[BD] HBase
NoSQL数据库
- 关系型数据库:用表格的行-列来保存数据,OLTP,写入多,行式存储
- 非关系型数据库:只用来存储数据,业务逻辑由应用程序处理,OLAP,查询多,列式存储
- 常见NoSQL数据库
- Redis:基于内存的NoSQL数据库
- MongoDB:基于文档型(BSON)的NoSQl数据库
- 设计一个数据库保存电影信息
- Oracle:至少三张表,每张1000行,笛卡尔积1000*1000*1000,性能低
- MongoDB:只有1000条记录,查询快(MongoDB 4.0 开始支持事务,支持分布式存储和MapReduce)

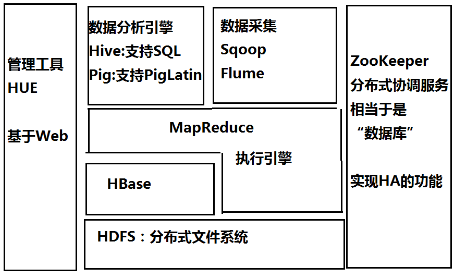
HBase
- Hadoop Database
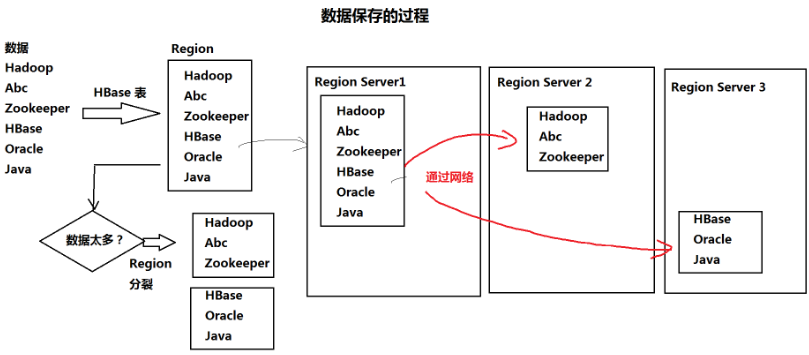
- 以HDFS作为最基本的存储单元(表、列族-->目录,数据-->文件)
- 可快速随机访问海量结构化数据
- 支持数据随机查找,增量数据处理,数据更新
- 适用于大量数据存储,大量数据高并发操作,需要对数据进行随机读写的简单操作
- 内部使用哈希表,通过索引对HDFS文件中的数据进行快速查找(HDFS只能顺序访问)
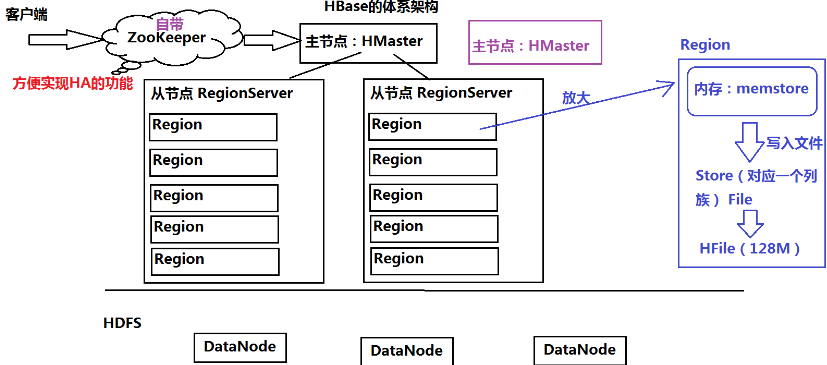
- Zookeeper实现HA
安装
- 本地:单机,不需要HDFS,数据直接保存在操作系统,只启动HMaster
- 解压->设置环境变量->改配置文件(hbase-env.sh,hbase-site.xml)
- 伪分布:单机模拟分布式,ZK+HMaster+RegionServer
- 改配置文件(hbase-env.sh,hbase-site.xml)
- 依赖HDFS和ZK,必须先启动
- 全分布
- HA
过程
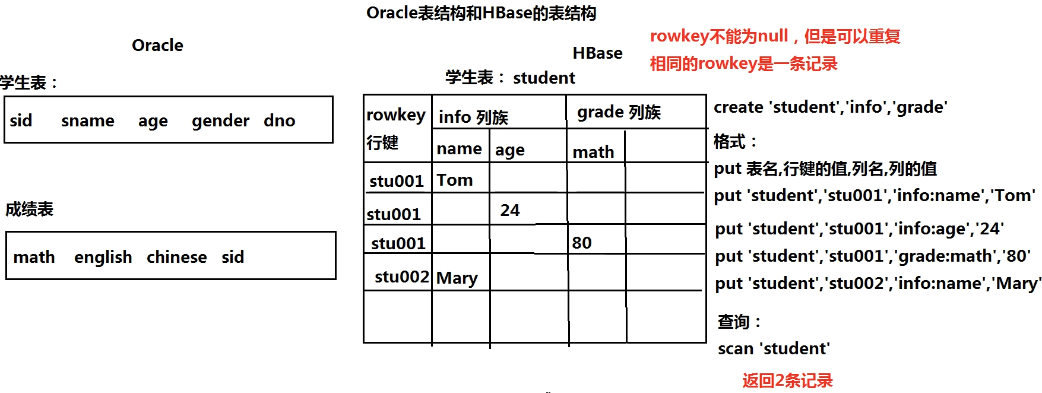
- 在HBase中创建表,参数--表名、列族
- 增加列,参数--列名
- 插入数据,参数--表名,行名,列名,值
命令
- 启动:start-hbase.sh
- 命令行工具:hbase shell
- 查看所有表:list
- 创建表:create 'student','info','grade'
- 插入数据:put 'student','stu001','info:name','Tom'
- 查看表:scan 'student'
- 停用表:disable 'student'
- 删除表:drop 'student'
- 删除命名空间:drop_namespace 'school'
Java API
- 启动hdfs
- 运行Java API
- 在hbase shell中查看


1 package Demo.base;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.hbase.HColumnDescriptor;
5 import org.apache.hadoop.hbase.HTableDescriptor;
6 import org.apache.hadoop.hbase.TableName;
7 import org.apache.hadoop.hbase.client.Get;
8 import org.apache.hadoop.hbase.client.HBaseAdmin;
9 import org.apache.hadoop.hbase.client.HTable;
10 import org.apache.hadoop.hbase.client.Put;
11 import org.apache.hadoop.hbase.client.Result;
12 import org.apache.hadoop.hbase.client.ResultScanner;
13 import org.apache.hadoop.hbase.client.Scan;
14 import org.apache.hadoop.hbase.util.Bytes;
15 import org.junit.Test;
16
17 /*
18 * 注意:需要:hamcrest-core-1.3.jar包
19 */
20 public class TestHbase {
21
22 @Test
23 public void testCreateTable() throws Exception{
24 //创建表
