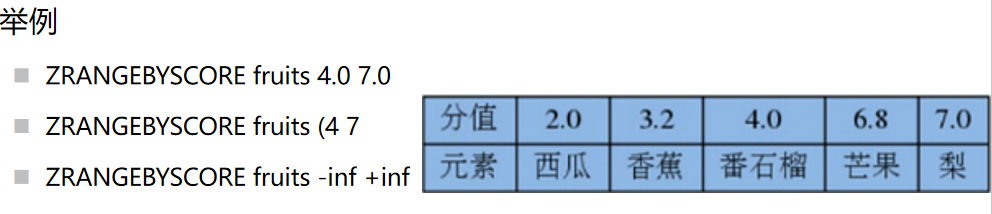
9. 返回指定分值区间元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score升序排列,score相同字典序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
10.返回指定分值区间元素
ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score降序排列,score相同字典降序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
 、
、
11.移除指定排名范围的元素

12.移除指定分值范围的元素

13.返回集合中元素个数

14.并集

Redis——set,hash与列表的更多相关文章
- redis的hash操作在集中式session中的应用
在集群部署时,为了高可用性的目的,往往把session进行共享,共享分为两种:session复制和集中式管理. redis在session集中式管理中可以起到比较大的作用. 制约session集中式共 ...
- redis对hash进行的相关操作
redis对hash类型操作的相关命令以及如何在python使用这些命令 redis对hash类型操作的命令: 命令 语法 概述 返回值 Redis Hdel 命令 hdel key field [f ...
- Redis之Hash数据结构
0.前言 redis是KV型的内存数据库, 数据库存储的核心就是Hash表, 我们执行select命令选择一个存储的db之后, 所有的操作都是以hash表为基础的, 下面会分析下redis的hash数 ...
- redis数据类型--hash
/** Redis应用之Hash数据类型* 问题1:操作命令* 问题2:存储实现原理和数据结构* 问题3:应用场景* */ 先了解下什么是hash,什么是hash碰撞:hash:是包含键值对的kv的数 ...
- Redis数据类型之散列表
Redis五大数据类型以及操作 目录: 一.redis的两种链接方式 二.redis的字符串操作(string) 三.redis的列表操作(list) 四.redis的散列表操作(类似于字典里面嵌套字 ...
- Redis数据结构之压缩列表-ziplist
为了节约内存,在zset和hash容器对象元素个数较少时,Redis会采用压缩列表(ziplist)进行存储. 压缩列表是一块连续的内存空间,元素之间紧挨着存储,不存在冗余 一个压缩列表可以包含任意多 ...
- 面试官:说说Redis的Hash底层 我:......(来自阅文的面试题)
redis源码分析系列文章 [Redis源码系列]在Liunx安装和常见API 为什么要从Redis源码分析 String底层实现——动态字符串SDS Redis的双向链表一文全知道 前言 hello ...
- Redis常用命令入门——列表类型(一级二级缓存技术)
获取列表片段 redis > LRANGE KEY_NAME START END lrange命令比较常用,返回从start到stop的所有元素的列表,start和stop都是从0开始. (1) ...
- Redis操作Hash工具类封装,Redis工具类封装
Redis操作Hash工具类封装,Redis工具类封装 >>>>>>>>>>>>>>>>>> ...
随机推荐
- Bugku-login1(SKCTF)(SQL约束攻击)
原因 sql语句中insert和select对长度和空格的处理方式差异造成漏洞. select对参数后面的空格的处理方式是删除,insert只是取规定的最大长度的字符串. 逻辑 1.用 select ...
- Android音视频开发(1):H264 基本原理
前言 H264 视频压缩算法现在无疑是所有视频压缩技术中使用最广泛,最流行的.随着 x264/openh264 以及 ffmpeg 等开源库的推出,大多数使用者无需再对H264的细节做过多的研究,这大 ...
- 跟我一起写 Makefile(四)
书写规则 ---- 规则包含两个部分,一个是依赖关系,一个是生成目标的方法. 在Makefile中,规则的顺序是很重要的,因为,Makefile中只应该有一个最终目标,其它的目标都是被这个目标所连带出 ...
- 用于在公网环境下测试的Telnet/SSH服务器
google: public telnet server list for example: telnet nethack.alt.org ssh nethack@alt.org
- 题解 a
传送门 和入阵曲那题很像 这里 \(n\) 很小,可以直接 \(n^2\) 压成一维考虑 然后就是对每个 \(j\) 查询 \([j-r, j-l]\) 中数的个数 这里我是用树状数组求的,带个log ...
- java-通过ip获取地址
添加maven依赖 <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all&l ...
- C#多线程---委托实现异步
一.概述 通过调用ThreadPool的QueueUserWorkItem方法来来启动工作者线程非常方便,但委托WaitCallback指向的是带有一个参数的无返回值的方法. 如果我们实际操作中需要有 ...
- Scrapy启动spider出错
python 3.7 里,async变成了关键字,所以报错. 解决方法:1回退python3.6版本. 2找到报错的那个py文件,比如manhole.py,将函数参数async改个名字(比如改成asy ...
- 2018.7.31-2018.8.2记:关于maven
maven的使用,用得好,则省力省事,但是用不好则会造成一堆莫名其妙的错误,maven在使用的时候,jar包下载异常终止尤为需要注意,很容易就终止了,并且会出现一些下载出空jar包的情况,即:jar包 ...
- 未解决:为什么在struts2下新建ognl的包,会出错?
首先开始在src下新建了一个名叫ognl的包: 发现在其中放置了一个loginAction,即使是最简单的跳转都不能实现: 直接抛出了java.lang.Exception; 传递参数更出现了异常: ...