(一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要:
1.以动态图形式计算一个简单的加法
2.cpu和gpu计算力比较(包括如何指定cpu和gpu)
3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.cnblogs.com/liuhuacai/p/11684666.html
正文:
1.在tensorflow中计算3.+4.
##1.创建输入张量
a = tf.constant(2.)
b = tf.constant(4.)
##2.计算结果
print('a+b=',a+b)
输出:a+b= tf.Tensor(7.0, shape=(), dtype=float32)
总结:20版本在加法实现过程中简单了不少,所见即所得。(1.x的实现过程相对复杂)据说动态的实现也是后端转化成静态图实现的。
2.cpu和gpu计算力比较
说明:通过计算不同大小的矩阵乘法,获得计算时间。
1.指定cpu或gpu通过 with tf.device('/cpu:0'):或 with tf.device('/gpu:0'):指定,在需要加速的操作前添加即可(此处生成随机 数和矩阵乘法都加速)
2.统计计算时间的函数timeit.timeit需要导入import timeit【timeit.timeit(需计时的函数或语句,计算次数)】
3.计算量的大小与cpu和gpu计算时间的关系,计算量通过改变矩阵大小实现
import tensorflow as tf
import timeit
以矩阵A[10,n]和矩阵B[n,10]的乘法运算(分别在cpu和gpu上运行)来测试,
'''
with tf.device('/cpu:0'): ##指定操作用cpu计算
cpu_a = tf.random.normal([10,n]) ##生成符合高斯分布的随机数矩阵,通过改变n大小,增减计算量
cpu_b = tf.random.normal([n,10])
print(cpu_a.device,cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([100n])
gpu_b = tf.random.normal([n,10])
print(gpu_a.device,gpu_b.device)
def cpu_run():
with tf.device('/cpu:0'): ##矩阵乘法,此操作采用cpu计算
c = tf.matmul(cpu_a,cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'): ##矩阵乘法,此操作采用gpu计算
c = tf.matmul(gpu_a,gpu_b)
return c
##第一次计算需要热身,避免将初始化时间计算在内
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)
print('warmup:',cpu_time,gpu_time)
##正式计算10次,取平均值
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)
print('run_time:',cpu_time,gpu_time)
通过改变矩阵大小,增加矩阵乘法的计算量:计算结果如下
结论:1.在计算量较小的情况下,cpu的计算速度比gpu计算速度快,但是都是微量级别的差异
2.随着计算量的增加,cpu的计算时间逐步增加,而gpu的计算时间相对平缓,在计算量达到一定程度之后,gpu的优势就出来了。
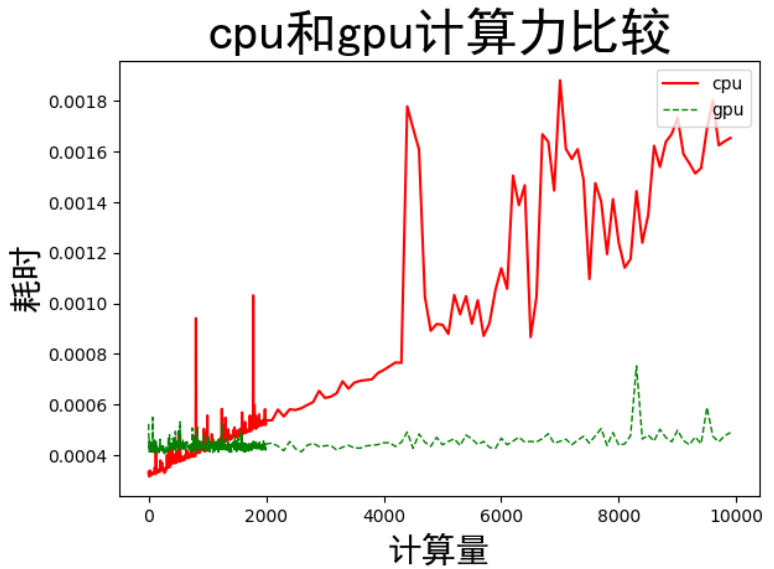
实现过程的完整代码:
import tensorflow as tf
import timeit
import matplotlib.pyplot as plt
'''
以矩阵A[10,n]和矩阵B[n,10]的乘法运算(分别在cpu和gpu上运行)来测试,
'''
def cpu_gpu_compare(n):
with tf.device('/cpu:0'): ##指定操作用cpu计算
cpu_a = tf.random.normal([10,n]) ##生成符合高斯分布的随机数矩阵,通过改变n大小,增减计算量
cpu_b = tf.random.normal([n,10])
print(cpu_a.device,cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10,n])
gpu_b = tf.random.normal([n,10])
print(gpu_a.device,gpu_b.device)
def cpu_run():
with tf.device('/cpu:0'): ##矩阵乘法,此操作采用cpu计算
c = tf.matmul(cpu_a,cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'): ##矩阵乘法,此操作采用gpu计算
c = tf.matmul(gpu_a,gpu_b)
return c
##第一次计算需要热身,避免将初始化时间计算在内
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)
print('warmup:',cpu_time,gpu_time)
##正式计算10次,取平均值
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)
print('run_time:',cpu_time,gpu_time)
return cpu_time,gpu_time
n_list1 = range(1,2000,5)
n_list2 = range(2001,10000,100)
n_list = list(n_list1)+list(n_list2)
time_cpu =[]
time_gpu =[]
for n in n_list:
t=cpu_gpu_compare(n)
time_cpu.append(t[0])
time_gpu.append(t[1])
plt.plot(n_list,time_cpu,color = 'red',label='cpu')
plt.plot(n_list,time_gpu,color='green',linewidth=1.0,linestyle='--',label='gpu')
plt.ylabel('耗时',fontproperties = 'SimHei',fontsize = 20)
plt.xlabel('计算量',fontproperties = 'SimHei',fontsize = 20)
plt.title('cpu和gpu计算力比较',fontproperties = 'SimHei',fontsize = 30)
plt.legend(loc='upper right')
plt.show()
(一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)的更多相关文章
- DirectX 总结和DirectX 9.0 学习笔记
转自:http://www.cnblogs.com/graphics/archive/2009/11/25/1583682.html DirectX 总结 DDS DirectXDraw Surfac ...
