简单盘点 CVPR2020 的图像合成论文
前言
本文将简单盘点在 CVPR2020 上的图像合成方面的论文,然后给出下载地址以及开源代码 github(如果有开源)。
原文:https://evgenykashin.github.io/2020/06/29/CVPR2020-Image-Synthesis.html
注意:作者介绍的这些论文都还没深入研究并做笔记,所以像 StyleGAN2 和 StarGAN2 并没有在下方介绍的论文列表中。以及一些视频是在 youtube 上的,后续我会考虑搬运到公众号或者 b 站上。
图像合成论文介绍
1. Cross-Domain Correspondence Learning for Exemplar-Based Image Translation
采用一张样例图片通过分割蒙版的方式生成图片。生成图片过程的风格都来自这张样例图片。实际上,如果有任意图片分割,还能允许你编辑任意的图片。通过分割图和样例图,算法可以用不同的编码器提取特征到同一个隐式空间中,接着它们会寻找相互之间如何扭曲以及扭曲样例图片,然后加入通过 AdaIN 得到特征的生成器,一起进一步提升性能。
论文的介绍可以查看这个视频:
https://youtu.be/RkHnQYn9gR0
论文的下载地址:https://arxiv.org/abs/2004.05571
论文官网:https://panzhang0212.github.io/CoCosNet/
开源代码:https://github.com/microsoft/CoCosNet
2. SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
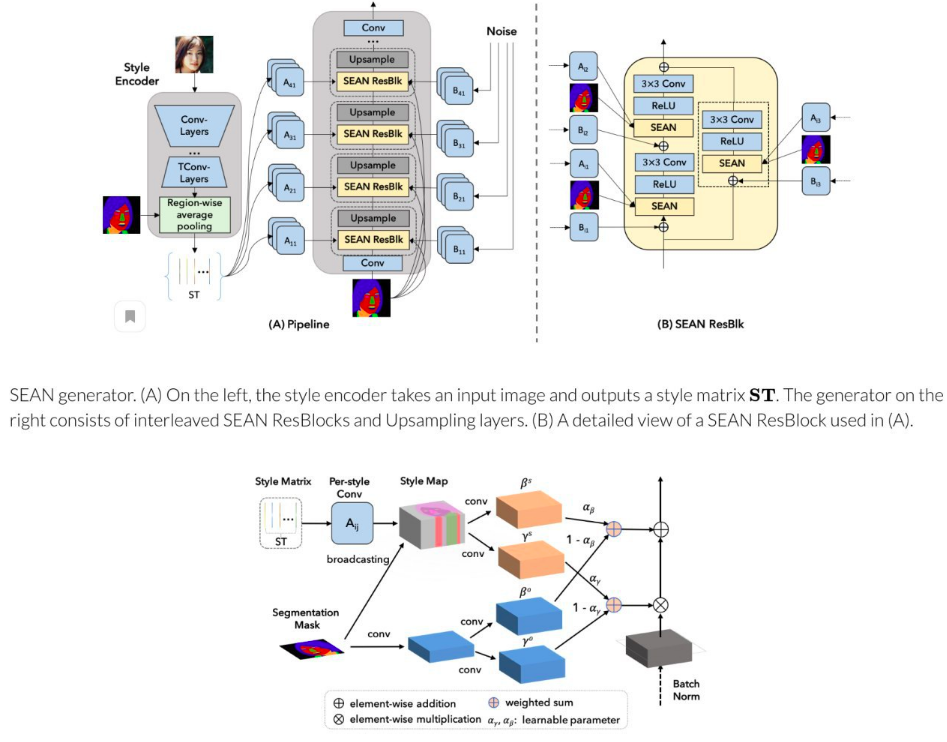
尽管 SPADE 可以通过分割蒙版生成一个不错的图片,但作者认为还不够好。因此,作者给 SPADE 加入了一个正则化块,这样除了分割图外,还加入了风格的信息。风格信息会用单独的编码器对图像的每个区域进行编码。通过这种方式,你可以改变面部不同部位的风格来生成混合的风格。
论文介绍的视频:https://youtu.be/0Vbj9xFgoUw
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Zhu_SEAN_Image_Synthesis_With_Semantic_Region-Adaptive_Normalization_CVPR_2020_paper.pdf
开源代码:https://github.com/ZPdesu/SEAN
3. SegAttnGAN: Text to Image Generation with Segmentation Attention

