cadvisor+prometheus+alertmanager+grafana完成容器化监控告警(一)
一、概况
1、拓扑图

2、名词解释
Grafana
可视化监控容器运行情况 Prometheus:
开源系统监视和警报工具包 Alertmanager
一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息 Cadvisor
不仅可以搜集一台机器上所有运行的容器信息还提供基础查询界面和 http 接口,方便 Prometheus 进行数据抓取。
二、部署grafana
docker run -d -p 5000:3000 \
-v /home/grafana:/var/lib/grafana \
--name grafana grafana/grafana:latest
三、部署cadvisor
在监控的节点上部署
docker run -d \
-v /:/rootfs:ro \
-v /var/run:/var/run:ro \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro \
-p 8888:8080 \
--detach=true \
--name=cadvisor \
--restart=always \
google/cadvisor:latest
四、部署alertmanager
4.1部署
tar xf alertmanager-0.21.0.linux-amd64.tar.gz –C /home/
主目录:/home/alertmanager-0.21.0
4.2创建启动文件
[root@autodeploy alertmanager-0.21.0]# cat start.sh
#!/bin/bash
pid=`ps -ef|grep aler|grep -v grep|awk '{print $2}'`
kill -9 $pid
nohup ./alertmanager --config.file=alertmanager.yml --storage.path=data --log.level=debug &
4.3配置文件
[root@autodeploy alertmanager-0.21.0]# vim alertmanager.yml global:
resolve_timeout: 5m
templates:
- '/home/alertmanager-0.21.0/rules/*.tmpl'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 1m
repeat_interval: 1m
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'ww f53808cd2d0'
agent_id: '10 0003'
api_secret: 't6pdo4QRF4z_EyZWDXNlLRq-2Ahmtefu3Wt99uKyw'
to_user: '@all'
send_resolved: true
4.4报警信息模板
[root@autodeploy alertmanager-0.21.0]# cat rules/weixin.tmpl
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
========监控报警====
告警状态: {{ .Status }}
告警级别: {{ $alert.Labels.severity }}
告警类型: {{ $alert.Labels.alertname }}
告警应用: {{ $alert.Labels.name }}
告警主机: {{ $alert.Labels.instance }}
告警详情: {{ $alert.Annotations.description }}
告警时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========end=========
{{ end }}
{{ end }}
4.5启动告警服务
[root@autodeploy alertmanager-0.21.0]# sh start.sh
[root@autodeploy alertmanager-0.21.0]# tail -f nohup.out
4.6访问
http://ip:9093
五、部署prometheus
5.1部署
tar xf prometheus-2.25.2.linux-amd64.tar.gz –C /home/
主目录:/home/prometheus-2.25.2
5.2创建启动命令文件
[root@autodeploy prometheus-2.25.2]# cat start.sh
#!/bin/bash
pid=`ps -ef|grep prometheus|grep -v grep|awk '{print $2}'`
kill -9 $pid
nohup ./prometheus --config.file=prometheus.yml &
5.3修改配置文件
[root@autodeploy prometheus-2.25.2]# vim prometheus.yml
#告警关联
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['10.0.0.189:9093']
#报警规则目录
rule_files:
- "rules/*"
#获取各节点数据
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: 'node_exporter'
static_configs:
- targets:
- "10.0.0.194:8888"
- "10.0.0.195:8888"
- "10.0.0.196:8888"
5.4告警触发规则
1、警告容器输出带宽大于50M,警告容器输入带宽大于50M
[root@autodeploy rules]# cat container.network.yml
groups:
- name: container.rules.network
rules:
- alert: Container-network-output-alarm
expr: sum by (name,instance) (irate(container_network_receive_bytes_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[3m])) /1024/1024 >50
for: 1m
labels:
severity: critical
annotations:
description: "Warning of container output bandwidth greater than 50M"
- alert: Container-network-input-alarm
expr: sum by (name,instance) (irate(container_network_transmit_bytes_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[3m])) /1024/1024 >50
for: 1m
labels:
severity: critical
annotations:
description: "Warning of container input bandwidth greater than 50M" 2、容器内存超过1000M报警
[root@autodeploy rules]# cat container.memory.yml
groups:
- name: container.rules.memory
rules:
- alert: Container-memory-alarm
expr: sum(container_memory_rss{instance=~"10.0.0.*:8888",name=~".+"}) by (name,instance) > 1000000000
for: 1m
labels:
severity: critical
annotations:
description: "Container memory over 1000M alarm" 3、告警解释容器cpu利用率超过60%
[root@autodeploy rules]# cat container.CPUutilization.yml
groups:
- name: container.rules.CPUutilization
rules:
- alert: Container-CPUutilization-alarm
expr: sum(irate(container_cpu_usage_seconds_total{instance=~"10.0.0.*:8888",name=~".+",image!=""}[1m])) without (cpu)*100>60
for: 1m
labels:
severity: critical
annotations:
description: "Container CPUutilization over 60% alarm" 容器内cpu压测,测试监控
echo "scale=5000; 4*a(1)" | bc -l -q 4、缓存使用超过500M报警
[root@autodeploy rules]# cat container.cache.yml
groups:
- name: container.rules.cache
rules:
- alert: Container-cache-alarm
expr: sum(container_memory_cache{instance=~"10.0.0.*:8888",name=~".+"}) by (name,instance) >500000000
for: 1m
labels:
severity: critical
annotations:
description: "Container cache over 500M alarm"
5.5启动监控服务
[root@autodeploy prometheus-2.25.2]# sh start.sh
[root@autodeploy prometheus-2.25.2]# tail -f nohup.out
5.6访问
http://ip:9090
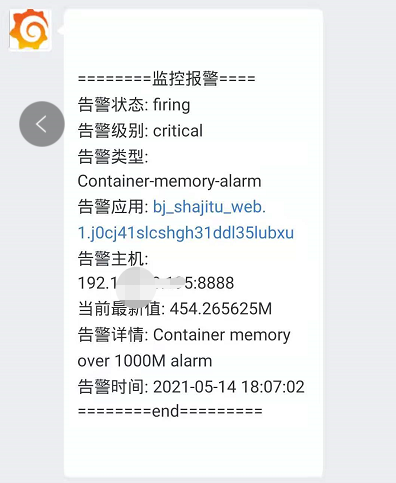
六、微信告警展示
友情grafana监控模板:11600
cadvisor+prometheus+alertmanager+grafana完成容器化监控告警(一)的更多相关文章
- jmx_prometheus_javaagent+prometheus+alertmanager+grafana完成容器化java监控告警(二)
一.拓扑图 二.收集数据 2.1前期准备 创建共享目录,即为了各节点都创建该目录,有两个文件,做数据共享 /home/target/prom-jvm-demo 1.下载文件 jmx_prometheu ...
