Centos7.5搭建Hadoop2.8.5完全分布式集群部署
一、基础环境设置
1. 准备4台客户机(VMware虚拟机)
系统版本:Centos7.5
节点配置:
192.168.208.128 ——Master
192.168.208.129 ——Slaver-1
192.168.208.130 ——Slaver-2
192.168.208.130 ——Slaver-3
2. 配置hosts文件,使4台客户机能够以主机名相互访问
[root@Master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.208.128 Master
192.168.208.129 Slaver-1
192.168.208.130 Slaver-2
192.168.208.131 Slaver-3
# 将hosts文件传送给其它3台客户机
[root@Master ~]# scp -r /etc/hosts root@Slaver-1:/etc
[root@Master ~]# scp -r /etc/hosts root@Slaver-2:/etc
[root@Master ~]# scp -r /etc/hosts root@Slaver-3:/etc
3. 为4台客户机配置jdk环境
我们选择配置jdk1.8.0_181,点击此处下载。
[root@Master ~]# wget http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz
# 解压
[root@Master ~]# tar -xzvf jdk-8u181-linux-x64.tar.gz
[root@Master ~]# mkdir /usr/local/java # 创建jdk存放目录
[root@Master ~]# mv jdk1.8.0_181/ /usr/local/java # 将解压缩文件转移至存放目录
# 配置jdk环境
[root@Master ~]# vi /etc/profile
# 在文件末尾添加如下内容
# java
export JAVA_HOME=/usr/local/java/jdk1.8.0_181 # 注意,要与刚刚所创建的目录匹配
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 使jdk配置文件生效
[root@Master ~]# source /etc/profile
# 测试jdk环境配置是否成功,如输出如下内容,则表示成功
[root@Master ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
4. 关闭防火墙,SELinux
a. iptables
# 临时关闭
[root@Master ~]# service iptables stop
# 禁止开机启动
[root@Master ~]# chkconfig iptables off
b.firewalld
CentOS7版本后防火墙默认使用firewalld,默认是没有iptables的,所以关闭防火墙的命令如下:
# 临时关闭
[root@Master ~]# systemctl stop firewalld
# 禁止开机启动,输出如下,则表示禁止成功
[root@Master ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
c.关闭SELinux
# 永久关闭SELinux
[root@Master ~]# vi /etc/selinux/config
#disabled - No SELinux policy is loaded.
SELINUX=disabled # 此处将SELINUX=enforcing改为SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# 修改SELinux配置后,需重启客户机才能生效
[root@Master ~]# reboot
# 重启之后,查看SELinux状态
[root@Master ~]# /usr/sbin/sestatus
SELinux status: disabled # 如果输出如是,则表示SELinux永久关闭成功
5. 设置SSH免密钥
关于ssh免密码的设置,要求每两台主机之间设置免密码,自己的主机与自己的主机之间也要求设置免密码。在这里,为了避免后面的各种权限问题,我们直接使用root账户来设置面密钥登陆。
[root@Master ~]$ ssh-keygen -t rsa
[root@Master ~]$ ssh-copy-id node-1
[root@Master ~]$ ssh-copy-id node-2
