Azkaban(一)【集群安装】
一.下载解压
1.下载地址:https://github.com/azkaban/azkaban
2.上传tar包
1)将azkaban-db-3.84.4.tar.gz,azkaban-exec-server-3.84.4.tar.gz,azkaban-web-server-3.84.4.tar.gz上传到hadoop102的/opt/software路径
[hadoop@hadoop102 software]$ ll
总用量 35572
-rw-r--r--. 1 atguigu atguigu 6433 4月 18 17:24 azkaban-db-3.84.4.tar.gz
-rw-r--r--. 1 atguigu atguigu 16175002 4月 18 17:26 azkaban-exec-server-3.84.4.tar.gz
-rw-r--r--. 1 atguigu atguigu 20239974 4月 18 17:26 azkaban-web-server-3.84.4.tar.gz
2)新建/opt/module/azkaban目录,并将所有tar包解压到这个目录下
[hadoop@hadoop102 software]$ mkdir /opt/module/azkaban
3)解压azkaban-db-3.84.4.tar.gz、 azkaban-exec-server-3.84.4.tar.gz和azkaban-web-server-3.84.4.tar.gz到/opt/module/azkaban目录下
[hadoop@hadoop102 software]$ tar -zxvf azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
[hadoop@hadoop102 software]$ tar -zxvf azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/
[hadoop@hadoop102 software]$ tar -zxvf azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/
4)进入到/opt/module/azkaban目录,依次修改名称
[hadoop@hadoop102 azkaban]$ mv azkaban-exec-server-3.84.4/ azkaban-exec
[hadoop@hadoop102 azkaban]$ mv azkaban-web-server-3.84.4/ azkaban-web
二. 配置Mysql
1.正常安装MySQL
参考Hive(一)【基本概念、安装】中的Mysql安装
以下密码设置为000000
2.启动MySQL
[hadoop@hadoop102 azkaban]$ mysql -uroot -p000000
3.登陆MySQL,创建Azkaban数据库
mysql> create database azkaban;
4.创建azkaban用户并赋予权限
设置密码有效长度4位及以上
mysql> set global validate_password_length=4;
设置密码策略最低级别
mysql> set global validate_password_policy=0;
创建Azkaban用户,任何主机都可以访问Azkaban,密码是000000
mysql> CREATE USER 'azkaban'@'%' IDENTIFIED BY '000000';
赋予Azkaban用户增删改查权限
mysql> GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
赋予Azakban用户远程访问权限,密码是000000
mysql> grant all privileges on azkaban.* to 'azkaban'@'%' identified by '000000' with grant option;
5.创建Azkaban表,完成后退出MySQL
mysql> use azkaban;
mysql> source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql
mysql> quit;
6.更改MySQL包大小;防止Azkaban连接MySQL阻塞
[hadoop@hadoop102 software]$ sudo vim /etc/my.cnf
在[mysqld]下面加一行max_allowed_packet=1024M
[mysqld]
max_allowed_packet=1024M
8)重启MySQL
[atguigu@hadoop102 software]$ sudo systemctl restart mysqld
三. 配置Azkaban Executor
Azkaban Executor Server处理工作流和作业的实际执行。
1.编辑azkaban.properties
[hadoop@hadoop102 azkaban]$ vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
修改如下属性
#修改和服务器时区一致
default.timezone.id=Asia/Shanghai
#Web服务器的地址
azkaban.webserver.url=http://hadoop102:8081
#端口
executor.port=12321
#注意改成自己的主机、用户、密码
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100
在最后添加
executor.metric.reports=true
executor.metric.milisecinterval.default=60000
2.同步azkaban-exec到所有节点
[hadoop@hadoop102 azkaban]$ xsync /opt/module/azkaban/azkaban-exec
3)必须进入到/opt/module/azkaban/azkaban-exec路径,分别在三台机器上,启动executor server
[hadoop@hadoop102 azkaban-exec]$ bin/start-exec.sh
[hadoop@hadoop103 azkaban-exec]$ bin/start-exec.sh
[hadoop@hadoop104 azkaban-exec]$ bin/start-exec.sh
注意:如果在/opt/module/azkaban/azkaban-exec目录下出现executor.port文件,说明启动成功,没有说明前面配置有问题。
4.激活executor
[hadoop@hadoop102 azkaban-exec]$ curl -G "hadoop102:$(<./executor.port)/executor?action=activate" && echo
[hadoop@hadoop103 azkaban-exec]$ curl -G "hadoop103:$(<./executor.port)/executor?action=activate" && echo
[hadoop@hadoop104 azkaban-exec]$ curl -G "hadoop104:$(<./executor.port)/executor?action=activate" && echo
如果三台机器都出现如下提示,则表示激活成功
{"status":"success"}
注意:每次启动都需要重新激活
四. 配置Azkaban WebServer
Azkaban Web Server处理项目管理,身份验证,计划和执行触发。
1.编辑azkaban.properties
[hadoop@hadoop102 azkaban]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
修改如下属性,
...