AttnGAN 的升级版本--这是一个实现通过文本生成一张图片的网络模型。在这个升级版本中,文本编码器将可以对句子和单独的词语提取特征,而之前它只是一个多尺度生成器。此外,分割蒙版将由相同的 embedding 通过自注意机制来生成,然后蒙版会通过 SPADE 块喂入生成器中。
论文下载地址:https://arxiv.org/abs/2005.12444
4. FaR-GAN for One-Shot Face Reenactment
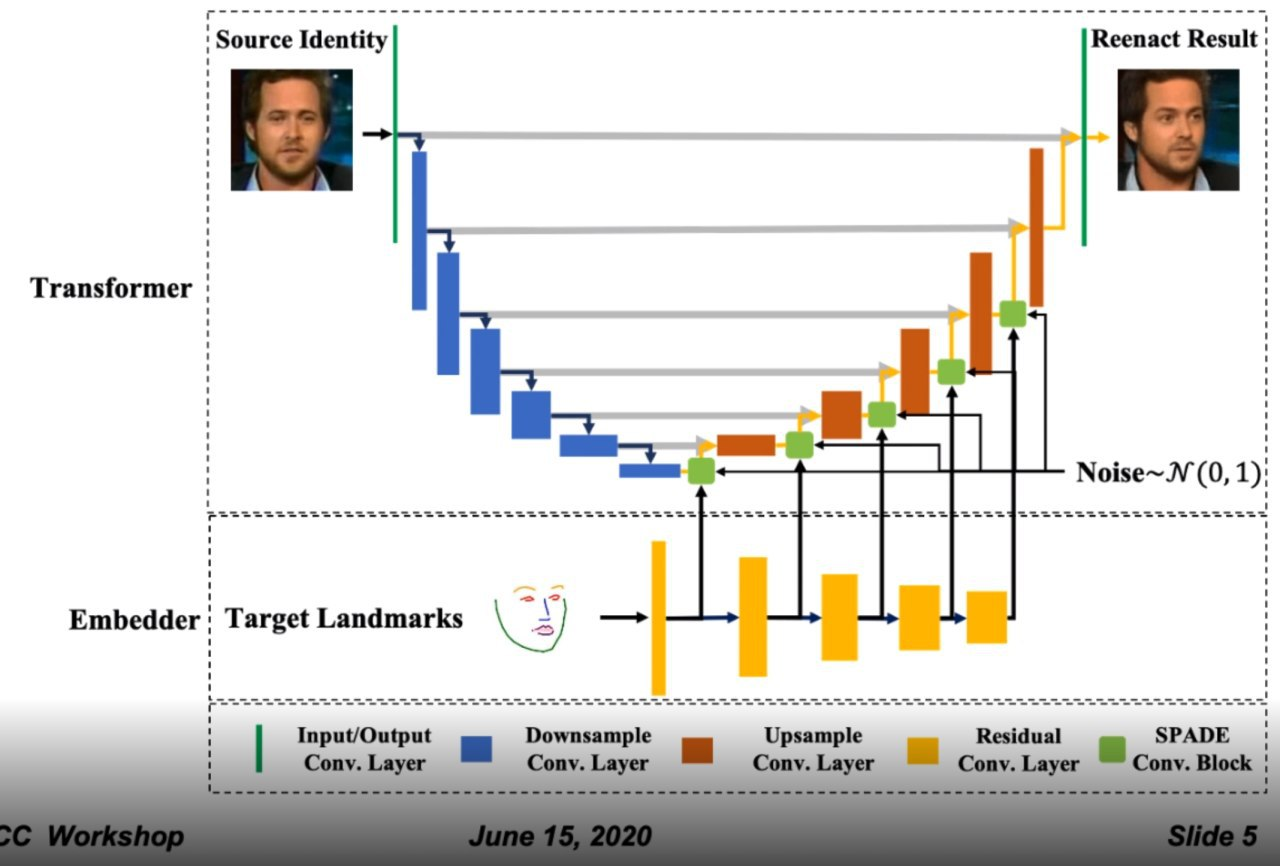
通过一张照片对人脸的编辑。SPADE 生成器开始于bottleneck 网络层,它来自一个输入是原始照片的编码器。而 SPADE 模块会采取一个新的人脸姿势的观点。另外,会加入噪音。
论文下载地址:https://arxiv.org/abs/2005.06402
5. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis

这篇论文是视图合成方向。该方法适合每个场景一个单独的模型(~30秒),它在场景中的坐标和方向产生一个视图,然后进入渲染。它会拍摄场景相关的照片。它是通过区分渲染训练的。这项工作允许你在场景中生成飞行视频,改变灯光。
论文介绍:https://www.matthewtancik.com/nerf
论文下地址:https://arxiv.org/abs/2003.08934
开源代码地址:https://github.com/bmild/nerf
6. Learning to Simulate Dynamic Environments with GameGAN

通过下一帧的预测来模拟简单的 2d 游戏。这是一个世界模型的再造(最早来自Schmidhuber)。有趣的技巧是你可以改变背景。
详细的论文介绍: https://youtu.be/4OzJUNsPx60
论文下载地址:https://arxiv.org/abs/2005.12126
7.Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
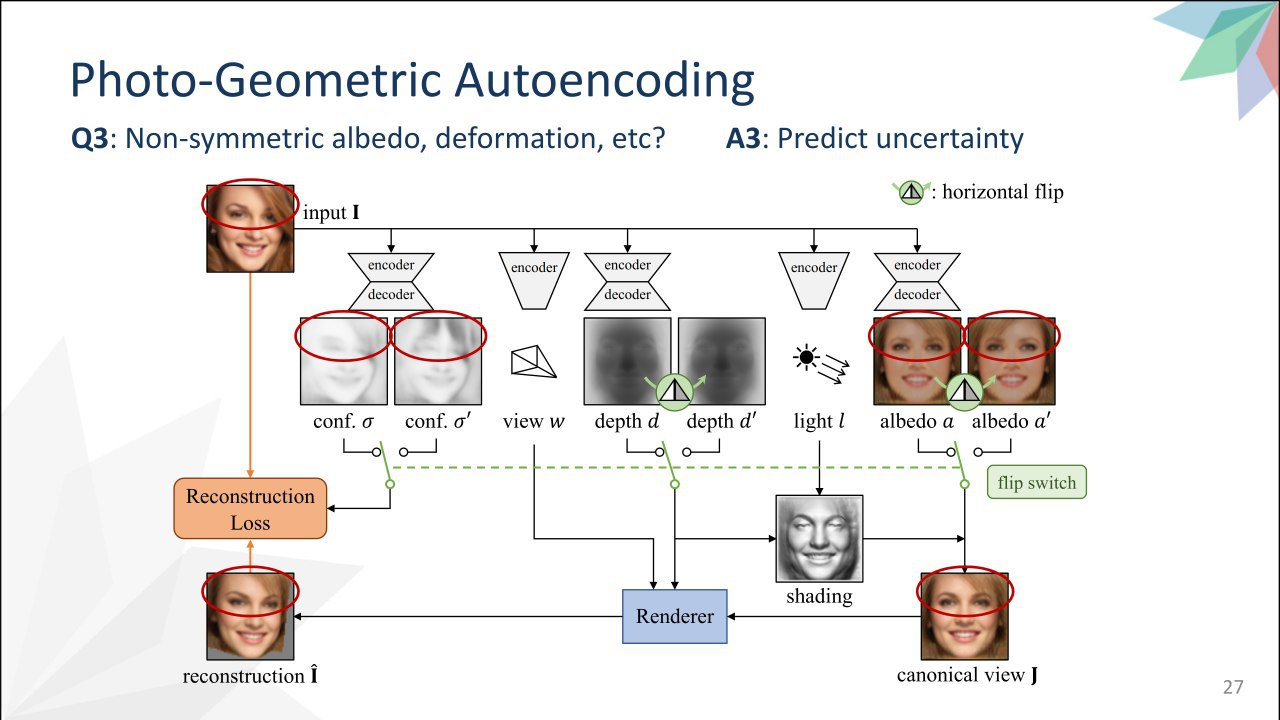
“最佳论文”的获得者。这篇论文的算法模型可以让你只需要采用一张照片即可得到一个 3d 模型,不需要其他额外的标签。但仅适用于对称的物体,比如人脸(或者说几乎就只能是人脸)。根据照片的不确定性的映射,深度,纹理,视点和光线进行预测。以差异化的呈现服务所有人(17年)。丢失-恢复原始照片。但它对于一些定义不明确的任务是不起作用的。这就是为什么他们使用对称-他们翻转纹理,值得信任的映射和阴影,从而可以在对称物体上发挥作用。
可以通过下面这个链接来体验这篇论文的工作:
