golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看:
上文中的用简单的调度器实现了并发爬虫。
并且,也提到了这种并发爬虫的实现可以提高爬取效率。
当workerCount为1和workerCount为10时其爬取效率是有明显不同的。
然而,文末其实也提到了这个简单调度器实现的爬虫有个不可控或者说是控制力太小了的问题。
究其原因就是因为我们实现的方法是来一个request就给创建一个groutine。
为了让这个程序变得更为可控。得想想怎么可以优化下了。
现在,非常明显,优化点就是我不想要来一个request就创建一个这个实现过程。
那么,我们可以想到队列。
把request放到request队列里。
那么,request队列里一定是会有一个request的头的,我们就可以把这个request的头元素给到worker去做实现。
也就是这样:

but,这样是没有对worker进行一个控制的。
我们希望request可以选择我们想要的一个worker。
那么,我们也可以让scheduler维护一个worker的队列。
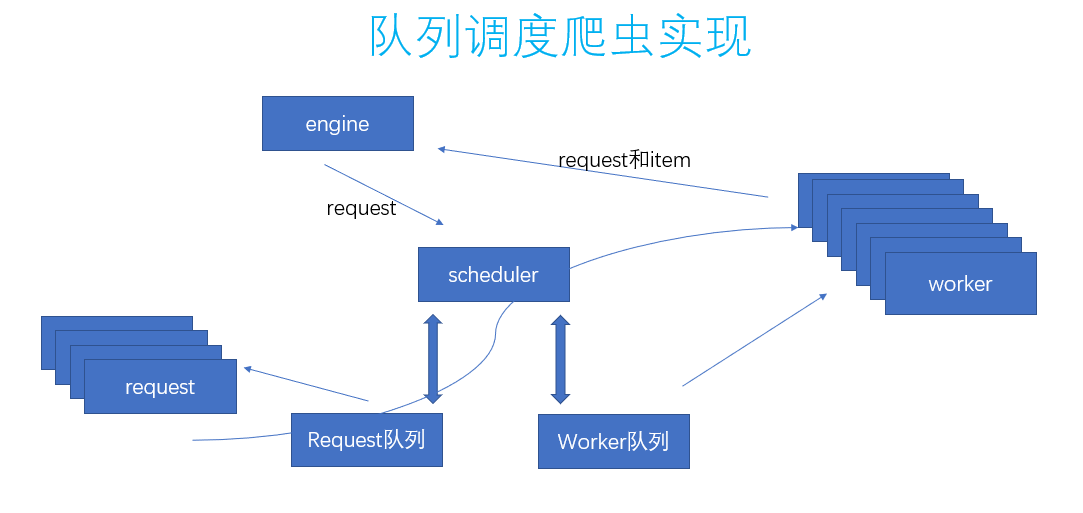
这里用了三个并行的模块:
1.engine 引擎模块。
2.scheduler 调度器模块。
3.worker 工作模块。
这三者通信都是通过channel来通信的。
上图中可知道调度器模块实际上是维护了2个channel,一个是request的channel,一个是worker的channel。
//队列调度器
//这个scheduler与engine和worker之间的通信都是通过channel来连接的。
//故尔它的肚子里应该有request相关的channel和worker相关的channel.
//另外注意这里worker的channel的类型是chan Request。
type QueuedScheduler struct {
requestChan chan con_engine.Request
workerChan chan chan con_engine.Request
}
那么,我们就只需要在这个scheduler调度器的两个channel里,各取一个元素,即取request和worker(chan con_engine.Request),把request发给worker就可以了。
一直不断的去取和发送,这就是这个队列调度器要做的事情了。
那个弯曲的箭头也就是指的这个事情了。在request的队列里找到合适的request发给worker队列里合适的worker就好。
这就是一个整体的思想了。
稍微说下关于维护如何两个队列的代码。
重点在于怎么才能做到各读取一个元素。
channel的读取是会阻塞的。
如果我先读取request,如果读取不到,那么在等待的时候就没有办法取到worker了。
解决方案就是用select,因为select会保证一点,select里的每一个case都会被执行到且会很快速的执行。
func (s *QueuedScheduler) Run() {
s.requestChan = make(chan con_engine.Request) //指针接收者才能改变里面的内容。
s.workerChan = make(chan chan con_engine.Request)
go func() {
var requestQ []con_engine.Request
var workerQ []chan con_engine.Request
for {
var activeRequest con_engine.Request
var activeWorker chan con_engine.Request
if len(requestQ) > && len(workerQ) > {
activeRequest = requestQ[]
activeWorker = workerQ[]
}
//收到一个request就让request排队,收到一个worker就让worker排队。所有的channel操作都放到select里。
select {
case r := <-s.requestChan:
requestQ = append(requestQ, r)
case w := <-s.workerChan:
workerQ = append(workerQ, w)
case activeWorker <- activeRequest:
requestQ = requestQ[:]
workerQ = workerQ[:]
}
}
}()
}
select就是在做三件事情:
1.从requestChan里收一个request,将这个request存在变量requestQ里。
2.从workerChan里收一个worker,将这个worker存在变量workerQ里。
3.把第一个requestQ里的第一个元素发给第一个workerQ里的第一个元素。
其他代码就感兴趣的同学自己看吧。
作者就先说到这里。
总体调度的思想上面的图中。
具体的实现在源码里。
欢迎大家留言指教。
源码:
https://github.com/anmutu/du_crawler/tree/master/04crawler
疫情期间的佛系小程序:
https://www.zmfei4.com/ (谐音:怎么肥四?)

