多GPU计算
多GPU计算已经可以说,只要是个成熟的模型,都使用了这一点。
例如:
gluoncv:https://github.com/dmlc/gluon-cv/blob/master/scripts/detection/faster_rcnn/train_faster_rcnn.py#L218
多GPU计算最常用的方法是:数据并行
流程如下图:
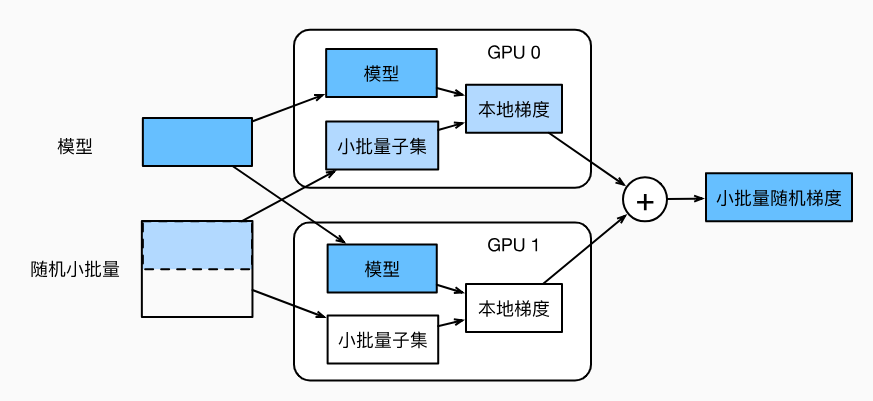
- 模型参数复制多份
- 批量数据,分成多份子集,在各自显卡的显存上计算梯度
- 再累加到一块显卡的显存上
- 最后广播到各个显存上
import mxnet as mx
from mxnet import autograd, nd
from mxnet.gluon import nn,loss as gloss
import d2lzh as d2l scale = 0.01
W1 = nd.random.normal(scale=scale,shape=(20,1,3,3))
b1 = nd.zeros(shape=20)
W2 = nd.random.normal(scale=scale,shape=(50,20,5,5))
b2 = nd.zeros(shape=50)
W3 = nd.random.normal(scale=scale,shape=(800,128))
b3 = nd.zeros(shape=128)
W4 = nd.random.normal(scale=scale,shape=(128,10))
b4 = nd.zeros(shape=10)
params = [W1, b1, W2, b2, W3, b3, W4, b4] def lenet(X, params):
h1_conv = nd.Convolution(data=X, weight=params[0],bias=params[1],
kernel=(3,3),num_filter=20)
h1_activation = nd.relu(h1_conv)
h1 = nd.Pooling(data=h1_activation, pool_type='avg', kernel=(2,2),
stride=(2,2)) h2_conv = nd.Convolution(data=h1, weight=params[2],bias=params[3],
kernel=(5,5), num_filter=50)
h2_activation = nd.relu(h2_conv)
h2 = nd.Pooling(data=h2_activation, pool_type='avg', kernel=(2,2),
stride=(2,2))
h2 = nd.flatten(h2)
h3_linear = nd.dot(h2, params[4]) + params[5]
h3 = nd.relu(h3_linear)
y_hat = nd.dot(h3, params[6]) + params[7]
return y_hat loss = gloss.SoftmaxCrossEntropyLoss() # 多GPU之间的同步
# 尝试把模型参数复制到gpu(0)上
def get_params(params, ctx):
new_params = [p.copyto(ctx) for p in params]
for p in new_params:
p.attach_grad()
return new_params new_params = get_params(params,mx.gpu(0)) # 给定分布在多块显卡的显存之间的数据
# 把各块显卡的显存数据加起来,再广播到所有显存上
def allreduce(data):
for i in range(1,len(data)):
data[0][:] += data[i].copyto(data[0].context)
for i in range(1,len(data)):
data[0].copyto(data[i]) # data = [nd.ones((1,2), ctx=mx.gpu(i)) * (i+1) for i in range(2)]
# print(data) # 将批量数据切分并复制到各个显卡的显存上去
def split_and_load(data, ctx):
n, k = data.shape[0], len(ctx)
m = n // k
return [data[i*m:(i+1)*m].as_in_context(ctx[i]) for i in range(k)] batch = nd.arange(24).reshape((6,4))
ctx = [mx.gpu(0),mx.gpu(1)]
splitted = split_and_load(batch,ctx) # 单个小批量上的多GPU训练
def train_batch(X, y, gpu_params, ctx, lr):
gpu_Xs, gpu_ys = split_and_load(X, ctx), split_and_load(y, ctx)
with autograd.record():
ls = [loss(lenet(gpu_X, gpu_W), gpu_y)
for gpu_X, gpu_y, gpu_W in zip(gpu_Xs, gpu_ys,
gpu_params)]
# 各块GPU上分别反向传播
for l in ls:
l.backward() # 把各块显卡的显存上的梯度加起来,然后广播到所有显存上
for i in range(len(gpu_params[0])):
allreduce([gpu_params[c][i].grad for c in range(len(ctx))]) # 在各块显卡的显存上分别更新模型参数
for param in gpu_params:
d2l.sgd(param, lr, X.shape[0]) import time
# 定义训练模型
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
ctx = [mx.gpu(i) for i in range(num_gpus)]
print('running on:', ctx)
# 将模型参数复制到各块显卡的显存上
gpu_params = [get_params(params, c) for c in ctx]
for epoch in range(4):
start = time.time()
for X,y in train_iter:
# 对单个小批量进行多GPU训练
train_batch(X,y, gpu_params, ctx, lr)
nd.waitall() train_time = time.time() - start
def net(x):
return lenet(x, gpu_params[0]) test_acc = d2l.evaluate_accuracy(test_iter, net, ctx[0])
print('epoch %d, time %.1f sec, test acc %.2f'%(epoch+1, train_time, test_acc)) train(num_gpus=2, batch_size=256, lr=0.2)
多GPU计算的更多相关文章
- GPU计算的十大质疑—GPU计算再思考
http://blog.csdn.NET/babyfacer/article/details/6902985 原文链接:http://www.hpcwire.com/hpcwire/2011-06-0 ...
