Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用。
背景
在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移。大多数情况下,可以跟用户协商用离线的方式进行迁移,迁移离线数据的方式就比较容易了,将整个Hbase的data存储目录进行搬迁就行,但是当集群数据量比较多的时候,文件拷贝的时间很长,对客户的业务影响时间也比较长,往往在客户给的时间窗口无法完成,本文给出一种迁移思路,可以利用Hbase自身的功能,对集群进行迁移,减少集群业务中断时间。
简介
大家都知道Hbase有snapshot快照的功能,利用快照可以记录某个时间点表的数据将其保存快照,在需要的时候可以将表数据恢复到打快照时间时的样子。我们利用Hbase的snapshot可以导出某个时间点的全量数据。
因为用户的业务还在不停的写入表中,除了迁移快照时间点之前的全量数据,我们还需要将快照时间点后源源不断的增量数据也迁移走,这里如果能采用双写的方式,将数据写入两个集群就好了,但是用户的业务不会这样做,如果这样做还得保证双写的事务一致性。于是可以利用Hbase的replication功能,replication功能本身就是保留了源集群的WAL日志记录,去回放写入到目的集群,这样一来用户业务端->原始集群->目的集群便是个串形的数据流,且由Hbase来保证数据的正确性。
所以这个迁移的方法就是利用snapshot迁移全量数据,利用replication迁移增量数据。
迁移步骤
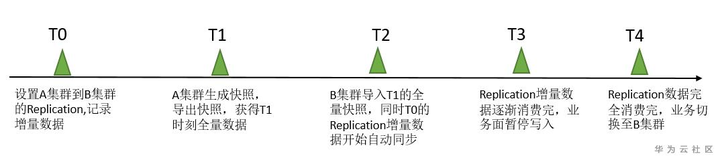
上图给出了迁移的整个时间线流程,主要有这么5个时间点。
T0: 配置好老集群A集群到新集群B的Replication关系,Replication的数据由A集群同步到集群B,将表设置成同步,从此刻开始新写入A集群表的数据会保留在WAL日志中;
T1: 生成该时间点的全量数据,通过创建快照,以及导出快照数据的方式将该时间点的数据导出到新集群B;
T2: 新集群B将T1时刻的快照数据导入,此时新集群B中会由快照创建出表,此时老集群A集群上设置的Replication的关系会自动开始将T0时刻保留的WAL日志回放至新集群B的表中,开始增量数据同步。
T3: 由于从T0-T3之间的操作会花费一段时间,此时会积累很多WAL日志文件,需要一定的时间来同步至新集群,这里需要去监控一下数据同步情况,等老集群WAL被逐渐消费完,此时可以将老集群的写业务停止一下并准备将读写业务全部切到新集群B。
T4: T3-T4之间应该是个很短的时间,整个迁移也只有这个时间点会有一定中断,此时是让用户将业务完全切到新集群B,至此迁移完成。
操作涉及的命令
1.设置集群A和集群B的peer关系
在源集群Hbase shell中, 设定peer
add_peer 'peer_name','ClusterB:2181:/Hbase'
2.在集群A的表中设置replication属性
假设目标表名为Student,先获取Family=f
进入Hbase shell中,
alter 'Student',{NAME => 'f',REPLICATION_SCOPE => '1'}
3.给集群A的表创建快照
在Hbase shell中
snapshot 'Student','Student_table_snapshot'
4.在A集群中导出快照
Hbase org.apache.hadoop.Hbase.snapshot.ExportSnapshot -snapshot Student_table_snapshot -copy-to /snapshot-backup/Student
5.将快照数据放置到集群B的对应的目录下
上面命令会导出2个目录,一个是快照元数据,一个是原始数据
将元数据放到/Hbase/.Hbase-snapshot中,将原始数据放到/Hbase/archive目录中
由于Hbase的archive目录会有个定时清理,这里可以提前将集群B的master的Hbase.master.cleaner.interval值设置大点,避免拷贝过程中发生碰巧发生了数据清理。
如果集群B中没有对应的目录,可以提前创建
hdfs dfs -mkdir -p /Hbase/.Hbase-snapshot
hdfs dfs -mkdir -p /Hbase/archive/data/default/
移动导出的snapshot文件到snapshot目录
hdfs dfs -mv /snapshot-backup/Student/.Hbase-snapshot/Student_table_snapshot /Hbase/.Hbase-snapshot/
hdfs dfs -mv /snapshot-backup/Student/archive/data/default/Student /Hbase/archive/data/default/
6.在新集群B中恢复表的快照
进入Hbase shell
restore_snapshot 'Student_table_snapshot'
恢复完成后,记得将集群B的hmaster中Hbase.master.cleaner.interval的值调整回来。
参考文档:
https://blog.csdn.net/qq475781638/article/details/95253603
https://support.huaweicloud.com/usermanual-mrs/mrs_01_0501.html
Hbase实用技巧:全量+增量数据的迁移方法的更多相关文章
- Mysql备份系列(4)--lvm-snapshot备份mysql数据(全量+增量)操作记录
Mysql最常用的三种备份工具分别是mysqldump.Xtrabackup(innobackupex工具).lvm-snapshot快照.前面分别介绍了:Mysql备份系列(1)--备份方案总结性梳 ...