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Wu_Unsupervised_Learning_of_Probably_Symmetric_Deformable_3D_Objects_From_Images_CVPR_2020_paper.pdf
开源代码地址:https://github.com/elliottwu/unsup3d
8. Advancing High Fidelity Identity Swapping for Forgery Detection
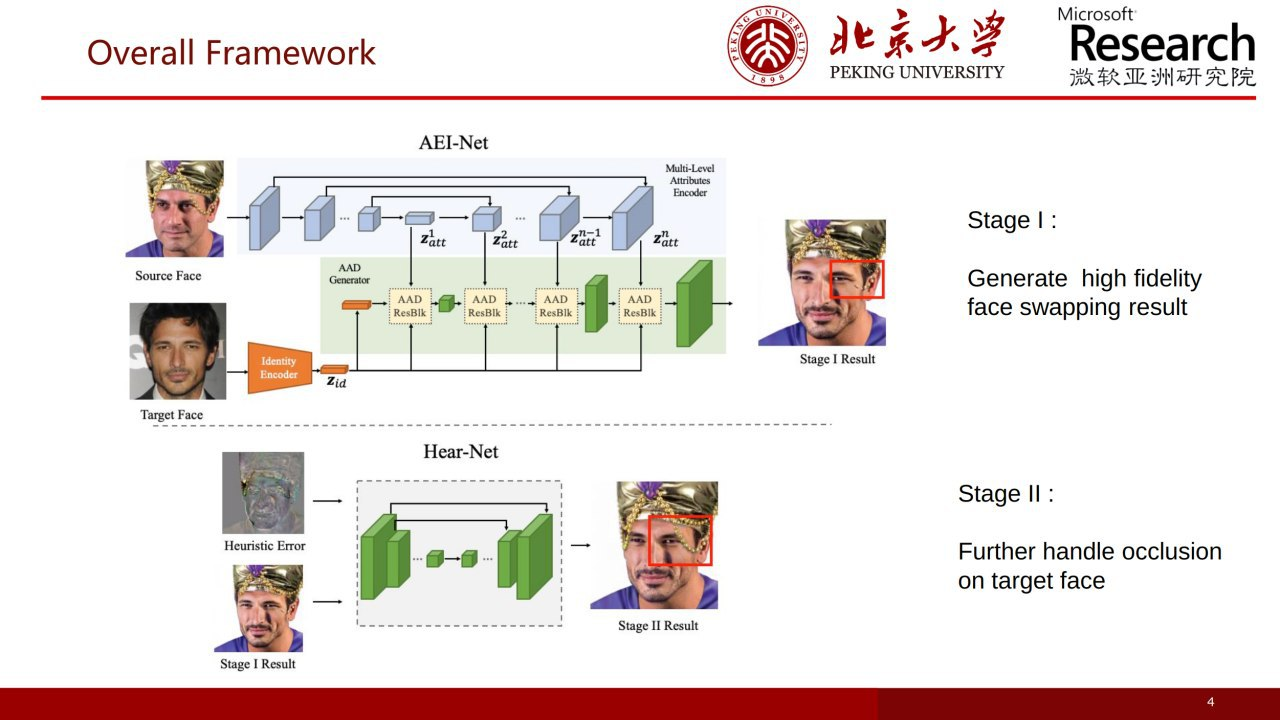
基于 one-shot的换脸方法,通过 SPADE 来得到源图的脸部几何,AdaIN 得到目标图片的脸部一致性,然后再通过第二个模型来优化结果,该模型的输入是第一步的合成结果以及源图和结果的差异,这可以有助于处理脸部缺失的部位或者物体。
论文介绍:https://youtu.be/qNvpNuqfNZs
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Li_Advancing_High_Fidelity_Identity_Swapping_for_Forgery_Detection_CVPR_2020_paper.pdf
9. Disentangled Image Generation Through Structured Noise Injection
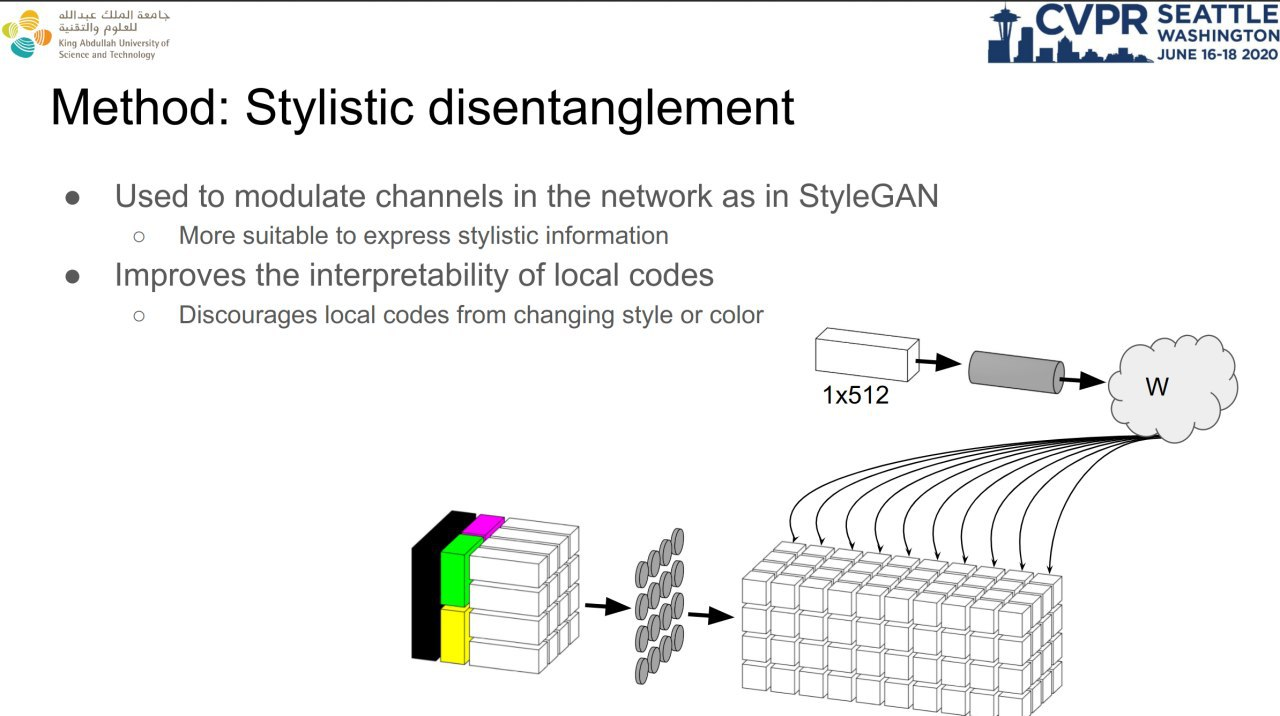
这篇论文作者喜欢 StyleGAN 可以生成不同的人脸,但对不能通过全局的隐式编码修改图片的局部部位感到不满意。因此,作者对原始的 StyleGAN 进行了修改。修改的内容包括:
提供的张量不再是常数4x4x512的输入张量,而是通过通道分为4个逻辑部分。 全局代码在空间部分为1 (1x1被扩展为4x4)。 共享2x2(扩展为4x4),本地4x4。 生成器中的AdaIN仍然存在,每个代码都是单独生成的。
通过这些修改可以实现在不影响全局的情况下,对人脸的局部位置进行修改。
论文的介绍:https://youtu.be/7h-7wso9E0k
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Alharbi_Disentangled_Image_Generation_Through_Structured_Noise_Injection_CVPR_2020_paper.pdf
开源代码:https://github.com/yalharbi/StructuredNoiseInjection