- 【集群监控】Docker上部署Prometheus+Alertmanager+Grafana实现集群监控
Docker部署 下载 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.re ...
- Prometheus Alertmanager Grafana 监控警报
Prometheus Alertmanager Grafana 监控警报 #node-exporter, Linux系统信息采集组件 #prometheus , 抓取.储存监控数据,供查询指标 #al ...
- Longhorn,企业级云原生容器分布式存储 - 监控(Prometheus+AlertManager+Grafana)
内容来源于官方 Longhorn 1.1.2 英文技术手册. 系列 Longhorn 是什么? Longhorn 企业级云原生容器分布式存储解决方案设计架构和概念 Longhorn 企业级云原生容器分 ...
- [转]Prometheus 与 Grafana 实现服务器运行状态监控
http://flintx.me/2017/12/12/Prometheus%20+%20Grafana%20%E5%AE%9E%E7%8E%B0%E6%9C%8D%E5%8A%A1%E5%99%A8 ...
- [k8s]prometheus+alertmanager二进制安装实现简单邮件告警
本次任务是用alertmanaer发一个报警邮件 本次环境采用二进制普罗组件 本次准备监控一个节点的内存,当使用率大于2%时候(测试),发邮件报警. k8s集群使用普罗官方文档 环境准备 下载二进制h ...
- Prometheus+Alertmanager+Grafana监控组件容器部署
直接上部署配置文件 docker-compose.yml version: '3' networks: monitor: driver: bridge services: prometheus: im ...
- Kubernetes1.16下部署Prometheus+node-exporter+Grafana+AlertManager 监控系统
Prometheus 持久化安装 我们prometheus采用nfs挂载方式来存储数据,同时使用configMap管理配置文件.并且我们将所有的prometheus存储在kube-system #建议 ...
- 容器监控告警方案(cAdvisor + nodeExporter + alertmanager + prometheus +grafana)
一.prometheus基本架构 Prometheus 是一套开源的系统监控报警框架.它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 ...
随机推荐
- Windows系统搭建Redis集群三种模式(零坑、最新版)
目录 主从复制 修改配置文件 启动各节点 验证 哨兵模式 修改配置文件 启动实例 验证 集群模式 修改配置文件 启动实例 验证 主从复制 新建以下三个目录,用来部署一主二从 redis 的安装在另外一 ...
- 刷题-力扣-1137. 第 N 个泰波那契数
1137. 第 N 个泰波那契数 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/n-th-tribonacci-number 著作权 ...
- canvas——绘制解锁图案
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- GUI容器之Panel
Panel //panel可以看成是一个空间,但不能单独存在 public class MyPanel { public static void main(String[] args) { Frame ...
- python 文件批量改名重命名 rename
path = '/Volumes/Seagate/dev/imgs/' os.chdir(path) print('cwd: ', os.getcwd()) for f in os.listdir(' ...
- Tars | 第5篇 基于TarsGo Subset路由规则的Java JDK实现方式(上)
目录 前言 1. 修改.tars协议文件 1.1 Go语言修改部分 1.2 修改地方的逻辑 1.3 通过协议文件自动生成代码 2. [核心]增添Subset核心功能 2.1 Go语言修改部分 2.2 ...
- QT开发实战一:图片显示
测试平台 宿主机平台:Ubuntu 12.04.4 LTS 目标机:Easy-ARM IMX283 目标机内核:Linux 2.6.35.3 QT版本:Qt-4.7.3 Tslib版本:tslib-1 ...
- Python - typing 模块 —— Union
前言 typing 是在 python 3.5 才有的模块 前置学习 Python 类型提示:https://www.cnblogs.com/poloyy/p/15145380.html 常用类型提示 ...
- linux常用查询命令
1 **系统** 2 # uname -a # 查看内核/操作系统/CPU信息 3 # head -n 1 /etc/issue # 查看操作系统版本 4 # cat /proc/cpuinfo # ...
- Fastjson反序列化漏洞基础
Fastjson反序列化漏洞基础 FastJson是alibaba的一款开源JSON解析库,可用于将Java对象转换为其JSON表示形式,也可以用于将JSON字符串转换为等效的Java对象. 0x0 ...