25 //配置ZooKeeper地址
26 Configuration conf = new Configuration();
27 conf.set("hbase.zookeeper.quorum", "192.168.174.111");
28
29 //得到一个HBase的客户端
30 HBaseAdmin client = new HBaseAdmin(conf);
31
32 //采用:面向对象的思想来建表
33 //1、指定表的描述符
34 HTableDescriptor htd = new HTableDescriptor(TableName.valueOf("mytable"));
35
36 //2、指定列族
37 htd.addFamily(new HColumnDescriptor("info"));
38 htd.addFamily(new HColumnDescriptor("grade"));
39
40 //创建表
41 client.createTable(htd);
42
43 //关闭客户端
44 client.close();
45 }
46 @Test
47 public void testPutData() throws Exception{
48 //插入数据
49 //配置ZooKeeper地址
50 Configuration conf = new Configuration();
51 conf.set("hbase.zookeeper.quorum", "192.168.174.111");
52
53 //得到一个客户端
54 HTable client = new HTable(conf, "mytable1");
55
56 //构造一个Put对象:一条数据
57 Put put = new Put(Bytes.toBytes("id001"));
58
59 //指定列的值
60 /*
61 put.addColumn(family, 列族的名字
62 qualifier, 列的名字
63 value) 值
64 */
65 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Tom"));
66
67 // 一次插入多条记录client.put(List);
68
69 client.put(put);
70
71 client.close();
72 }
73 }
参考
/etc/profile 和 ~/.bash_profile 的区别
http://blog.chinaunix.net/uid-14735472-id-3190130.html
hbase shell 中退格无法使用的解决方法
https://blog.csdn.net/zhangchen124/article/details/92801219
hbase shell 常用命令
https://blog.csdn.net/vbirdbest/article/details/88236575
put流程
https://blog.csdn.net/yangzishiw/article/details/53910775
region机制
https://blog.csdn.net/DianaCody/article/details/39530165
深入理解hbase
https://segmentfault.com/a/1190000019959411
HBase创建命名空间的API操作,抛异常的坑
https://blog.csdn.net/wx1528159409/article/details/85266856
HDFS数据写入HBase
https://blog.csdn.net/lianghecai52171314/article/details/104801847/
列式存储
https://blog.csdn.net/zl1zl2zl3/article/details/86632044
https://blog.csdn.net/dc_726/article/details/41143175
https://zhuanlan.zhihu.com/p/129342230
[BD] HBase的更多相关文章
- 读取hive文件并将数据导入hbase
package cn.tansun.bd.hbase; import java.io.IOException; import java.net.URI; import java.util.List; ...