- OpenGL实现通用GPU计算概述
可能比較早一点做GPU计算的开发者会对OpenGL做通用GPU计算,随着GPU计算技术的兴起,越来越多的技术出现,比方OpenCL.CUDA.OpenAcc等,这些都是专门用来做并行计算的标准或者说接 ...
- (Matlab)GPU计算简介,及其与CPU计算性能的比较
1.GPU与CPU结构上的对比 2.GPU能加速我的应用程序吗? 3.GPU与CPU在计算效率上的对比 4.利用Matlab进行GPU计算的一般流程 5.GPU计算的硬件.软件配置 5.1 硬件及驱动 ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- Julia:高性能 GPU 计算的编程语言
Julia:高性能 GPU 计算的编程语言 0条评论 2017-10-31 18:02 it168网站 原创 作者: 编译|田晓旭 编辑: 田晓旭 [IT168 评论]Julia是一种用于数学计 ...
- GPU计算的后CUDA时代-OpenACC(转)
在西雅图超级计算大会(SC11)上发布了新的基于指令的加速器并行编程标准,既OpenACC.这个开发标准的目的是让更多的编程人员可以用到GPU计算,同时计算结果可以跨加速器使用,甚至能用在多核CPU上 ...
- 从 SPIR-V 到 ISPC:将 GPU 计算转化为 CPU 计算
游戏行业越来越多地趋向于将计算工作转移到图形处理单元 (GPU) 中,导致引擎和/或工作室需要开发大量 GPU 计算着色器来处理不同的计算任务.但有时候在 CPU 上运行这些计算着色器非常方便,不必重 ...
- (一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要: 1.以动态图形式计算一个简单的加法 2.cpu和gpu计算力比较(包括如何指定cpu和gpu) 3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.c ...
- CUDA刷新:GPU计算生态系统
CUDA刷新:GPU计算生态系统 CUDA Refresher: The GPU Computing Ecosystem 这是CUDA Refresher系列的第三篇文章,其目标是刷新CUDA中的关键 ...
随机推荐
- 仿淘宝头像上传功能(三)——兼容 IE6 浏览器。
前两篇目录: 仿淘宝头像上传功能(一)——前端篇. 仿淘宝头像上传功能(二)——程序篇. 仿淘宝头像上传功能(三)——兼容 IE6 浏览器 之前的这两篇虽然实现了功能,但不兼容低版本浏览器,而且有些浏 ...
- flash builder注释字体看不清
window-preferences-flex-editiors-syntex coloring-ActionScript-Comment (窗口-首选项-flashbuilder-编辑器-语法着色- ...
- visual studio清理nuget包缓存
最近在使用nuget包的时候发现一个问题.昨天我组长明明发了一个新版本的包上去,可在我电脑上死活找不到这个新版本的包.刷新,重启vs,重启电脑,好长时间才出来.今天又碰到这个问题了,在同事电脑上都能搜 ...
- 撩课-Java每天10道面试题第7天
撩课Java+系统架构 视频 点击开始学习 61.什么是并发修改异常? 什么是并发修改异常: 当我们在遍历实现了collection接口 与iterator接口的集合时(List.Set.Map), ...
- java 包装类和基础数据
package com.tercher.demo; public class LangClass { public static void main(String[] args) { //所有的包装类 ...
- 自定义select 小三角
把select小三角换成自己的图片 效果: css样式: <style> #my_select { display: flex; display: -webkit-flex; width: ...
- bzoj1201: [HNOI2005]数三角形----递推+bitset
-by bzoj http://www.lydsy.com/JudgeOnline/problem.php?id=1201 枚举所有交点,统计每个以每个点为顶点的正三角和和以每个点为左端点的反三角 ...
- BZOJ P1212 [HNOI2004] L语言
标点符号的出现晚于文字的出现,所以以前的语言都是没有标点的.现在你要处理的就是一段没有标点的文章. 一段文章T是由若干小写字母构成.一个单词W也是由若干小写字母构成.一个字典D是若干个单词的集合. 我 ...
- drupal读取mysql的longblob字段
unserialize($event->variables)
- Word 关闭 Passive Voice
Sheryl prefers passive voice for some of her writing (such as business documents and correspondenc ...