- 一起学ASP.NET Core 2.0学习笔记(二): ef core2.0 及mysql provider 、Fluent API相关配置及迁移
不得不说微软的技术迭代还是很快的,上了微软的船就得跟着她走下去,前文一起学ASP.NET Core 2.0学习笔记(一): CentOS下 .net core2 sdk nginx.superviso ...
- SQL反模式学习笔记1 开篇
什么是“反模式” 反模式是一种试图解决问题的方法,但通常会同时引发别的问题. 反模式分类 (1)逻辑数据库设计反模式 在开始编码之前,需要决定数据库中存储什么信息以及最佳的数据组织方式和内在关联方式. ...
- vue2.0学习笔记之路由(二)路由嵌套+动画
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- vue2.0学习笔记之路由(二)路由嵌套
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- TensorFlow机器学习框架-学习笔记-001
# TensorFlow机器学习框架-学习笔记-001 ### 测试TensorFlow环境是否安装完成-----------------------------```import tensorflo ...
- hdcms v5.7.0学习笔记
hdcms v5.7.0学习笔记 https://note.youdao.com/ynoteshare1/index.html?id=c404d63ac910eb15a440452f73d6a6db& ...
- dhtmlxgrid v3.0学习笔记
dhtmlxgrid v3.0学习笔记 分类: dhtmlx JavaScript2012-01-31 15:41 1744人阅读 评论(0) 收藏 举报 stylesheetdatecalendar ...
- OAuth 2.0学习笔记
文章目录 OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务商提供商"进行互动. OAuth在"客户端&quo ...
随机推荐
- laravel实现excel表的导入导出功能
1.这是个我去公司之后曾经折磨我很久很久的功能查阅了很多资料但是功夫不负有心人在本人的不懈努力下还是实现了这个功能 (ps看不懂我下面说讲述的可以参考这个laravel学院的官方文档 https:// ...
- JS高级---继承
继承 面向对象编程思想: 根据需求, 分析对象, 找到对象有什么特征和行为, 通过代码的方式来实现需求, 要想实现这个需求,就要创建对象 ,要想创建对象, 就应该显示有构造函数, 然后通过构造函数来创 ...
- C#处理不同的JSON数据
https://blog.csdn.net/dayu9216/article/details/78465681 网络中数据传输经常是xml或者json,现在做的一个项目之前调其他系统接口都是返回的xm ...
- 题解【SP8002】HORRIBLE - Horrible Queries
题面 题解 这是一道线段树的模板题. 题目需要我们维护一个支持区间修改.区间查询的一个数据结构,很容易想到线段树. 然后发现和洛谷上线段树的模板1是同一道题. 由于本题中每个数的初始值都为\(0\), ...
- 源码安装python 报错,openssl: error while loading shared libraries: libssl.so.1.1
在执行openssl version出现如下错误: openssl: error while loading shared libraries: libssl.so.1.1: cannot open ...
- SFSA
#include<stdio.h> #include<string.h> #include<math.h> #include<iostream> #in ...
- hadoop学习笔记(九):mapReduce1.x和2.x
一.MapReduce1.0的数据分割到数据计算的过程 MapReduce是我们再进行离线大数据处理的时候经常要使用的计算模型,MapReduce的计算过程被封装的很好,我们只用使用Map和Reduc ...
- codeforces C. Primes and Multiplication(快速幂 唯一分解定理)
题目链接:http://codeforces.com/contest/1228/problem/C 题解:给定一个函数f,g,题目有描述其中的表达式含义和两者之间的关系. 然后计算: 首先把给定的x用 ...
- io型和有状态的应用不放入k8s,而是做服务映射
io型和有状态的应用不放入k8s,而是做服务映射 待办 在实际应用中,一般不会把mysql这种重IO.有状态的应用直接放入k8s中,而是使用专用的服务器来独立部署.而像web这种无状态应用依然会运行在 ...
- angular 输入框自动绑定值最长为16位,超过16位则会报错
最近发现angular在使用input输入框的ng-model绑定scope变量的时候,发现,输入长串的数字将会出错.代码如下: <html> <head> <meta ...