python pandas 基础理解
其实每一篇博客我都要用很多琐碎的时间片段来学完写完,每次一点点,用到了就学一点,学一点就记录一点,要用上好几天甚至一两个礼拜才感觉某一小类的知识结构学的差不多了。
Pandas 是基于 NumPy 的一个开源 Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。它的名字来源是由“ Panel data”(面板数据,一个计量经济学名词)两个单词拼成的。简单地说,你可以把 Pandas 看作是 Python 版的 Excel。
一. 数据结构介绍
在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用
1.Series的介绍
1)用一维数组创建序列
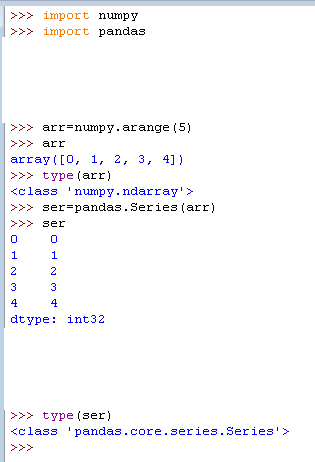
2)通过字典创建序列
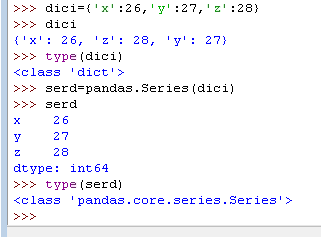
2.DataFrame
1)用字典创建DataFrame

2)查 其中某一列
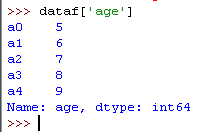
我们只获取一列,所以返回的就是一个 Series。可以用 type() 函数确认返回值的类型

3)查多列
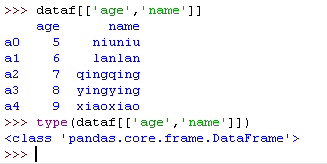
多列的是DataFrame
4)增加一个新列--------直接加

5)增加一个新列--------用现有的列去产生新的列

6)从 DataFrame 里删除行/列
想要删除某一行或一列,可以用 .drop() 函数。在使用这个函数的时候,你需要先指定具体的删除方向,axis=0 对应的是行 row,而 axis=1 对应的是列 column 。

