python3 爬虫五大模块之一:爬虫调度器
Python的爬虫框架主要可以分为以下五个部分:
爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义;
URL管理器:负责URL的管理,包括带爬取和已爬取的URL、已经提供相应的接口函数(类似增删改查的函数)
网页下载器:负责通过URL将网页进行下载,主要是进行相应的伪装处理模拟浏览器访问、下载网页
网页解析器:负责网页信息的解析,这里是解析方式视具体需求来确定
信息采集器:负责将解析后的信息进行存储、显示等处理
代码示例是爬取CSDN博主下的所有文章为例,文章仅作为笔记使用,理论知识rarely
一、爬虫调度器简介
爬虫调度器作为框架的核心组成部分和爬虫的入口,负责将各个模块进行统一管理和调度,类似于C语言里的main函数。
爬虫调度器核心框架:
'''
自定义Python伪代码:
''' # 1. 传入待爬取的网站URL链接
# 2. 将URL添加到URL管理器的待爬取url列表中
# 3. 执行爬行策略:
while condition:
#4. 将待爬取的URL从URL管理器中取出,并传递给网页下载器
#5. 将网页下载器下载的网页信息传递给网页解析器
#6. 将网页解析器解析后的新的URL信息添加到URL管理器
#7. 将网页解析器解析后的其他信息传递给采集器
# 8. 爬取完毕
二、爬虫调度器示例:(爬取CSDN博主下的所有文章)
# author : s260389826
# date : 2019/3/22
# position: chengdu
from cnsd import url_manager
from cnsd import html_downloader
from cnsd import html_parser
from cnsd import html_outputer
class SpiderMain:
def __init__(self): # 创建其余四个模块
self.urlManager = url_manager.UrlManager()
self.htmlDownloader = html_downloader.HtmlDownloader()
self.htmlParse = html_parser.HtmlParser()
self.htmlOutputer = html_outputer.HtmlOutputer()
# 根据博主名构建博主文章页的完整URL
def getAllUrl(self, usr_blog, page):
return "http://blog.csdn.net/" + usr_blog + "/article/list/" + str(page) + '?'
# 爬虫主函数
def crawl(self, usr_blog, total_pages):
if usr_blog is None or total_pages == 0:
print("spider_Main: initial url is None or total_pages is 0")
return
page = 1
seq = 0
root_url = self.getAllUrl(usr_blog, page) # 获取完整的URL
self.urlManager.add_page_url(root_url) # 添加到URL管理器
while self.urlManager.has_page_url():
page_url = self.urlManager.get_page_url() # 取出URL
html = self.htmlDownloader.downloader(page_url) # 下载网页
article_urls = self.htmlParse.parser(page# 解析网页_url, html) # 解析网页
for article_url in artic# 遍历文章的URLle_urls: # 遍历文章的URL
# print(article_url)
seq = seq + 1
html = self.htmlDownloader.downloader(article_url) # 下载文章
self.htmlOutputer.collect(usr_blog, seq, html) # 解析、存储文章
if page < total_pages: # 是否继续爬取下一页
page = page + 1
next_page_url = self.getAllUrl(usr_blog, page)
self.urlManager.add_page_url(next_page_url)
# print("-=-=-=-=-=-=-=-=-=-文章数量为:%d=-=-=-=-=-=-=-=-=-=-=-" % len(article_urls))
print("===================csdn spider over====================")
'''
该爬虫用来爬取CSDN博客博主的所有文章:
UserBlog : 博主账号名称
page_number : 博主博客下的页码数
'''
if __name__ == '__main__':
# print('Please input your CSDN blog\'name:')
# name = input()
# print('Please input your CSDN blog total pages:')
# page_number = input()
# base_url = 'http://blog.csdn.net/%s' % name
UserBlog = "yunsongice" #" http://blog.csdn.net/s2603898260"
page_number = int(16)
spider = SpiderMain()