店家已经不愿意经营,看看就好。
golang实现并发爬虫三(用队列调度器实现)的更多相关文章
- golang实现并发爬虫二(简单调度器)
上篇文章当中实现了单任务版爬虫. 那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫.加快我们爬取的速度. 话不多说,先看图: 其实呢,实现方法就是加了一个sched ...
- golang实现并发爬虫一(单任务版本爬虫功能)
目的是写一个golang并发爬虫版本的演化过程. 那么在演化之前,当然是先跑通一下单任务版本的架构. 正如人走路之前是一定要学会爬走一般. 首先看一下单任务版本的爬虫架构,如下: 这是单任务版本爬虫的 ...
- golang版并发爬虫
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/ 简单分析后发现每页的url呈加1趋势 第一页: http://www.budejie.com/text ...
- Golang调度器GMP原理与调度全分析(转 侵 删)
该文章主要详细具体的介绍Goroutine调度器过程及原理,包括如下几个章节. 第一章 Golang调度器的由来 第二章 Goroutine调度器的GMP模型及设计思想 第三章 Goroutine调度 ...
- Golang/Go goroutine调度器原理/实现【原】
Go语言在2016年再次拿下TIBOE年度编程语言称号,这充分证明了Go语言这几年在全世界范围内的受欢迎程度.如果要对世界范围内的gopher发起一次“你究竟喜欢Go的哪一点”的调查,我相信很多Gop ...
- 第1节 yarn:14、yarn集群当中的三种调度器
yarn当中的调度器介绍: 第一种调度器:FIFO Scheduler (队列调度器) 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源 ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- 大数据之Yarn——Capacity调度器概念以及配置
试想一下,你现在所在的公司有一个hadoop的集群.但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求.那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这 ...
- MapReduce多用户任务调度器——容量调度器(Capacity Scheduler)原理和源码研究
前言:为了研究需要,将Capacity Scheduler和Fair Scheduler的原理和代码进行学习,用两篇文章作为记录.如有理解错误之处,欢迎批评指正. 容量调度器(Capacity Sch ...
随机推荐
- 【深度强化学习】Curriculum-guided Hindsight Experience Replay读后感
目录 导读 目录 正文 Abstract[摘要] Introduction[介绍] 导读 看任何一个领域的文章,一定要看第一手资料.学习他们的思考方式,论述逻辑,得出一点自己的感悟.因此,通过阅读pa ...
- 用卷积神经网络和自注意力机制实现QANet(问答网络)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 在这篇文章中,我们将解决自然语言处理(具体是指问答)中最具挑战性 ...
- Python python 数据类型的相互转换
# number 之间的相互转换 # int <=> float var1 = 1; print(type(var1)) #<class 'int'> res1 = float ...
- MATLAB——文件读写(2)
一.importdata函数 1. txt 如图,提取经纬度. 程序如下 clear all test=importdata('经纬度.txt'); [r,c]=size(test.data);%ro ...
- MATLAB——文件读写(1)
1.文件打开关闭 (1)文件打开 fid=fopen(文件名,‘打开方式’)说明:其中fid用于存储文件句柄值,如果返回的句柄值大于0,则说明文件打开成功.文件名用字符串形式,表示待打开的数据文件.常 ...
- POJ 3273Monthly Expense(二分答案)
题目链接 思路如下 题意:这一题让我们在一个 n 个数的序列,分成连续的的 m个子串(一个数也可是一个子串),是在所有子串中 和最大的子串 的和最小. 思路:我们可以用 二分法 来一个一个枚举答案,二 ...
- XXE验证与利用流程
特征 特征1 --- .ashx 看到url是 .ashx后缀的 特征2 --- 响应体是xml 发现有这些特征都可以用下面的流程测试 测试 在线工具: http://ceye.io/ http:// ...
- PTA数据结构与算法题目集(中文) 7-39魔法优惠券 (25 分)
PTA数据结构与算法题目集(中文) 7-39魔法优惠券 (25 分) 7-39 魔法优惠券 (25 分) 在火星上有个魔法商店,提供魔法优惠券.每个优惠劵上印有一个整数面值K,表示若你在购买某商 ...
- LeetCode#141-Linked List Cycle-环形链表
一.题目 给定一个链表,判断链表中是否有环. 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始). 如果 pos 是 -1,则在该链表中没有环. 示例 1 ...
- spring的jdbc具名参数
在jdbc的模板中使用具名参数: 1.就需要在之前的jdbc的例子中进行修改:需要在xml文件中重新配置一个bean.这是固定的格式.如下 对于使用具名参数而言.配置NamedParameterJdb ...