livy提交spark应用
spark-submit的使用shell时时灵活性较低,livy作为spark提交的一种工具,是使用接口或者java客户端的方式提交,可以集成到web应用中
1.客户端提交的方式
http://livy.incubator.apache.org/docs/latest/programmatic-api.html
核心代码
LivyClient client = new LivyClientBuilder()
.setURI(new URI(livyUrl))
.build(); try {
System.err.printf("Uploading %s to the Spark context...\n", piJar);
client.uploadJar(new File(piJar)).get(); System.err.printf("Running PiJob with %d samples...\n", samples);
double pi = client.submit(new PiJob(samples)).get(); System.out.println("Pi is roughly: " + pi);
} finally {
client.stop(true);
}
2.REST API
http://livy.incubator.apache.org/docs/latest/rest-api.html
1.以最常使用的batches接口作为例子,请求参数
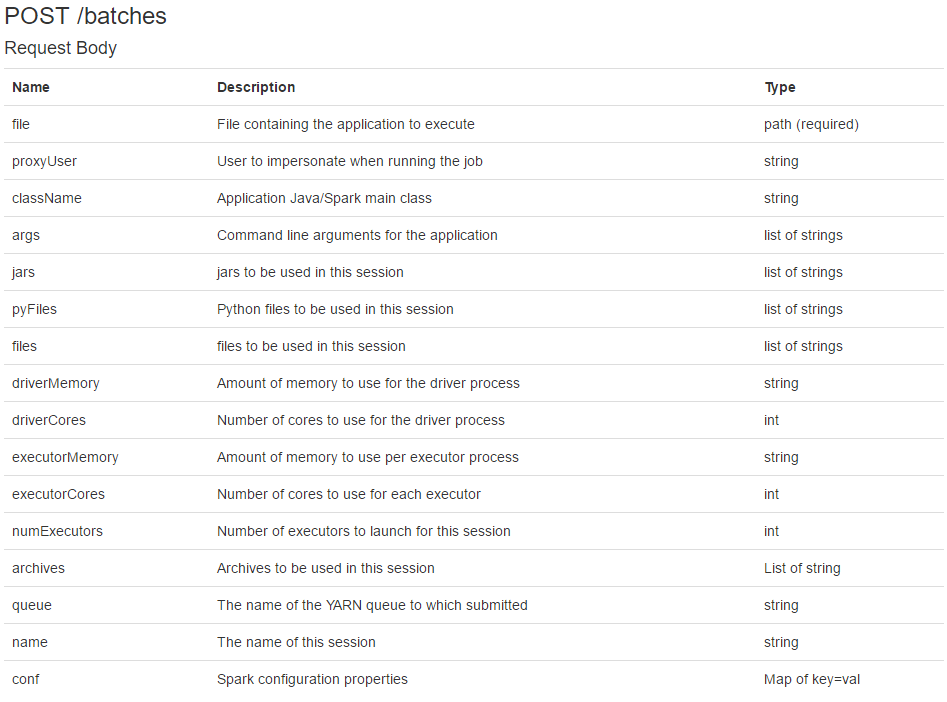
rest 的http
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpDelete;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class HttpUtils {
//post 请求
public String postAccess(String url, Map<String, String> headers, String data) { HttpPost post = new HttpPost(url);
if (headers != null && headers.size() > 0) {
headers.forEach((K, V) -> post.addHeader(K, V));
}
try {
StringEntity entity = new StringEntity(data);
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
post.setEntity(entity);
HttpResponse response = httpClient.execute(post);
HttpEntity resultEntity = response.getEntity();
result = EntityUtils.toString(resultEntity);
return result;
} catch (Exception e) {
e.printStackTrace();
logger.error("postAccess执行有误" + e.getMessage());
}
return result;
}
}
livy提交spark应用类,异步线程进行状态打印或者也可以状态监控返回web端
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.wanmi.sbc.dw.utils.GsonUtil;
import com.wanmi.sbc.dw.utils.HttpUtils;
import lombok.SneakyThrows;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.BeanUtils;
import org.springframework.stereotype.Component; import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List; /**
* @ClassName: com.spark.submit.impl.livy.LivyApp
* @Description: livy提交spark任务
* @Author: 小何
* @Time: 2020/12/15 10:46
* @Version: 1.0
*/
@Component
public class LivyServer {
private static final Logger logger = LoggerFactory.getLogger(LivyServer.class); private static final List<String> FAIl_STATUS_LIST = Arrays.asList("shutting_down", "error", "dead", "killed");
private final HashMap<String, String> headers; private HttpUtils httpUtils; public LivyServer() {
headers = new HashMap<>();
headers.put("Content-Type", "application/json");
headers.put("X-Requested-By", "admin");
} /**
* 提交参数
*
* @param livyParam
* @return
*/
@SneakyThrows
public String batchSubmit(LivyParam livyParam) {
this.httpUtils = new HttpUtils();
String livyUri = livyParam.getLivyUri();
LivyParam livyParamCopy = new LivyParam();
BeanUtils.copyProperties(livyParam, livyParamCopy);
livyParamCopy.setLivyUri(null);
String request = GsonUtil.toJsonString(livyParamCopy);
logger.info("任务提交信息{}", request);
String result = httpUtils.postAccess(livyUri + "/batches", headers, request);
if (!GsonUtil.isJson(result)) {
logger.info("任务提交错误:{}", result);
return "error:" + result;
}
if (result == null) {
return "error:" + "livy地址:" + livyUri + "错误,请检查";
}
logger.info("提交返回任务返回信息:{}", result);
JSONObject jsonObject = JSONObject.parseObject(result);