查一下

这是为了防止误删除
7) 真删除某列,再加个参数就好了
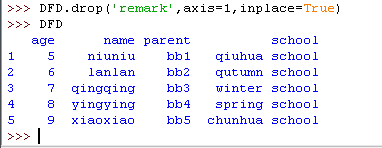
8)获取某行,或者某几行
 ]
]
列是同一个道理
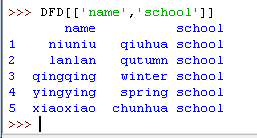
9)加筛选条件
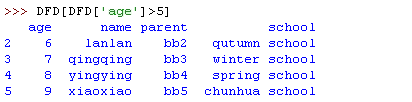
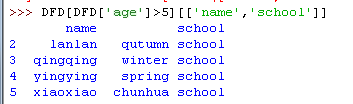
10)新加一列
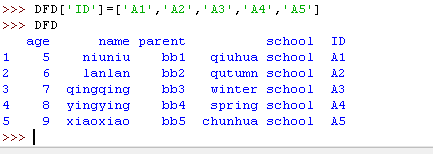
11)重置索引
可以用 .reset_index() 简单地把整个表的索引都重置掉
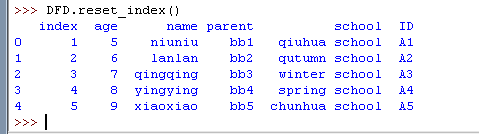
和删除操作差不多,.reset_index() 并不会永久改变你表格的索引,除非你调用的时候明确传入了 inplace 参数,比如:.reset_index(inplace=True)
还可以用 .set_index() 方法,将 DataFrame 里的某一列作为索引来用
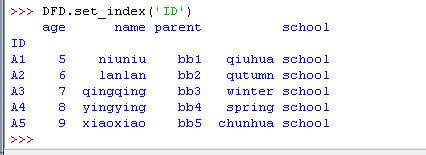
注意,不像 .reset_index() 会保留一个备份,然后才用默认的索引值代替原索引,.set_index() 将会完全覆盖原来的索引值。
12)创建多级索引ata
多级索引其实就是一个由元组(Tuple)组成的数组,每一个元组都是独一无二的
可以从一个包含许多数组的列表中创建多级索引(调用 MultiIndex.from_arrays ),
也可以用一个包含许多元组的数组(调用 MultiIndex.from_tuples )
用一对可迭代对象的集合(比如两个列表,互相两两配对)来构建(调用MultiIndex.from_product )。
举个例子
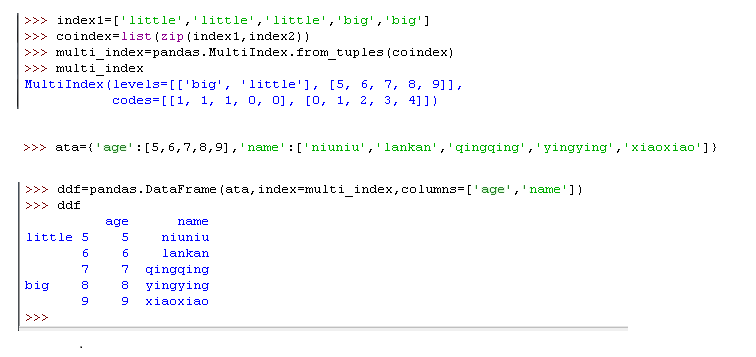
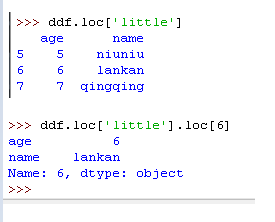
13) 获取多级索引中的数据,还是用到 .loc[]
3.清洗数据
1)删除或者填充空值
在许多情况下,如果你用 Pandas 来读取大量数据,往往会发现原始数据中会存在不完整的地方。在 DataFrame 中缺少数据的位置, Pandas 会自动填入一个空值,比如 NaN或 Null 。因此,我们可以选择用 .dropna() 来丢弃这些自动填充的值,或是用.fillna() 来自动给这些空值填充数据。
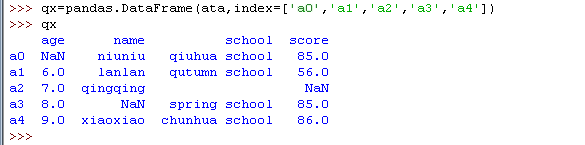
当你使用 .dropna() 方法时,就是告诉 Pandas 删除掉存在一个或多个空值的行(或者列)。删除行用的是 .dropna(axis=0) ,删除列用的是 .dropna(axis=1) 。

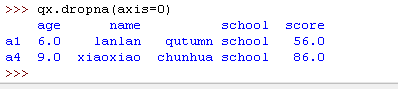
请注意,如果你没有指定 axis 参数,默认是删除行。
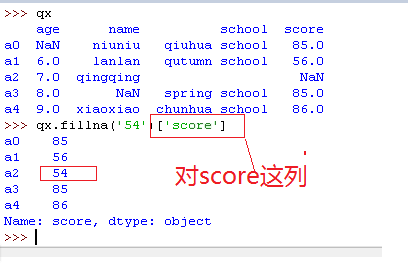
2)替换na
如果你使用 .fillna() 方法,Pandas 将对这个 DataFrame 里所有的空值位置填上你指定的默认值
4.数据描述
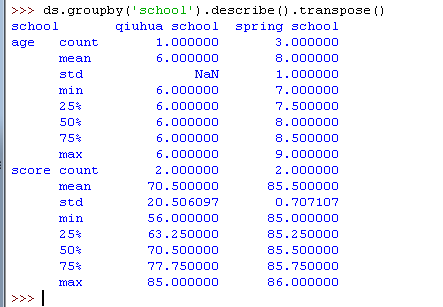
1) describe()
Pandas 的 .describe() 方法将对 DataFrame 里的数据进行分析,并一次性生成多个描述性的统计指标,方便用户对数据有一个直观上的认识。
生成的指标,从左到右分别是:计数、平均数、标准差、最小值、25% 50% 75% 位置的值、最大值。