#改时区
default.timezone.id=Asia/Shanghai
...
#自己的主机,用户,密码
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100
...
#只需要StaticRemainingFlowSize,CpuStatus
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
说明
azkaban.executorselector.filters: 当有多个Executor同时启动的时候,需要从中选择一个Executor去执行任务,这里设置一组过滤器的种类,不满足要求的Executor就不会被分配任务
StaticRemainingFlowSize:正在排队的任务数;
CpuStatus:CPU占用情况
MinimumFreeMemory:内存占用情况。测试环境,必须将MinimumFreeMemory删除掉,否则它会认为集群资源不够,不执行。
2.修改azkaban-users.xml文件,添加atguigu用户
[hadoop@hadoop102 azkaban-web]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban-users.xml
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<!--测试用户-->
<user password="test" roles="metrics,admin" username="test"/>
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
3.必须进入到hadoop102的/opt/module/azkaban/azkaban-web路径,启动web server
[hadoop@hadoop102 azkaban-web]$ bin/start-web.sh
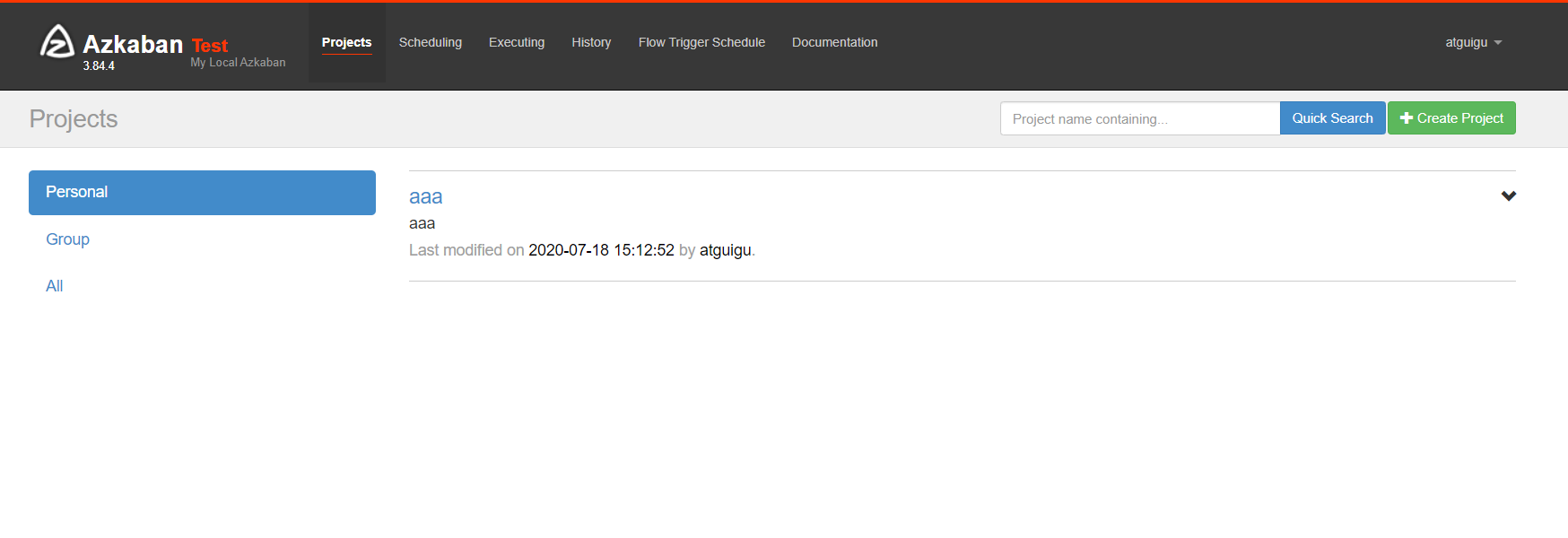
4.访问http://hadoop102:8081,并用test用户登陆
出现以下页面说明安装成功。
Azkaban(一)【集群安装】的更多相关文章
- 【Oracle 集群】Oracle 11G RAC教程之集群安装(七)
Oracle 11G RAC集群安装(七) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总. ...