String state = jsonObject.getString("state");
String id = jsonObject.getString("id");
Thread thread = new Thread(() -> {
try {
queryState(livyParam.getLivyUri(), id, state);
} catch (InterruptedException | IOException e) {
logger.error("线程运行出错:{}", e.fillInStackTrace());
}
}, livyParam.getName() + System.currentTimeMillis());
thread.start();
return result;
} //提交任务执行状态验证
public void queryState(String livyUrl, String batchId, String responseState) throws InterruptedException, IOException {
if (responseState != null && !FAIl_STATUS_LIST.contains(responseState)) {
boolean isRunning = true;
while (isRunning) {
String url = livyUrl + "/batches/" + batchId;
String batchesInfo = httpUtils.getAccess(url, headers);
JSONObject info = JSON.parseObject(batchesInfo);
String id = info.getString("id");
String sta = info.getString("state");
String appId = info.getString("appId");
String appInfo = info.getString("appInfo");
logger.info("livy:sessionId:{},state:{}", id, sta);
if ("success".equals(sta)) {
logger.info("任务{}:执行完成", appId, appInfo);
httpUtils.close();
isRunning = false;
} else if (FAIl_STATUS_LIST.contains(sta) || sta == null) {
logger.error("任务{}执行有误,请检查后重新提交:\n", appId, batchesInfo);
httpUtils.close();
isRunning = false;
} else if ("running".equals(sta) || "idle".equals(sta) || "starting".equals(sta)) {
logger.info("查看任务{},运行状态:\n{}", appId, batchesInfo);
} else {
logger.info("任务{}状态:{},未知,退出任务查看", id, sta);
isRunning = false;
}
Thread.sleep(5000);
}
}
}
}
livy请求参数
@Data
public class LivyParam {
/**
* livy的地址
*/
private String livyUri; /**
* 要运行的jar包路径
*/
private String file;
/**
* 运行的代理名
*/
private String proxyUser;
/**
* 运行主类
*/
private String className;
/**
* 主类的参数
*/
private List<String> args;
/**
* 需要运行的jar包
*/
private String thirdJarPath;
private List<String> jars;
private List<String> pyFiles;
private List<String> files;
private String driverMemory;
private Integer driverCores;
private String executorMemory;
private Integer executorCores;
private Integer numExecutors;
private List<String> archives;
/**
* 队列
*/
private String queue;
/**
* appName
*/
private String name;
/**
* 其他配置
*/
private Map<String, String> conf; }
测试
构建参数
new livyParam = new LivyParam();
livyParam.setLivyUri(sparkSubmitParam.getLivyUri());
livyParam.setClassName(sparkSubmitParam.getClassName());
livyParam.setArgs(sparkSubmitParam.getArgs());
livyParam.setConf(sparkSubmitParam.getConf());
livyParam.setDriverCores(sparkSubmitParam.getDriverCores());
livyParam.setDriverMemory(sparkSubmitParam.getDriverMemory());
livyParam.setArchives(sparkSubmitParam.getArchives());
livyParam.setExecutorCores(sparkSubmitParam.getExecutorCores());
livyParam.setExecutorMemory(sparkSubmitParam.getExecutorMemory());
livyParam.setJars(sparkSubmitParam.getJars());
livyParam.setFile(sparkSubmitParam.getFile());
livyParam.setName(sparkSubmitParam.getName());
livyParam.setQueue(sparkSubmitParam.getQueue());
livyParam.setProxyUser(sparkSubmitParam.getProxyUser()); //发送请求
String result = liveServer.batchSubmit(livyParam);
livy提交spark应用的更多相关文章
- Spark On Yarn:提交Spark应用程序到Yarn
转载自:http://lxw1234.com/archives/2015/07/416.htm 关键字:Spark On Yarn.Spark Yarn Cluster.Spark Yarn Clie ...