- client 如何找到正确的RegionServer(HBase -ROOT-和.META.表)
在HBase中,大部分的操作都是在RegionServer完成的,Client端想要插入,删除,查询数据都需要先找到相应的RegionServer.什么叫相应的RegionServer?就是管理你要操 ...
- Hbase案例分析(一)
Hbase应用场景: 1 随机读或者写 2 大数据上的高并发操作,比如每秒对PB级数据进行上千次操作.(查询,删除等操作) 3 读写均是非常简单的操作,比如没有join操作 Hbase Schema设 ...
- hbase 性能优化 (转载)
一.服务端调优 1.参数配置 1).hbase.regionserver.handler.count:该设置决定了处理RPC的线程数量,默认值是10,通常可以调大,比如:150,当请求内容很大(上MB ...
- 【转载】Hadoop 2.7.3 和Hbase 1.2.4安装教程
转载地址:http://blog.csdn.net/napoay/article/details/54136398 目录(?)[+] 一.机器环境 系统:MAC OS Hadoop:2.7.3 H ...
- Ubuntu16.04下HBase的安装与配置
一.环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : mysql : hive : hbase: -hadoop2 安装HBase前,系统 ...
- Lily hbase indexer搭建配置概要文档
1.solrcloud搭建好2.hbase-solr-indexer服务开启3.确定hbase中的对应的表开启replication功能 create '} // 1表示开启replication 已 ...
- HBase 协处理器统计行数
环境:cdh5.1.0 启用协处理器方法1. 启用协处理器 Aggregation(Enable Coprocessor Aggregation) 我们有两个方法:1.启动全局aggregation, ...
- hive与hbase数据类型对应关系
hive与hbase数据类型对应关系 当hbase中double,int 类型以byte方式存储时,用字符串取出来必然是乱码. 在hivd与hbase整合时也遇到这个问题:做法是:#b 1.加#b C ...
随机推荐
- OpenCV 之 平面单应性
上篇 OpenCV 之 图象几何变换 介绍了等距.相似和仿射变换,本篇侧重投影变换的平面单应性.OpenCV相关函数.应用实例等. 1 投影变换 1.1 平面单应性 投影变换 (Projectiv ...
- IndentationError:unexpected indent”、“IndentationError:unindent does not match any outer indetation level”以及“IndentationError:expected an indented block Python常见错误
错误的使用缩进量 记住缩进增加只用在以:结束的语句之后,而之后必须恢复到之前的缩进格式. 经典错误,一定要注意缩进,尤其是在非界面化下环境的代码修改
- Spring Cloud:面向应用层的云架构解决方案
Spring Cloud:面向应用层的云架构解决方案 上期文章我们介绍了混合云,以及在实际操作中我们常见的几种混合云模式.今天我们来聊一聊Spring Cloud如何解决应用层的云架构问题. 对于Sp ...
- 截取pod ip地址最后一列
资源清单: --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: init-demo namespace: test ...
- js 日期加减
加: console.log(moment().format("YYYY-MM-DD HH:mm:ss")); //当前时间 console.log(moment().add(10 ...
- OO 第一单元
OO第一单元总结 前言 第一单元 OO 作业的主题是求导,从最简单的幂函数求导,到添加三角函数求导,再到最后添加嵌套规则.(对熬夜有了新体验,OO 作业比较适合晚上写,OO 博客也是一样 doge) ...
- JavaScript深入理解-正则表达式
正则表达式 正则表达式是用于匹配字符串中字符组合的模式.在JavaScript中,正则表达式也是对象.这些模式被用于RegExp的 exec和 text方法,以及String中的 match.matc ...
- 并发编程(共享模型之管程wait notify)
本文主要讲解wait/notify的正确使用姿势.park/unpark.join()的原理.模式之生产者-消费者模式(异步).保护性暂停模式(同步).线程状态转换的流程.死锁和活锁以及如何检查死锁等 ...
- 解决CentOS虚拟机无法显示本地IP问题
1 问题描述 CentOS虚拟机无法显示本地ip,如图: 2 尝试过的方法 参考过此处的解决方法,把网卡配置中的ONBOOT修改为YES: 但是原来的网卡配置也是YES,所以修改的方法没有用,尝试了一 ...
- [kuangbin]专题六 最小生成树 题解+总结
kuangbin专题链接:https://vjudge.net/article/752 kuangbin专题十二 基础DP1 题解+总结:https://www.cnblogs.com/RioTian ...