- kafka集群安装部署
kafka集群安装 使用的版本 系统:centos6.5 centos6.7 jdk:1.7.0_79 zookeeper:3.4.9 kafka:2.10-0.10.1.0 一.环境准备[只列,不具 ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- Hadoop多节点集群安装配置
目录: 1.集群部署介绍 1.1 Hadoop简介 1.2 环境说明 1.3 环境配置 1.4 所需软件 2.SSH无密码验证配置 2.1 SSH基本原理和用法 2.2 配置Master无密码登录所有 ...
- codis集群安装
在网上找了很多codis的集群安装方法,看起来都是大同小异,本人结合了大多种方法完成了一套自己使用的codis的集群安装,可以供大家学习使用,如果有什么问题或者不懂的地方欢迎指正 1.集群规划: 三台 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- (原) 1.2 Zookeeper伪集群安装
本文为原创文章,转载请注明出处,谢谢 Zookeeper伪集群安装 zookeeper单机安装配置可以查看 1.1 zookeeper单机安装 1.复制三份zookeeper,分别为zookeeper ...
- 一步步教你Hadoop多节点集群安装配置
1.集群部署介绍 1.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesys ...
- kafka 集群安装与安装测试
一.集群安装 1. Kafka下载:wget https://archive.apache.org/dist/kafka/0.8.1/kafka_2.9.2-0.8.1.tgz 解压 tar zxvf ...
- k8s入门系列之集群安装篇
关于kubernetes组件的详解介绍,请阅读上一篇文章<k8s入门系列之介绍篇> Kubernetes集群安装部署 •Kubernetes集群组件: - etcd 一个高可用的K/V键值 ...
随机推荐
- Swarm+Docker+Portainer(集群,图形化)
参考文章 https://blog.csdn.net/u011781521/article/details/80469804 https://blog.csdn.net/u011781521/arti ...
- centos redhat 安装g++
正确安装命令 : yum install gcc-c++ libstdc++-devel 安装后可以在/bin/找到
- Fiddler抓包工具简介:(三)手机端代理配置
1.接入网络:需要在移动终端(手机或pad)上指定代理服务器为Fiddler所在主机的IP,端口默认为8888,要保证手机和安装有fiddler的电脑处在同一局域网内,手机能ping通电脑. [方法] ...
- Java——去掉小数点后面多余的0
当小数点后位数过多,多余的0没有实际意义,根据业务需求需要去掉多余的0.后端存储浮点型数据一般会用到Bigdecimal 类型,可以调用相关方法去掉小数后多余0,然后转为string. public ...
- HttpClient用法--这一篇全了解(内含例子)
HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性,它不仅使客户端发送Http请求变得容易,而且也方便开发人员测试接口(基于Http协议的),提高了开发的效率,也 ...
- 【JAVA】笔记(5)--- final;抽象方法;抽象类;接口;解析继承,关联,与实现;
final: 1.理解:凡是final修饰的东西都具有了不变的特性: 2.修饰对象: 1)final+类--->类无法被继承: 2)final+方法--->方法无法被覆盖: 3)final ...
- JS中innerHTML、outerHTML、innerText 、outerText、value的区别与联系?
1.innerHTML 属性 (参考自<JavaScript高级程序设计>294页) 在读模式下,innerHTML 属性返回与调用元素的所有子节点(包括元素.注释和文本节点)对应的 HT ...
- Effective C++ 总结笔记(六)
七.模板与泛型编程 41.了解隐式接口和编译器多态 1.类和模板都支持接口和多态. 2.类的接口是显式定义的--函数签名.多态是通过虚函数在运行期体现的. 3.模板的接口是隐式的(由模板函数的实现代码 ...
- Django 小实例S1 简易学生选课管理系统 8 CSS样式优化
Django 小实例S1 简易学生选课管理系统 第8节--CSS样式优化 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 前面的几节下来,用户模块基 ...
- CSDN code使用
常见错误:在linux下拷贝的时候有时候会出现cp:omitting directory的错误 ,例如 cp:omitting directory "bbs" 说明bbs目录下面还 ...