如果你不喜欢这个排版,你可以用 .transpose() 方法获得一个竖排的格式:
2) 堆叠(Concat)

因为我们没有指定堆叠的方向,Pandas 默认按行的方向堆叠,把每个表的索引按顺序叠加。如果你想要按列的方向堆叠,那你需要传入 axis=1 参数:
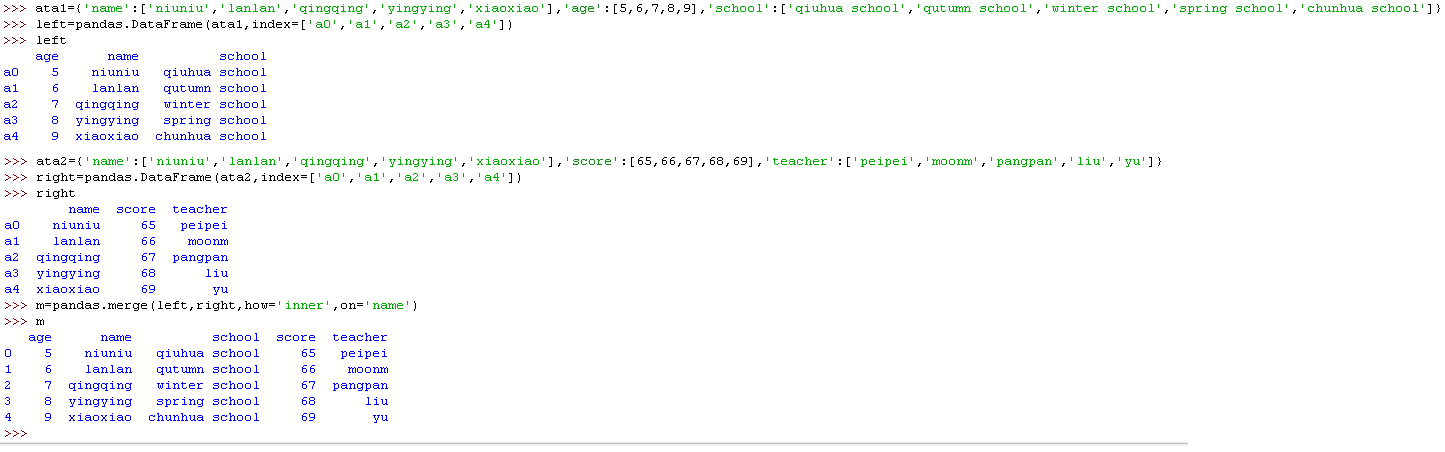
3)归并(Merge)
使用 pd.merge() 函数,能将多个 DataFrame 归并在一起,它的合并方式类似合并 SQL 数据表的方式。
归并操作的基本语法是 pd.merge(left, right, how='inner', on='Key') 。其中 left 参数代表放在左侧的 DataFrame,而 right 参数代表放在右边的 DataFrame;how='inner' 指的是当左右两个 DataFrame 中存在不重合的 Key 时,取结果的方式:inner 代表交集;Outer 代表并集。最后,on='Key' 代表需要合并的键值所在的列,最后整个表格会以该列为准进行归并。
其他的 就 不 一一举例了
同时,我们可以传入多个 on 参数,这样就能按多个键值进行归并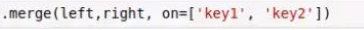
4)join
如果你要把两个表连在一起,然而它们之间没有太多共同的列,那么你可以试试 .join() 方法。和 .merge() 不同,连接采用索引作为公共的键,而不是某一列。
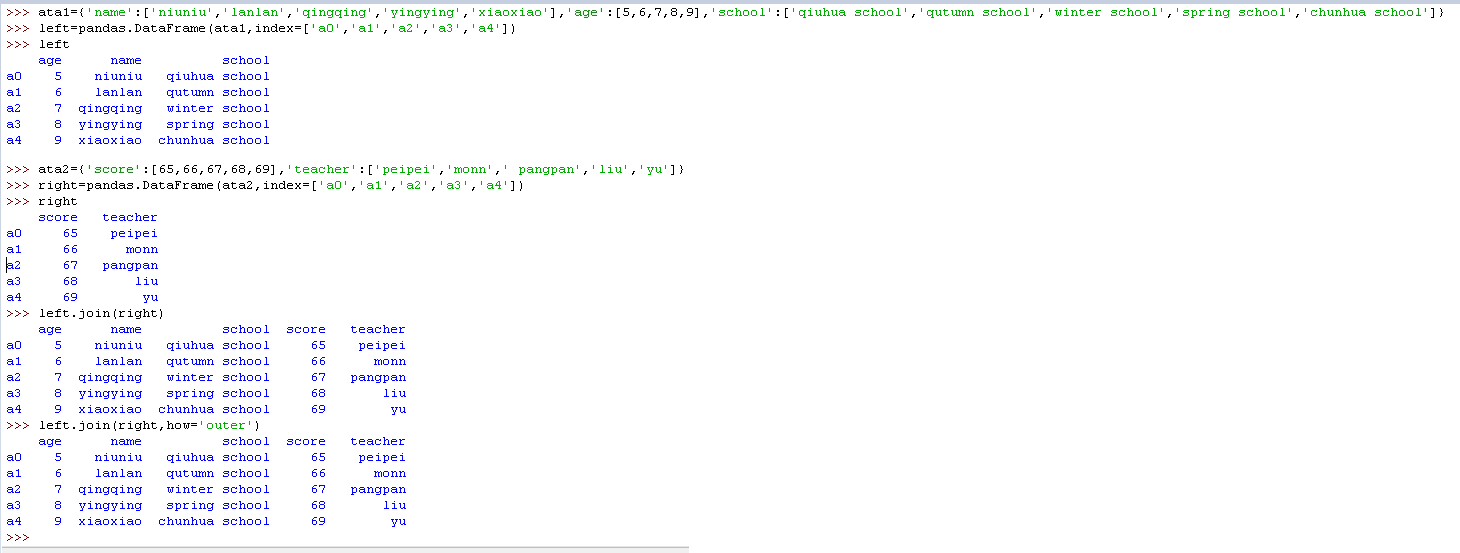
同样,inner 代表交集,Outer 代表并集
5.数值处理
1)查找不重复的值
unique() 方法