[root@Master ~]$ ssh-copy-id node-3
注:每一台客户机都要做如上设置,所以,最好的方式是:按上述方法配置好一台虚拟机之后,再克隆出其它几台。
二、安装hadoop集群
1. 下载hadoop2.8.5二进制文件
2. hadoop安装目录
为了统一管理,我们将hadoop的安装路径定为/usr/opt/hadoop下,创建目录后,我们将hadoop二进制文件解压至这个目录下。
3. 配置core-site.xml
hadoop的配置文件,在/opt/hadoop/hadoop-2.8.5/etc/hadoop下,
[root@Master ~]# cd /opt/hadoop/hadoop-2.8.5/etc/hadoop
[root@Master hadoop]# vi core-site.xml
<configuration>
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 配置操作hdfs的存冲大小 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 配置临时数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/tmp</value>
</property>
</configuration>
4. 配置hdfs-site.xml
[root@Master hadoop]# vim hdfs-site.xml
<configuration>
<!--配置副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--hdfs的元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/hdfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-2.8.5/hdfs/data</value>
</property>
<!--hdfs的namenode的web ui 地址-->
<property>
<name>dfs.http.address</name>
<value>Master:50070</value>
</property>
<!--hdfs的snn的web ui 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>Master:50090</value>
</property>
<!--是否开启web操作hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否启用hdfs权限(acl)-->
<property>
<name>dfs.permissions</name>
<value>false</value> </property>
</configuration>
5. 配置mapred-site.xml
[root@Master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@Master hadoop]# vim mapred-site.xml
<configuration>
<!--指定maoreduce运行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--历史服务的通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<!--历史服务的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
6. 配置yarn-site.xml
[root@Master hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!--指定resourcemanager所启动的服务器主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<!--指定scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<!--指定resource-tracker的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<!--指定resourcemanager.admin的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<!--指定resourcemanager.webapp的ui监控地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>