10.Cascade EF-GAN: Progressive Facial Expression Editing With Local Focuses

该论文提出一个可以改变人脸表情的网络。在 image2image 的基础上添加了2个修改。局部改变眼睛,鼻子,嘴巴,然后连接起来。渐进式编辑——将结果通过网络运行几次。
论文下载地址:https://arxiv.org/abs/2003.05905
11.PSGAN: Pose and Expression Robust Spatial-Aware GAN for Customizable Makeup Transfer
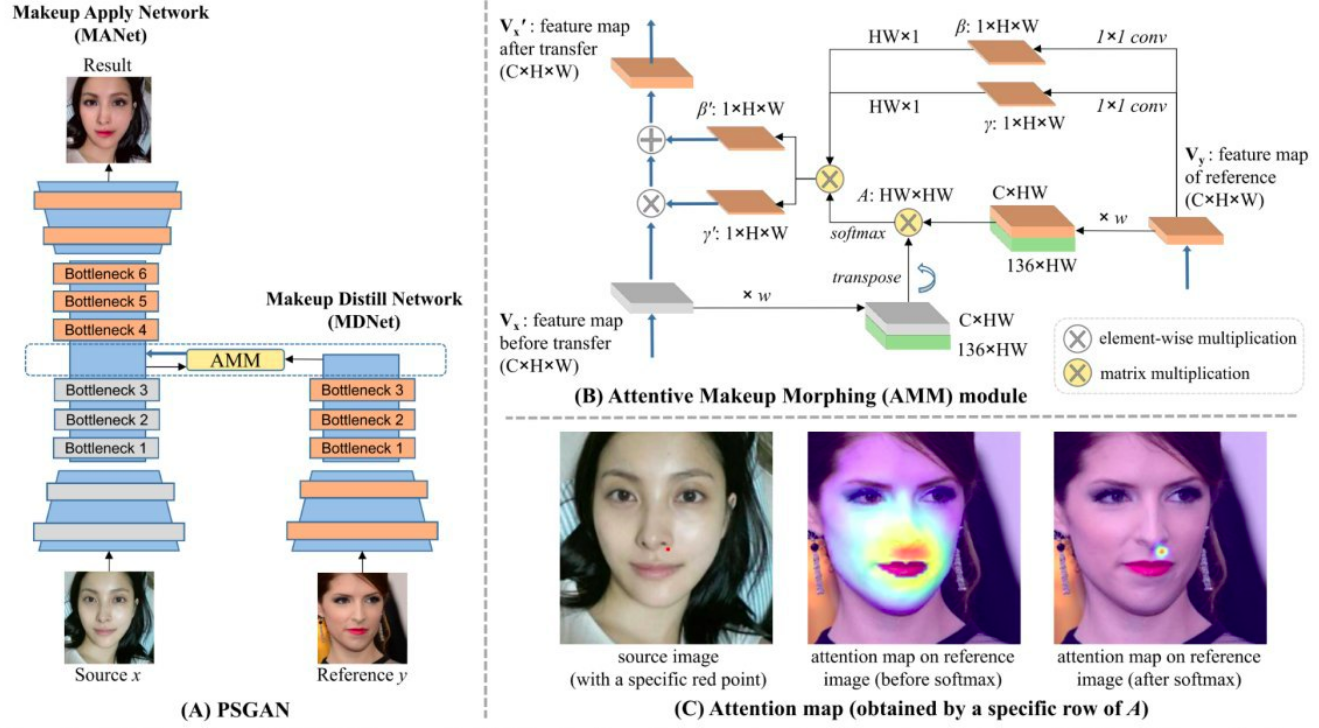
该论文是介绍一个实现化妆变换的方法,通过一个注意力机制解决了先前方法中的问题,即无法对姿势或者光照有很大的差别的情况进行转换化妆效果。采用的注意力是放在源图的瓶颈层和参考图片的瓶颈层之间。除了对抗损失外,还采用了不少的其他损失函数。
论文地址:https://arxiv.org/abs/1909.06956
开源代码地址:https://github.com/wtjiang98/PSGAN
12.MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation

该论文的方法可以实现生成部件的图片,将其分成背景,形状,纹理和姿势。另外对每个实体都有不同的编码器。
论文下载地址:https://arxiv.org/abs/1911.11758
开源代码:https://github.com/Yuheng-Li/MixNMatch
13.Learning to Shadow Hand-Drawn Sketches
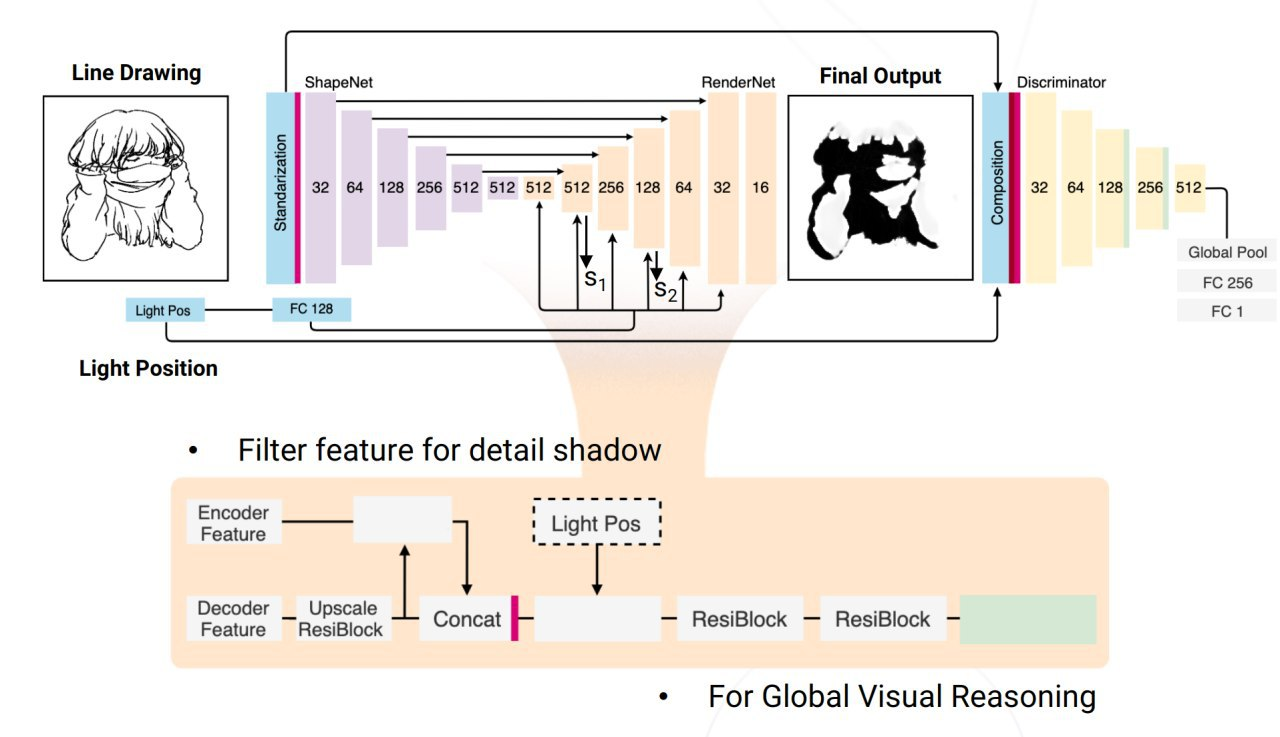
论文主要是实现给素描图添加阴影效果。作者收集了一个 1000 张素描图片以及对应阴影的小数据集,然后硬编码了光照的 26 个不同位置,并采用 image2image 来预测阴影的蒙版。
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Zheng_Learning_to_Shadow_Hand-Drawn_Sketches_CVPR_2020_paper.pdf
开源代码:https://github.com/qyzdao/ShadeSketch
14.Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation

这篇论文是对 image2image 在转换非成对数据的改进。改进点主要是通过复用判别器中的部分编码器。
论文下载地址:https://arxiv.org/abs/2003.00273