查个数

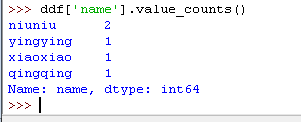
还可以用 .value_counts() 同时获得所有值和对应值的计数
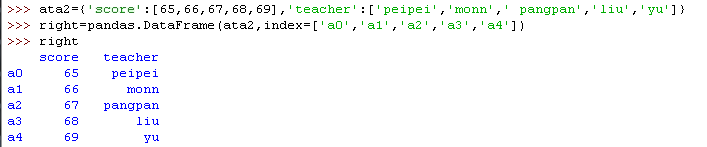
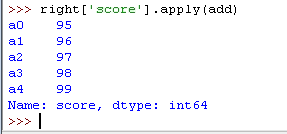
2).apply() 方法,应用自定义函数
用 .apply() 方法,可以对 DataFrame 中的数据应用自定义函数,进行数据处理

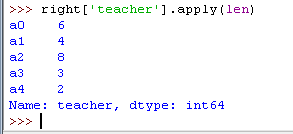
3)调用内置函数
4) 用 lambda 表达式
你定义了一个函数,而它其实只会被用到一次。那么,我们可以用 lambda 表达式来代替函数定义,简化代码

5) DataFrame 的属性
DataFrame 的属性包括列和索引的名字。假如你不确定表中的某个列名是否含有空格之类的字符,你可以通过 .columns 来获取属性值,以查看具体的列名。