7. 配置slaves文件
[root@Master hadoop]# vim slaves
Slaver-1
Slaver-2
Slaver-3
8. 配置hadoop-env.sh,指定JAVA_HOME
[root@Master hadoop]# vim hadoop-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_181
9. 配置yarn-env.sh,指定JAVA_HOME
[root@Master hadoop]# vim yarn-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_181
10. 配置mapred-env.sh,指定JAVA_HOME
[root@Master hadoop]# vim mapred-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_181
11. 将hadoop文件分发到其它几台客户机上
[root@Master hadoop]# scp -r hadoop/ Slaver-1:`pwd`
[root@Master hadoop]# scp -r hadoop/ Slaver-2:`pwd`
[root@Master hadoop]# scp -r hadoop/ Slaver-3:`pwd`
三、启动并验证hadoop集群
1. 启动集群
第一次启动集群,需要格式化namenode,操作如下:
[root@Master ~]# hdfs namenode -format
输出如下内容,则表示格式化成功

**启动HDFS**
格式化成功之后,我们就可以启动HDFS了,命令如下:
[root@Master hadoop]# start-dfs.sh
Starting namenodes on [Master]
Master: starting namenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-namenode-Master.out
Slaver-3: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-3.out
Slaver-2: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-2.out
Slaver-1: starting datanode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-datanode-Slaver-1.out
Starting secondary namenodes [Master]
Master: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.8.5/logs/hadoop-root-secondarynamenode-Master.out
启动Yarn
启动Yarn时需要注意,我们不能在NameNode上启动Yarn,而应该在ResouceManager所在的主机上启动。但我们这里是将NameNode和ResouceManager部署在了同一台主机上,所以,我们直接在Master这台机器上启动Yarn。
[root@Master hadoop]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-resourcemanager-Master.out
Slaver-2: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-2.out
Slaver-1: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-1.out
Slaver-3: starting nodemanager, logging to /opt/hadoop/hadoop-2.8.5/logs/yarn-root-nodemanager-Slaver-3.out
2. web验证
至此,我们的集群就已完全启动起来了,我们可以通过访问web页面,来做最后一步验证。我们已将web页面配置在Master主机上,因此,我们访问http://192.168.208.128:50070/,页面显示如下:
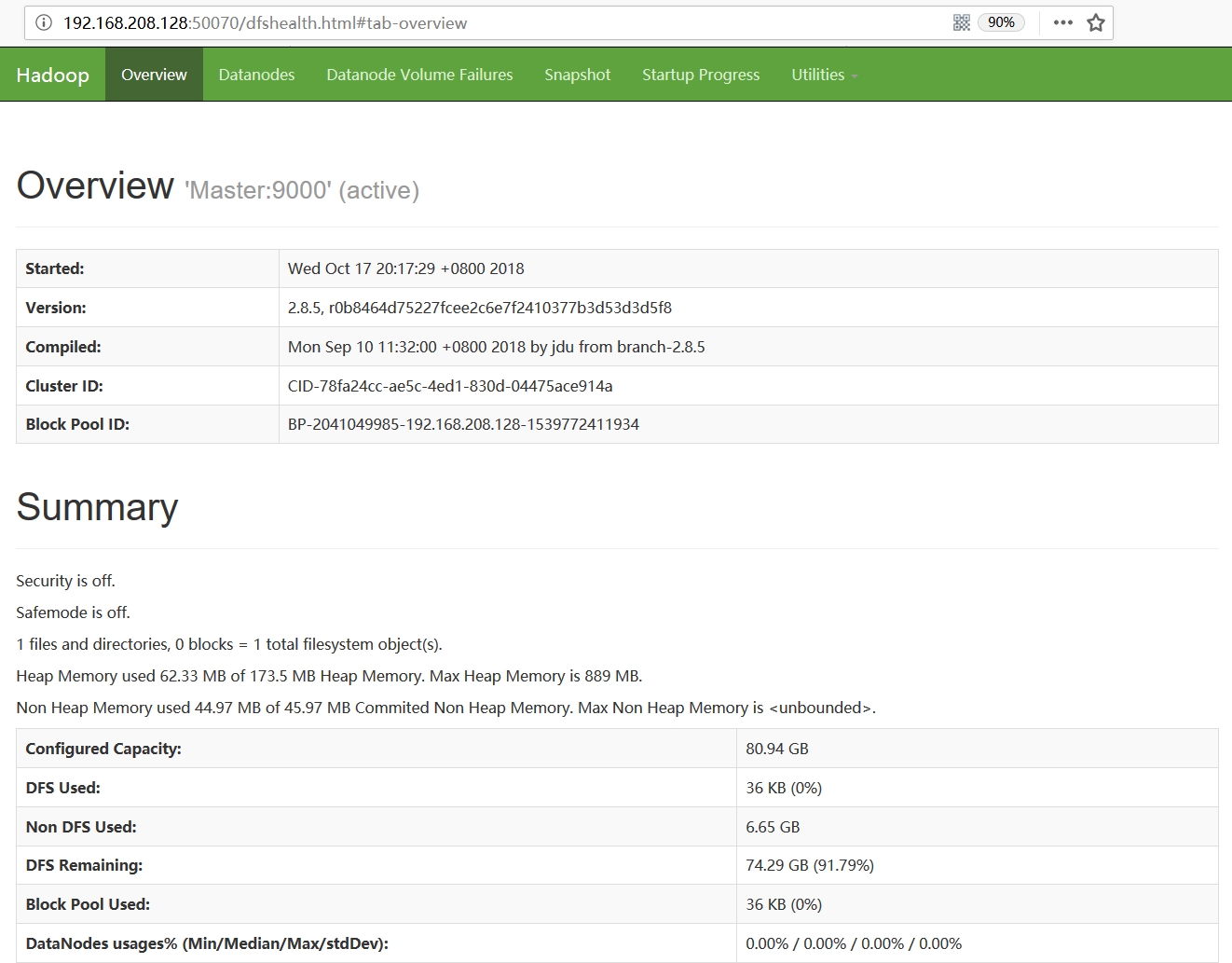
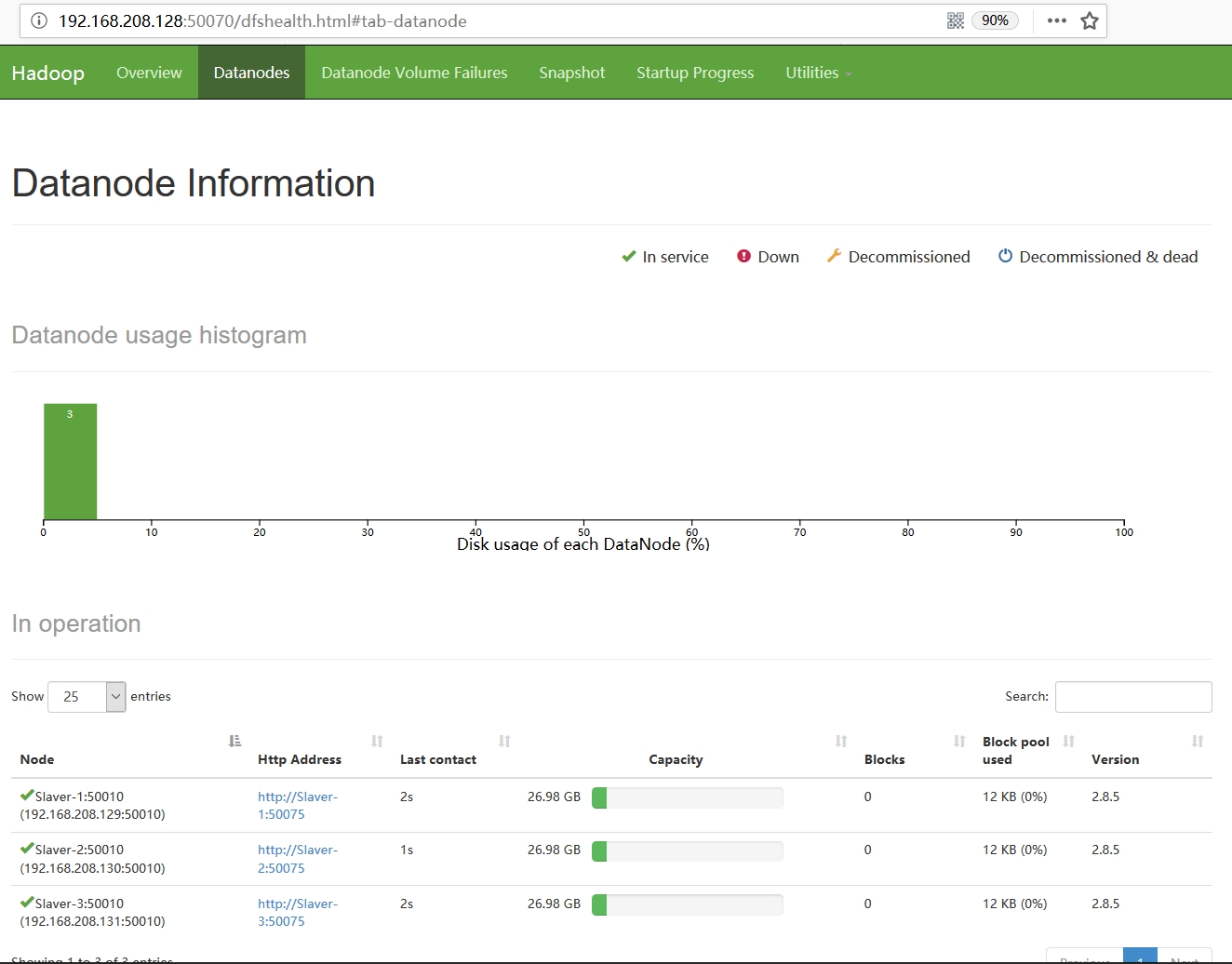
Centos7.5搭建Hadoop2.8.5完全分布式集群部署的更多相关文章
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 ...
- CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群搭建 Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.2 关闭防火墙,设置静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- 搭建Hadoop2.7.1的分布式集群
Hadoop 2.7.1 (2015-7-6更新),hadoop的环境配置不是特别的复杂,但是确实有很多细节需要注意,不然会造成许多配置错误的情况.尽量保证一次配置正确防止反复修改. 网上教程有很多关 ...
- # 从零開始搭建Hadoop2.7.1的分布式集群
Hadoop 2.7.1 (2015-7-6更新),Hadoop的环境配置不是特别的复杂,可是确实有非常多细节须要注意.不然会造成很多配置错误的情况.尽量保证一次配置正确防止重复改动. 网上教程有非常 ...
- Docker中搭建Hadoop-2.6单机伪分布式集群
1 获取一个简单的Docker系统镜像,并建立一个容器. 1.1 这里我选择下载CentOS镜像 docker pull centos 1.2 通过docker tag命令将下载的CentOS镜像名称 ...
- 基于hadoop2.6.0搭建5个节点的分布式集群
1.前言 我们使用hadoop2.6.0版本配置Hadoop集群,同时配置NameNode+HA.ResourceManager+HA,并使用zookeeper来管理Hadoop集群 2.规划 1.主 ...
- 搭建hbase1.2.5完全分布式集群
简介 有一段时间,没写博客了,因为公司开发分布式调用链追踪系统,用到hbase,在这里记录一下搭建过程 1.集群如下: ip 主机名 角色 192.168.6.130 node1.jacky.com ...
- 摘要: CentOS 6.5搭建Redis3.2.8伪分布式集群
from https://my.oschina.net/ososchina/blog/856678 摘要: CentOS 6.5搭建Redis3.2.8伪分布式集群 前言 最近在服务器上搭建了 ...
随机推荐
- 初识Spark程序
执行第一个spark程序 普通模式提交任务: bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark ...
- 一些很酷的.Net技巧 .
一..Net Framework 1. 如何获得系统文件夹 使用System.Envioment类的GetFolderPath方法:例如: Environment.GetFolderPath( En ...
- SCOM发送邮件通知
运行方式配置:1. 新建账户--Windows域账户,安全级别较高,将其分发到SCOM管理服务器2. 配置文件--通知账户--将上一步新建的账户添加到该配置文件中的 运行方式账户,管理 所有目标对象 ...
- 自动化测试全套流程(一)-搭建Jenkins环境
前提 既然要做自动化测试,那我们就做得彻底一些,将整套系统部署在Linux服务器上,在搭建Jenkins环境之前,我已经通过VirtualBox安装了一个CentOS的服务器,搭建Jenkins是基于 ...
- HTTP协议图--HTTP 报文实体
1. HTTP 报文实体概述 HTTP 报文结构 大家请仔细看看上面示例中,各个组成部分对应的内容. 接着,我们来看看报文和实体的概念.如果把 HTTP 报文想象成因特网货运系统中的箱子,那么 H ...
- codeforces 809C Find a car
codeforces 809C Find a car 题意 有个\(1e9*1e9\)的矩阵,行 \(x\) 从上到下递增,列 \(y\) 从左到右递增.每个格子有一个正值.\((x, y)\) 的值 ...
- codeforces 808G Anthem of Berland
codeforces 808G Anthem of Berland 题面 给定\(s\)串和\(t\)串,字符集是小写字母.\(s\)串中有些位置的值不确定,要求你确定这些位置上的值,使得\(t\)在 ...
- 001Java输入、eclipse快捷键
内容:Java实现键盘输入,eclipse常用快捷键 ######################################################################### ...
- BZOJ 1303 中位数图 模拟
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=1303 题目大意: 给出1~n的一个排列,统计该排列有多少个长度为奇数的连续子序列的中位 ...
- LANMP常用配置.md
httpd 配置 MPM prefork StartServers # 服务器启动时建立的子进程数量. MinSpareServers # 空闲子进程的最小数量:如果当前空闲子进程数少于MinSpar ...