15. Unpaired Portrait Drawing Generation via Asymmetric Cycle Mapping
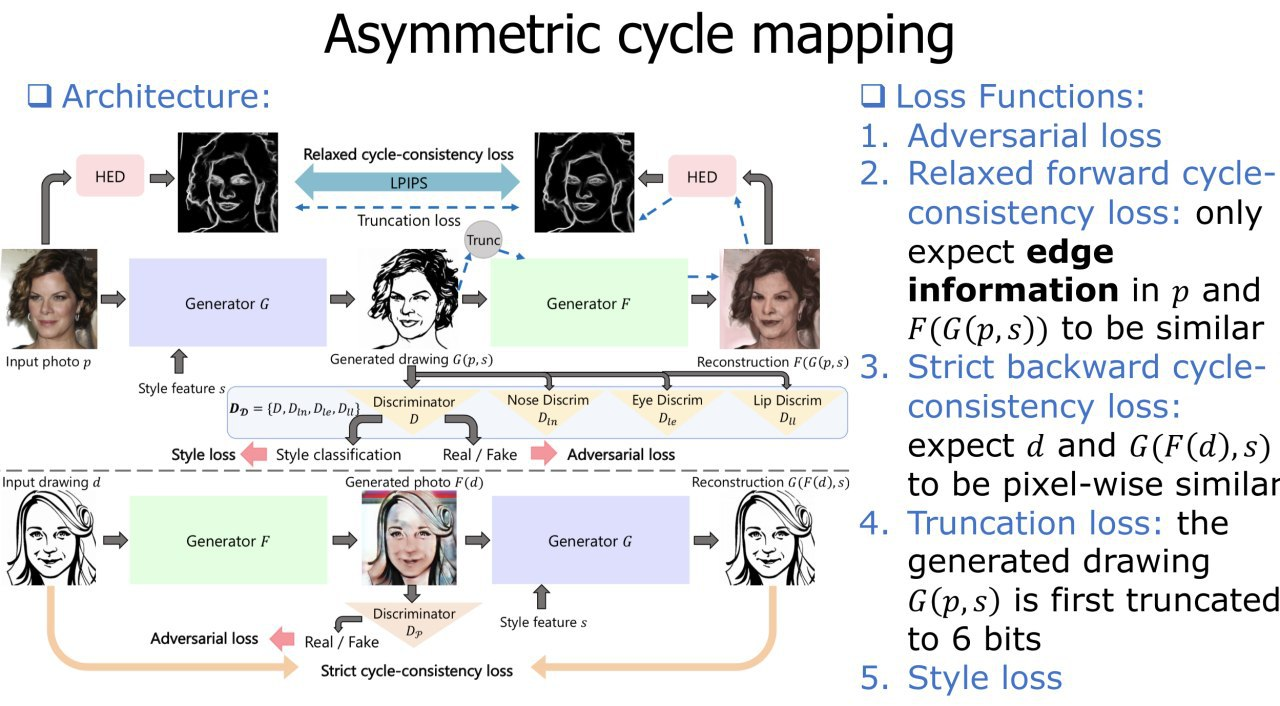
对绘制的脸进行非配对的image2image转换。修正以前方法的缺点。该方法主要的特点是,前向循环一致性不需要像后向那样严格,这允许在生成一个绘制的脸的时候,让生成器更加自由。
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Yi_Unpaired_Portrait_Drawing_Generation_via_Asymmetric_Cycle_Mapping_CVPR_2020_paper.pdf
开源代码:https://github.com/yiranran/Unpaired-Portrait-Drawing
16.SketchyCOCO: Image Generation From Freehand Scene Sketches

在之前的工作里有将分割、文本、边界框甚至单独的素描转换成照片的,但是并没有做将照片转换为手绘素描图,而本文的工作就是这个。该方法的实现分为两个步骤:
生成前景的物体,尽量做到精准; 生成背景部分的内容,这部分会比较自由,并不需要太严格的匹配输入的树或者云朵等。
作者自己构造了基于素描的照片数据集,其中动物是会替代为数据库中最相似的手绘动物,背景也是类似的做法。
实验结果非常的有趣,如上图 a 转到 e 图。
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Gao_SketchyCOCO_Image_Generation_From_Freehand_Scene_Sketches_CVPR_2020_paper.pdf
17.BachGAN: High-Resolution Image Synthesis From Salient Object Layout
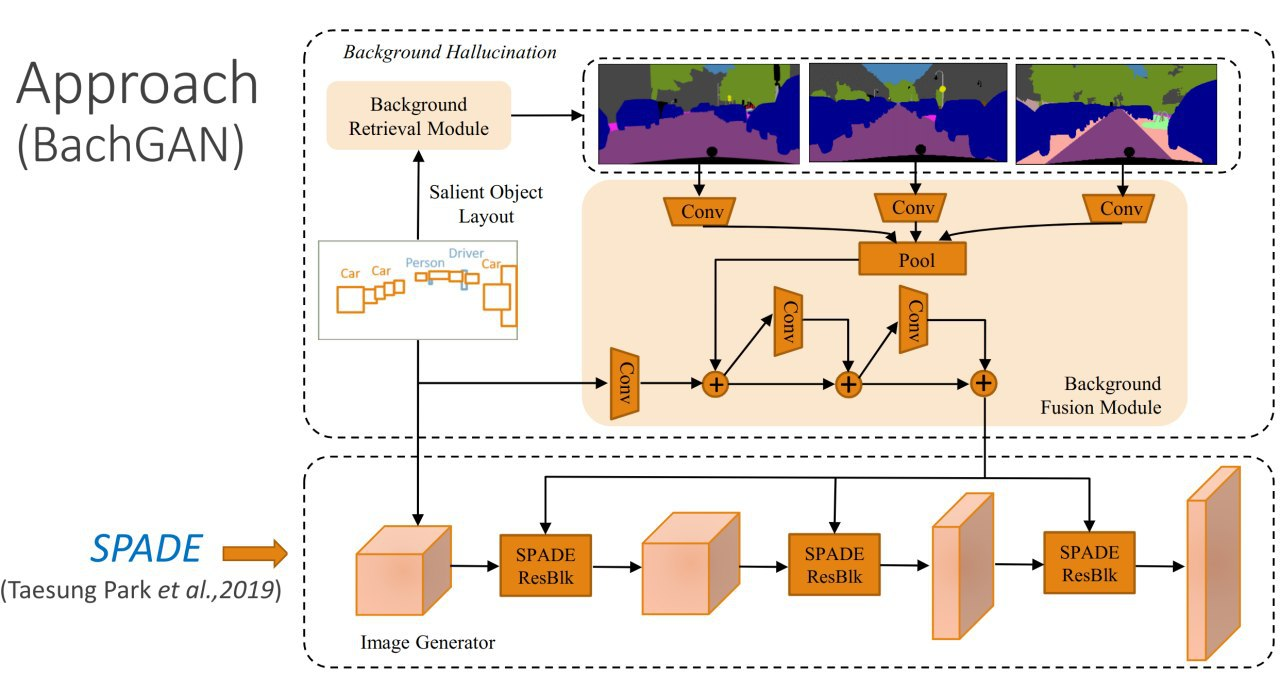
现在 image2image 已经可以很好地通过图像分割生成图片。但对于完整的语义图的效果还不够好,反倒是获得带有标签的捆绑盒要容易得多。但生产类似的标签结果是很困难的,所以本文作者在生成器部分加入这样的帮助,给生成器加入来自数据集中和完整分割标签相似的背景信息。
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Li_BachGAN_High-Resolution_Image_Synthesis_From_Salient_Object_Layout_CVPR_2020_paper.pdf
开源代码:https://github.com/Cold-Winter/BachGAN