6)排序
如果想要将整个表按某一列的值进行排序,可以用 .sort_values() :
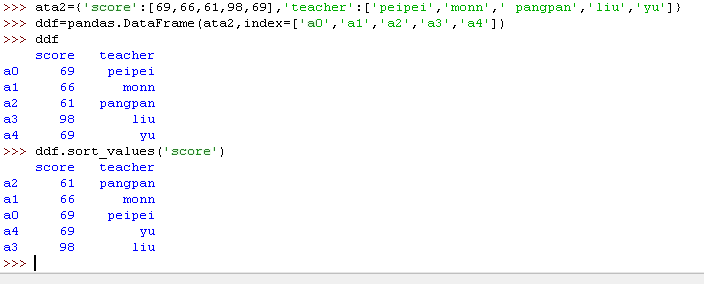
如上所示,表格变成按 col2 列的值从小到大排序。要注意的是,表格的索引 index 还是对应着排序前的行,并没有因为排序而丢失原来的索引数据。
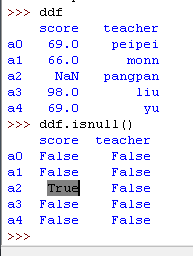
7)查找空值
可以用 Pandas 的 .isnull() 方法,方便快捷地发现表中的空值
参考:
https://blog.csdn.net/qq_42156420/article/details/82813482
https://www.cnblogs.com/nxld/p/6058591.html
python pandas 基础理解的更多相关文章
- python——pandas基础
参考: 实验楼:https://www.shiyanlou.com/courses/1091/learning/?id=6138 <利用python进行数据分析> pandas简介 Pan ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
随机推荐
- 洛谷P3224 永无乡 [HNOI2012] 线段树/splay/treap
正解:线段树合并 解题报告: 传送门! 这题也是有很多解法,eg:splay,treap,... 然而我都不会我会学的QAQ! 反正今天就只讲下线段树合并怎么做QAQ 首先看到这样子的说第k重要的是什 ...
- oracle按照指定列分组合计group by rollup()
group by rollup() 按分组合计 select grouping(status),status,owner,object_type,count(*) from dba_objects w ...
- Docker 引擎(三)
Docker 引擎是一个包含以下主要组件的客户端服务器应用程序. 一种服务器,它是一种称为守护进程并且长时间运行的程序. REST API用于指定程序可以用来与守护进程通信的接口,并指示它做什么. 一 ...
- [Android][Android Studio] Gradle项目中加入JNI生成文件(.so文件)
版权声明:本文作者:Qiujuer https://github.com/qiujuer; 转载请注明出处,盗版必究! ! ! https://blog.csdn.net/qiujuer/articl ...
- docker+redis安装与配置,主从+哨兵模式
docker+redis安装与配置 docker安装redis并且使用redis挂载的配置启动 1.拉取镜像 docker pull redis:3.2 2.准备准备挂载的目录和配置文件 首先在/do ...
- 火币网API文档——WebSocket API错误码
错误信息返回格式 { "id": "id generate by client", "status": "error", ...
- RestFramework自定制之认证和权限、限制访问频率
认证和权限 所谓认证就是检测用户登陆与否,通常与权限对应使用.网站中都是通过用户登录后由该用户相应的角色认证以给予对应的权限. 权限是对用户对网站进行操作的限制,只有在拥有相应权限时才可对网站中某个功 ...
- shell脚本循环和信号
条件判断 if 条件1:then COMMAND elif 条件2:then COMMAND else COMMAND(:) : 表示pass 不执行任何命令 fi 读取用 ...
- vue 上传图片 input=file
一.逻辑 点击li触发事件chooseImage 即触发input标签事件photoChange input标签事件photoChange file返回的是如下变量 模拟上传表单方法 执行上传 二.代 ...
- 死锁与递归锁 信号量 event 线程queue
1.死锁现象与递归锁 死锁:是指两个或两个以上的进程或线程在执行过程中,因争抢资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去,此时称系统处于死锁状态或系统产生了死锁,这些永远在互相 ...