spider.crawl(UserBlog, page_number)
三、上述代码用到的知识点:
1. 引用该packet下的其他类文件:
from cnsd import url_manager
from cnsd import html_downloader
from cnsd import html_parser
from cnsd import html_outputercnsd:在工程中创建的一个Python pagcket文件, 然后将其命名为“cnsd” (这是个手误操作):
创建后的目录为:
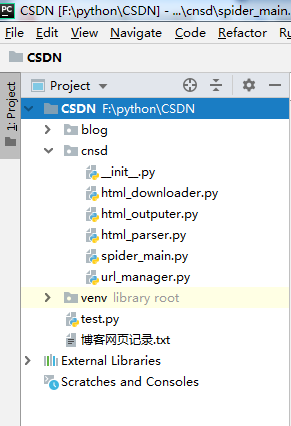
创建完packet目录后,依次创建了如上图所示的五个模块的python文件,引用的便是另外四个的文件名。
2. 通过构造器创建示例对象:
def __init__(self): # 创建其余四个模块
self.urlManager = url_manager.UrlManager()
self.htmlDownloader = html_downloader.HtmlDownloader()
self.htmlParse = html_parser.HtmlParser()
self.htmlOutputer = html_outputer.HtmlOutputer()3. 标记主函数入口:
if __name__ == '__main__':python3 爬虫五大模块之一:爬虫调度器的更多相关文章
- python3 爬虫五大模块之五:信息采集器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之三:网页下载器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之二:URL管理器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之四:网页解析器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python 爬虫 urllib模块 反爬虫机制UA
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https:// ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看: golang实现并发爬虫一(单任务版本爬虫功能) gollang实现并发爬虫二(简单调度器) 上文中的用简单的调度器实现了并发爬虫. 并且,也提到了这种并发爬虫的实现可以提高爬 ...
- golang实现并发爬虫二(简单调度器)
上篇文章当中实现了单任务版爬虫. 那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫.加快我们爬取的速度. 话不多说,先看图: 其实呢,实现方法就是加了一个sched ...
随机推荐
- SpringBoot+Maven 多模块项目的构建、运行、打包实战
前言 最近在做一个很复杂的会员综合线下线上商城大型项目,单模块项目无法满足多人开发和架构,很多模块都是重复的就想到了把模块提出来,做成公共模块,基于maven的多模块项目,也好分工开发,也便于后期微服 ...
- 花1个月时间准备 面试华为,薪资和定级都谈好了却被拒,HR竟说......
说在前面,千万不要频繁跳槽. 本来华为很想去的,面试前花了一个月的时间准备,面试过程挺顺利的,也拒绝了其他的所有面试邀请,而我拒绝其他面试邀请的底气,则是之前面试过程中的良好表现,薪资和定级都谈好了. ...
- 21JavaScript笔记(1)
JavaScript 基于对象和事件驱动 简单描述性语言 函数优先 解释型(即时编译型) 具有安全性的脚本语言 1.js组成 核心语法(ECMAScript):开放的.标准的脚本语言规范,主要包含了语 ...
- Shell-09-文本处理awk
awk 详情见: awk
- MongoDB实例重启失败探究(大事务Redo导致)
1.实例重启背景 收到监控组同学反馈,连接某一个MongoDB实例的应用耗时异常,并且出现了超时.查看数据库监控平台,发现此实例服务器的IO异常飙升,而查看副本集状态(rs.status()),主从是 ...
- JVM钩子函数的使用
一.问题引入 背景 在编写一个需要持续在后台运行的程序的时候遇到了这样的场景:我的程序在主函数中创建了一个线程池周期性地执行任务,我希望主线程和线程池都持续运行,但如果收到外部的关闭信号时,主线程和线 ...
- SwiftUI图片处理(缩放、拼图)
采用SwiftUI Core Graphics技术,与C#的GDI+绘图类似,具体概念不多说,毕竟我也是新手,本文主要展示效果图及代码,本文示例代码需要请拉到文末自取. 1.图片缩放 完全填充,变形压 ...
- STM32—串口使用总结
文章目录 一.仅向上位机打印调试信息 二.与上位机交互信息 三.作为驱动接口 四.结合DMA接收数据帧 在日常学习中,串口经常作为和上位机通信的接口,进行打印信息方便调试程序,有时也会作为模块的驱动接 ...
- 解决Mongoose 返回的文档过大导致模板引擎art-template无法渲染的问题,错误-RangeError: Maximum call stack size exceeded
参考:https://blog.csdn.net/qq_40659195/article/details/88411838 最近尝试用Node写一个小案例,使用到了MongoDB,使用过的人可以知道, ...
- Dom4j(解析property)
Dom4j(解析property) public class XpathTest { /** * XPath 使用路径表达式来选取 XML 文档中的节点或节点集 * * 经常使用到的路径表达式,如下 ...