18.Neural Rerendering in the Wild

这是对去年工作的一个改进。之前的工作可以实现在一组景点的照片上,通过经典的方法得到一个3d点云,然后训练image2image模型,通过地标在点云中的呈现来恢复地标的原始照片。你可以得到正常的结果,但问题是会带有模糊的游客人群,以及不同的环境条件(天气,一天的时间)。
而本文的解决方法就是对外观采用单独的编码器,这会对环境条件进行编码,并使用语义分割。根据推理结果,您可以确定一天的时间和天气,以及删除人员。
论文介绍:https://youtu.be/E1crWQn_kmY
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Meshry_Neural_Rerendering_in_the_Wild_CVPR_2019_paper.pdf
开源代码地址:https://github.com/google/neural_rerendering_in_the_wild
19. Attentive Normalization for Conditional Image Generation
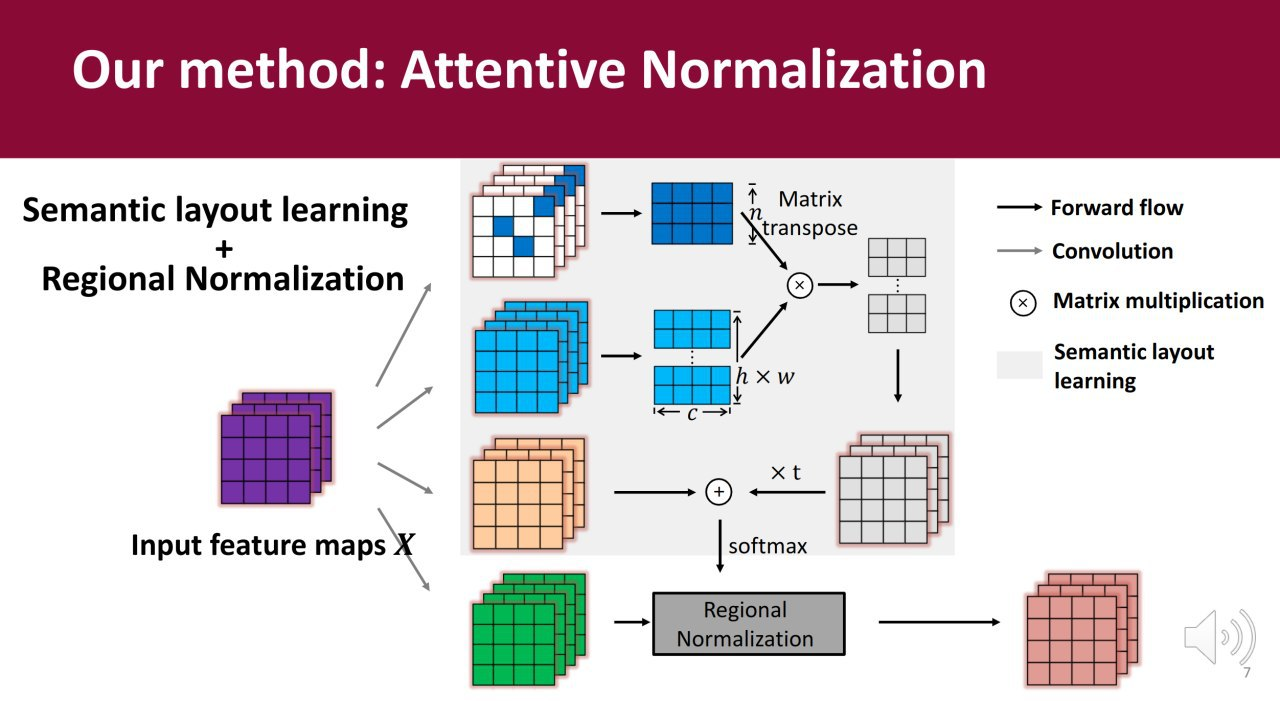
在 GANs 中加入注意力机制的效果非常好,正如最早加入注意力机制的SA -GAN(Self-Attention GAN)模型中展示的结果。但在空间尺度上,特征图的复杂度是二次复杂度,作者利用自己的拐杖使其复杂性变得线性化,他们还解释了应该在模型中中学习什么语义场景图。方法的效果和速度超过了baseline 方法。
论文下载地址:https://openaccess.thecvf.com/content_CVPR_2020/supplemental/Wang_Attentive_Normalization_for_CVPR_2020_supplemental.pdf
开源代码地址:https://github.com/shepnerd/AttenNorm
20.Freeze the Discriminator: a Simple Baseline for Fine-Tuning GANs
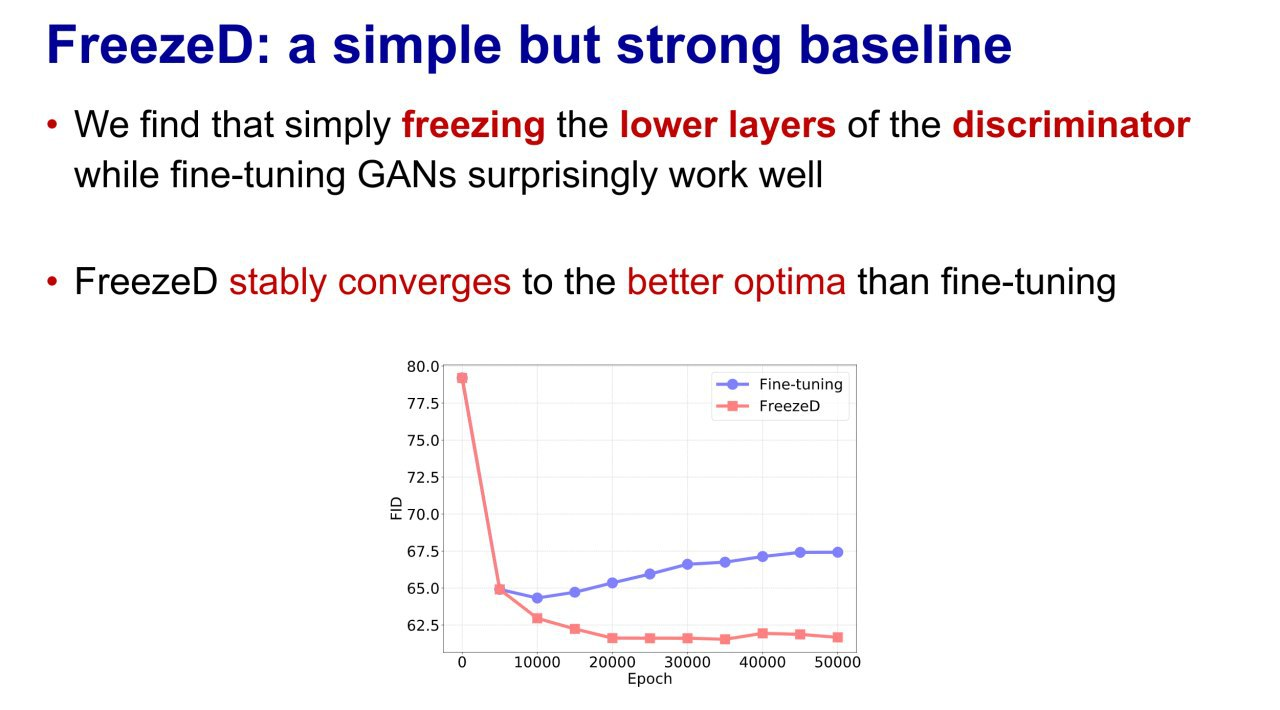
论文给出这样的观点:简单冻结判别器的前几层,反倒比对整个 GAN 进行 finetuning 的效果要更好,而且更容易收敛。
论文下载地址:https://arxiv.org/abs/2002.10964
开源代码地址:https://github.com/sangwoomo/FreezeD
小结
文章里总共盘点了 20 篇图像合成的论文,并给出简单的方法介绍,然后部分论文还带有视频介绍。
