sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑
在SKLearn中,StratifiedShuffleSplit 类实现了对数据集进行洗牌、分割的功能。但在今晚的实际使用中,发现该类及其方法split()仅能够对二分类样本有效。
一个简单的例子如下:
1 import numpy as np
2 from sklearn.model_selection import StratifiedShuffleSplit
3
4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]])
5 l5 = np.array([0,1,0,2])
6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1)
7 for train_idx, valid_idx in splt.split(l4, l5):
8 print(train_idx,valid_idx)
9 print('=======')
10 print(l4[train_idx],l4[valid_idx])
11 print('=======')
12 print(l5[train_idx],l5[valid_idx])
l4 为样本输入列表,l5 为样本输出列表,其中,样本输出(l5)共有3类:[0,1,2] 此时,运行程序会报错:
ValueError: The least populated class in y has only 1 member, which is too few. The minimum number of groups for any class cannot be less than 2.

报错信息的字面意思是:我样本输出仅有1类,需要最少2类。但问题是我实际上有3类输出样本。这个问题百度了半天也没找到合适的解答。
后面将3类样本改为2类,该函数就能正常运行了。
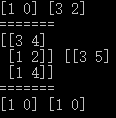
1 import numpy as np
2 from sklearn.model_selection import StratifiedShuffleSplit
3
4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]])
5 l5 = np.array([0,1,0,1])
6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1)
7 for train_idx, valid_idx in splt.split(l4, l5):
8 print(train_idx,valid_idx)
9 print('=======')
10 print(l4[train_idx],l4[valid_idx])
11 print('=======')
12 print(l5[train_idx],l5[valid_idx])
注意,在上方代码第5行,将 l5 的值进行修改,样本输出仅有[0,1]两类。
此时运行程序,运行无误。
StratifiedShuffleSplit.split() 函数对于多分类问题还是无法正确适配。
sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑的更多相关文章
- Date()日期函数浏览器兼容问题踩坑
原文:Date()日期函数浏览器兼容问题踩坑 之前用layui做的一项目中,table中用到了日期格式化的问题.直接没多想,撸代码就完了呗,结果最近一段时间客户反馈说显示日期跟录入日期不一样(显示日期 ...
- Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历
Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历 https://www.cnblogs.com/shuxiaolong/p/DotNet_Task_BUG.html 异步Task简单 ...
- 机器学习实战基础(十九):sklearn中数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在 ...
- 『审慎』.Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历
异步Task简单介绍 本标题有点 哗众取宠,各位都别介意(不排除个人技术能力问题) —— 接下来:我将会用一个小Demo 把 本文思想阐述清楚. .Net 4.0 就有了 Task 函数 —— 异步编 ...
- sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串
1简述问题 使用countVectorizer()将文本向量化时发现,文本中长度唯一的字符串会被自动过滤掉,这对于我在做的情感分析来讲,一些表较重要的表达情感倾向的词汇被过滤掉,比如文本'没用的东西, ...
- Python中字符串操作函数string.split('str1')和string.join(ls)
Python中的字符串操作函数split 和 join能够实现字符串和列表之间的简单转换, 使用 .split()可以将字符串中特定部分以多个字符的形式,存储成列表 def split(self, * ...
- 转载 --- SKLearn中预测准确率函数介绍
混淆矩阵 confusion_matrix 下面将一一给出'tp','fp','fn'的具体含义: 准确率: 所有识别为"1"的数据中,正确的比率是多少. 如识别出来100个结果是 ...
- C# 中奇妙的函数–String Split 和 Join
很多时候处理字符串数据,比如从文件中读取或者存入 - 我们可能需要加入分隔符(如CSV文件中的逗号),或使用一个分隔符来合并字符串序列. 很多人都知道使用split()的方法,但使用与其对应的Join ...
- sklearn中的cross_val_score()函数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verb ...
随机推荐
- C++运算符重载的一些困惑
一.背景 在复习<C++基础与提高>时,自己实现运算符重载(i++)时,几次都报错.其实还是自己对运算符重载这一部分内容理解得不够透彻,于是再次看了下书上的内容,理解算是加深了一些,于是提 ...
- 深入学习spring cloud gateway 限流熔断
前言 Spring Cloud Gateway 目前,Spring Cloud Gateway是仅次于Spring Cloud Netflix的第二个最受欢迎的Spring Cloud项目(就GitH ...
- Debian10 安装MyCLI
1 概述 Debian10安装MyCLI. 环境: Debian10 Python3.7 2 准备环境 2.1 Python 首先确保安装了Python: apt install python3 若是 ...
- Manjaro 安装教程
1 概述 本文讲述了如何在单硬盘下对Manjaro进行安装. 2 写U盘 首先第一步是下载镜像,官网下载地址戳这里,如果下载速度慢可以选择国内镜像,比如戳这里. 笔者选择的是XFCE桌面: 下载好后将 ...
- Fiddler 菜单功能 Host配置 请求伪造 接口调试
菜单功能: Fiddler工具栏上每个按钮的功能只要鼠标停留在按钮上面就会出现英文描述的功能. 小气泡:增加备注,点击气泡即可对下面捕捉到的会话增加备注(很少使用) Replay回放按钮:较常用,捕捉 ...
- HashMap、ConcurrentHashMap 1.7和1.8对比
本篇内容是学习的记录,可能会有所不足. 一:JDK1.7中的HashMap JDK1.7的hashMap是由数组 + 链表组成 /** 1 << 4,表示1,左移4位,变成10000,即1 ...
- Appium 简介与自动化测试环境搭建
1. Appium 简介 2. Appium 自动化测试环境搭建 1. Appium 简介 Appium 是一个开源测试自动化框架,可用于原生,混合和移动 Web 应用程序测试. 它使用 WebDri ...
- Oralce注入 bypass waf出数据
发存货: 探测banner 版本号: ' and (SELECT banner FROM v$version where rownum=1) like 'O%' and '1'like'1 rownu ...
- day-26-封装-property装饰器-反射
一.super进阶 在多继承中:严格按照mro顺序来执行 super是按照mro顺序来寻找当前类的下一类 在py3中不需要传参数,自动就帮我们寻找当前类的mro顺序的下一个类中的同名方法 在py2中的 ...
- hdu2235 机器人的容器
题意: 机器人的容器 Time Limit: 3000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...