- 如何在Java应用中提交Spark任务?
最近看到有几个Github友关注了Streaming的监控工程--Teddy,所以思来想去还是优化下代码,不能让别人看笑话,是不.于是就想改在一下之前最丑陋的一个地方--任务提交 本博客内容基于Spa ...
- 利用SparkLauncher 类以JAVA API 编程的方式提交Spark job
一.环境说明和使用软件的版本说明: hadoop-version:hadoop-2.9.0.tar.gz spark-version:spark-2.2.0-bin-hadoop2.7.tgz jav ...
- 【Spark】提交Spark任务-ClassNotFoundException-错误处理
提交Spark任务-ClassNotFoundException-错误处理 Overview - Spark 2.2.0 Documentation Spark Streaming - Spark 2 ...
- Spark2.x(五十九):yarn-cluster模式提交Spark任务,如何关闭client进程?
问题: 最近现场反馈采用yarn-cluster方式提交spark application后,在提交节点机上依然会存在一个yarn的client进程不关闭,又由于spark application都是 ...
- Idea里面远程提交spark任务到yarn集群
Idea里面远程提交spark任务到yarn集群 1.本地idea远程提交到yarn集群 2.运行过程中可能会遇到的问题 2.1首先需要把yarn-site.xml,core-site.xml,hdf ...
- spark-submit提交spark任务的具体参数配置说明
spark-submit提交spark任务的具体参数配置说明 1.spark提交任务常见的两种模式 2.提交任务时的几个重要参数 3.参数说明 3.1 executor_cores*num_execu ...
- 提交Spark作业遇到的NoSuchMethodError问题总结
测试应用说明 测试的Spark应用实现了同步hive表到kafka的功能.具体处理流程: 从 ETCD 获取 SQL 语句和 Kafka 配置信息 使用 SparkSQL 读取 Hive 数据表 把 ...
- 基于Livy的Spark提交平台搭建与开发
为了方便使用Spark的同学提交任务以及加强任务管理等原因,经调研采用Livy比较靠谱,下图大致罗列一下几种提交平台的差别. 本文会以基于mac的单机环境搭建一套Spark+Livy+Hadoop来展 ...
随机推荐
- 一文搞懂RESTful API
RESTful接口实战 原创公众号:bigsai 转载请联系bigsai 文章收藏在回车课堂 前言 在学习RESTful 风格接口之前,即使你不知道它是什么,但你肯定会好奇它能解决什么问题?有什么应用 ...
- MySQL Docker容器实例创建并进入MySQL命令行
首先需要明白的一点是: docker镜像是一个模版,docker容器是一个实例,它可以被启动与关闭. 我们需要先有MySQL的docker镜像,使用命令: docker pull mysql 拉取最新 ...
- Docker 安装-在centos7下安装Docker(二)
参考docker安装的方式: http://www.runoob.com/docker/centos-docker-install.html Docker中文官网安装步骤:https://docs.d ...
- 总结下flask中的宏、Jinjia2语法
这几天学的东西比较多,时间又有点不够用,趁着快吃饭了,赶紧总结总结. 00x1 宏: 如果学过C语言的童鞋,可能知道宏在C语言里面是一个定义一个固定参数的变量.在flask里面,宏是相当于一个函数的作 ...
- python中的万能密码
在php中,我们经常见到这样的语句 if(isset($_GET['id'])) { $id=$_GET['id']; //logging the connection parameters to a ...
- mysql游标cursor与for循环
delimiter // create procedure p2() begin declare row_id int DEFAULT 0; declare row_num int DEFAULT 0 ...
- JavaScript异步编程的四种方法
1.回调函数 f1(f2); 回调函数是异步编程的基本方法.其优点是易编写.易理解和易部署:缺点是不利于代码的阅读和维护,各个部分之间高度耦合 (Coupling),流程比较混乱,而且每个任务只能指定 ...
- Java 8 新特性:Lambda、Stream和日期处理
1. Lambda 简介 Lambda表达式(Lambda Expression)是匿名函数,Lambda表达式基于数学中的λ演算得名,对应于其中的Lambda抽象(Lambda Abstract ...
- ARM开发工具下载地址汇总
一,下载地址 1,ARM DS5官方下载地址https://developer.arm.com/tools-and-software/embedded/legacy-tools/ds-5-develo ...
- Java基础语法吐血整理
前言 自己的Java理论知识方面一直都不是很好,决定从0开始好好总结下,把想到的和以前不确定的(查阅资料确定)的知识整理一下,加油!!坚持!!! Java概述 Java三大体系 1.JavaSE 标准 ...