简单盘点 CVPR2020 的图像合成论文的更多相关文章
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- CVPR2020无人驾驶论文摘要
CVPR2020无人驾驶论文摘要 无人 导读/ Starsky是一种比较独特的方案.它是在高速上自动驾驶,第一公里最后一公里采用远程驾驶的模式,Starsky的卡车可以由人类远程操作.没有使用较为昂贵 ...
- 代码之间-论文修改助手v1.0版本发布
论文查重,是每个毕业生都要面临的一个令人头疼的问题,如果写论文不认真,很可能导致查重红一大片. 之前有帮助一些朋友修改论文降低重复率,做了一些工作后发现,国内的查重机构,如知网.维普等,大多数是基于关 ...
- 2-sat问题,输出方案,几种方法(赵爽的论文染色解法+其完全改进版)浅析 / POJ3683
本文原创于 2014-02-12 09:26. 今复习之用,有新体会,故重新编辑. 2014-02-12 09:26: 2-sat之第二斩!昨天看了半天论文(赵爽的和俉昱的),终于看明白了!好激动有 ...
- C# vb .net图像合成-合成自定义路径
在.net中,如何简单快捷地实现图像合成呢,比如合成文字,合成艺术字,多张图片叠加合成等等?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码 ...
- C# vb .net图像合成-合成椭圆
在.net中,如何简单快捷地实现图像合成呢,比如合成文字,合成艺术字,多张图片叠加合成等等?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码 ...
- C# vb .net图像合成-合成矩形
在.net中,如何简单快捷地实现图像合成呢,比如合成文字,合成艺术字,多张图片叠加合成等等?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码 ...
- C# vb .net图像合成-合成富文本
在.net中,如何简单快捷地实现图像合成呢,比如合成文字,合成艺术字,多张图片叠加合成等等?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码 ...
- C# vb .net图像合成-合成星形
在.net中,如何简单快捷地实现图像合成呢,比如合成文字,合成艺术字,多张图片叠加合成等等?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码 ...
随机推荐
- Python练习题 040:Project Euler 012:有超过500个因子的三角形数