- Mysql备份系列(2)--mysqldump备份(全量+增量)方案操作记录
在日常运维工作中,对mysql数据库的备份是万分重要的,以防在数据库表丢失或损坏情况出现,可以及时恢复数据. 线上数据库备份场景:每周日执行一次全量备份,然后每天下午1点执行MySQLdump增量备份 ...
- Elasticsearch 索引的全量/增量更新
Elasticsearch 索引的全量/增量更新 当你的es 索引数据从mysql 全量导入之后,如何根据其他客户端改变索引数据源带来的变动来更新 es 索引数据呢. 首先用 Python 全量生成 ...
- 【MySQL】全量+增量的备份/恢复
生产环境中,有时需要做MySQL的备份和恢复工作.因MySQL是在运行过程中的,做全量备份需要时间,全量备份完成后又有数据变动,此时需要增量备份辅助.如果想恢复数据到一个空库(例如数据迁移或者上云等更 ...
- Mysql备份系列(3)--innobackupex备份mysql大数据(全量+增量)操作记录
在日常的linux运维工作中,大数据量备份与还原,始终是个难点.关于mysql的备份和恢复,比较传统的是用mysqldump工具,今天这里推荐另一个备份工具innobackupex.innobacku ...
- 10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.创建MySQL数据 create database solr; use solr; DROP TABLE ...
- 将mysql数据同步到ES6.4(全量+增量)
下载安装包时注意下载到指定文件夹 这里我放在OPT文件夹下一:安装logstash进入到opt文件夹打开终端 执行以下命令wget -c https://artifacts.elastic.co/do ...
- Xtrabackup全量 增量备份详解
xtrabackup是Percona公司CTO Vadim参与开发的一款基于InnoDB的在线热备工具,具有开源,免费,支持在线热备,备份恢复速度快,占用磁盘空间小等特点,并且支持不同情况下的多种备份 ...
- flink-----实时项目---day05-------1. ProcessFunction 2. apply对窗口进行全量聚合 3使用aggregate方法实现增量聚合 4.使用ProcessFunction结合定时器实现排序
1. ProcessFunction ProcessFunction是一个低级的流处理操作,可以访问所有(非循环)流应用程序的基本构建块: event(流元素) state(容错,一致性,只能在Key ...
随机推荐
- React 服务端渲染方案完美的解决方案
最近在开发一个服务端渲染工具,通过一篇小文大致介绍下服务端渲染,和服务端渲染的方式方法.在此文后面有两中服务端渲染方式的构思,根据你对服务端渲染的利弊权衡,你会选择哪一种服务端渲染方式呢? 什么是服务 ...
- mysql-9-limit
#进阶9:分页查询 /* 当要显示的数据,一页显示不全,需要分页提交sql请求 SELECT FROM JOIN ON WHERE GROUP BY HAVING ORDER BY LIMIT off ...
- 072 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 04 综合案例-数组移位-在指定位置处插入数据方法
072 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 04 综合案例-数组移位-在指定位置处插入数据方法 本文知识点:综合案例-数组移位-在指定位置处插入数据方法 ...
- JVM 内存分配和占用
我们从一个简单示例来引出JVM的内存模型 简单示例 我从一个简单示例谈起这一块,我在看一篇文章的时候看到这么一个场景并且自己做了尝试,就是分配一个2M的数组,使用Xmx即最大内存为12M的话,会报错J ...
- background-size 详解
backgroun-size:cover; .是按照等比缩放铺满整个区域.主要用于图片比div小的时候,将图片按照某一边的比例扩大以填充整个div背景. .优点:图片不会被拉升,且实用于div长度和宽 ...
- 【linux】基础命令一
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ mount dir[] device[]umount devic[]maste ...
- nrf528xx bootloader 模块介绍
1. bootloader 的基本功能: 启动应用 几个应用之间切换 初始化外设 nordic nrf52xxx的bootloader主要功能用来做DFU, 可以通过HCI, UART 或BLE通信的 ...
- android init.rc语法
转自:http://www.cnblogs.com/nokiaguy/p/3164799.html init.rc由如下4部分组成. 动作(Actions) 命令(Commands) 3. 服务(Se ...
- 资源管理神器Clover
开开心心地上班,这时你得打开我的电脑,点进D盘,打开某个项目;然后还得打开XX文档,还有.... 最后的最后,你的桌面便成了这个样子 每天你都得天打开多个文件夹,切换时找文件找的晕头转向而烦恼. 每天 ...
- 【C语言编程入门笔记】C语言果然博大精深!函数还分内部和外部?
۞ 外部函数与内部函数 前面我们讲解了关于函数的调用都是针对同一个源文件中其他函数进行调用的,而在有些情况下,函数也可以对另外一个源文件中的函数进行调用.当一个程序由多个源文件组成时,根据函数是否能被 ...