本题来自 Project Euler 第12题:https://projecteuler.net/problem=12 # Project Euler: Problem 12: Highly divi ...
- 033 01 Android 零基础入门 01 Java基础语法 03 Java运算符 13 运算符和表达式知识点总结
033 01 Android 零基础入门 01 Java基础语法 03 Java运算符 13 运算符和表达式知识点总结 本文知识点:运算符和表达式知识点总结 前面学习的几篇文都是运算符和表达式相关的知 ...
- 【题解】CF1228D Complete Tripartite
Link 题目大意:给定一个无向图,将它划分为三个点集,要求在一个点集中的点没有边相连,且颜色相同,不同集合中的点互相有边相连. \(\text{Solution:}\) 我们发现,与一个点之间没有边 ...
- Nuxt/Vue自定义导航栏Topbar+标签栏Tabbar组件
基于Vue.js实现自定义Topbar+Tabbar组件|仿咸鱼底部凸起导航 最近一直在倒腾Nuxt项目,由于Nuxt.js是基于Vue.js的服务端渲染框架,只要是会vue,基本能很快上手了. 一般 ...
- fastjson配置序列化过滤转换
@Configuration@EnableWebMvcpublic class WebConfig implements WebMvcConfigurer { @Override public voi ...
- Azure Media Player Logo隐藏和 视频字幕样式
<style type="text/css"> /**hide mediaplayer logo*/ .amp-default-skin .amp-content-ti ...
- markdown的基本使用
1.什么是markdown? markdown是一种轻量级的标记语言 可以转换为html/xhtml和其它格式 可读.直观.学习成本低 当你学会使用markdown编写文档时,你会感觉自己发现了一个新 ...
- 多测师讲解自动化 _邮件发送_高级讲师肖sir
第一步.进入如下网址申请163邮箱. https://mail.163.com/ 第二步.注册完之后登录.点击如下图设置点击POP3/SMTP/IMAP. 第三步.右侧点击客户端授权密码. 第四步. ...
- 多测师肖sir_pdf转word方法
1.百度搜索 my love pdf 在线转换 2.输入wps 下载软件
- MeteoInfoLab脚本示例:地图投影
在用axesm函数创建地图坐标系的时候可以指定地图投影(设置projinfo参数),地图投影可以通过projinfo函数来创建,里面的参数依据proj4投影字符串,可以参考此网页:http://rem ...