『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度。FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可以和经典网络组合提升原网络效果。
一、问题背景
网络的深度(对应到感受野)与总stride通常是一对矛盾的东西,常用的网络结构对应的总stride一般会比较大(如32),而图像中的小物体甚至会小于stride的大小,造成的结果就是小物体的检测性能急剧下降。
传统解决这个问题的思路包括:
(1)多尺度训练和测试,又称图像金字塔,如下图(a)所示。目前几乎所有在ImageNet和COCO检测任务上取得好成绩的方法都使用了图像金字塔方法。然而这样的方法由于很高的时间及计算量消耗,难以在实际中应用。
(2)特征分层,即每层分别预测对应的scale分辨率的检测结果。如下图(c)所示。SSD检测框架采用了类似的思想。这样的方法问题在于直接强行让不同层学习同样的语义信息。而对于卷积神经网络而言,不同深度对应着不同层次的语义特征,浅层网络分辨率高,学的更多是细节特征,深层网络分辨率低,学的更多是语义特征。

因而,目前多尺度的物体检测主要面临的挑战为:
1. 如何学习具有强语义信息的多尺度特征表示?
2. 如何设计通用的特征表示来解决物体检测中的多个子问题?如object proposal, box localization, instance segmentation.
3. 如何高效计算多尺度的特征表示?
二、特征金字塔网络(Feature Pyramid Networks)
作者提出了FPN算法。做法很简单,如下图所示。把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。
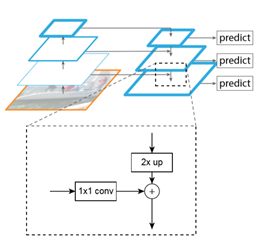
图中未注明的是融合之后的feat还需要进行一次3*3卷积
作者的算法结构可以分为三个部分:自下而上的卷积神经网络(上图左),自上而下过程(上图右)和特征与特征之间的侧边连接。
自下而上的部分其实就是卷积神经网络的前向过程。在前向过程中,特征图的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变特征图大小的层归为一个阶段,因此每次抽取的特征都是每个阶段的最后一个层的输出,这样就能构成特征金字塔。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出。
自上而下的过程采用上采样进行。上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,从而扩大原图像的大小。通过对特征图进行上采样,使得上采样后的特征图具有和下一层的特征图相同的大小。
根本上来说,侧边之间的横向连接是将上采样的结果和自下而上生成的特征图进行融合。我们将卷积神经网络中生成的对应层的特征图进行1×1的卷积操作,将之与经过上采样的特征图融合,得到一个新的特征图,这个特征图融合了不同层的特征,具有更丰富的信息。 这里1×1的卷积操作目的是改变channels,要求和后一层的channels相同。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应,如此就得到了一个新的特征图。这样一层一层地迭代下去,就可以得到多个新的特征图。假设生成的特征图结果是P2,P3,P4,P5,它们和原来自底向上的卷积结果C2,C3,C4,C5一一对应。金字塔结构中所有层级共享分类层(回归层)。
三、fast rcnn中的特征金字塔
Fast rcnn中的ROI Pooling层使用region proposal的结果和特征图作为输入。经过特征金字塔,我们得到了许多特征图,作者认为,不同层次的特征图上包含的物体大小也不同,因此,不同尺度的ROI,使用不同特征层作为ROI pooling层的输入。大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。但是如何确定不同的roi对应的不同特征层呢?作者提出了一种方法:,224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值做取整处理。这意味着如果RoI的尺度变小(比如224的1/2),那么它应该被映射到一个精细的分辨率水平。
与RPN一样,FPN每层feature map加入3*3的卷积及两个相邻的1*1卷积分别做分类和回归的预测。在RPN中,实验对比了FPN不同层feature map卷积参数共享与否,发现共享仍然能达到很好性能,说明特征金字塔使得不同层学到了相同层次的语义特征。
用于RPN的FPN:用FPN替换单一尺度的FMap。它们对每个级都有一个单一尺度的anchor(不需要多级作为其FPN)。它们还表明,金字塔的所有层级都有相似的语义层级。
Faster RCNN:他们以类似于图像金字塔输出的方式观察金字塔。因此,使用下面这个公式将RoI分配到特定level。
其中w,h分别表示宽度和高度。k是分配RoI的level。
是w,h=224,224时映射的level。
四、其他问题
Q1:不同深度的feature map为什么可以经过upsample后直接相加?
答:作者解释说这个原因在于我们做了end-to-end的training,因为不同层的参数不是固定的,不同层同时给监督做end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。
Q2:为什么FPN相比去掉深层特征upsample(bottom-up pyramid)对于小物体检测提升明显?(RPN步骤AR从30.5到44.9,Fast RCNN步骤AP从24.9到33.9)
答:作者在poster里给出了这个问题的答案

对于小物体,一方面我们需要高分辨率的feature map更多关注小区域信息,另一方面,如图中的挎包一样,需要更全局的信息更准确判断挎包的存在及位置。
Q3:如果不考虑时间情况下,image pyramid是否可能会比feature pyramid的性能更高?
答:作者觉得经过精细调整训练是可能的,但是image pyramid(金字塔)主要的问题在于时间和空间占用太大,而feature pyramid可以在几乎不增加额外计算量情况下解决多尺度检测问题。
五、代码层面看FPN
本部分截取自知乎文章:从代码细节理解 FPN,作者使用Mask-RCNN的源码辅助理解FPN结构,项目地址见MRCNN,关于MRCNN,文章『计算机视觉』RCNN学习_其三:Mask-RCNN会介绍。
1、 怎么做的上采样?
高层特征怎么上采样和下一层的特征融合的,代码里面可以看到:
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)
C5是 resnet最顶层的输出,它会先通过一个1*1的卷积层,同时把通道数转为256,得到FPN 的最上面的一层 P5。
KL.UpSampling2D(size=(2, 2),name="fpn_p5upsampled")(P5)
Keras 的 API 说明告诉我们:

也就是说,这里的实现使用的是最简单的上采样,没有使用线性插值,没有使用反卷积,而是直接复制。
2、 怎么做的横向连接?
P4 = KL.Add(name="fpn_p4add")
([KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256,(1, 1), name='fpn_c4p4')(C4)])
这里可以很明显的看到,P4就是上采样之后的 P5加上1*1 卷积之后的 C4,这里的横向连接实际上就是像素加法,先把 P5和C4转换到一样的尺寸,再直接进行相加。
注意这里对从 resnet抽取的特征图做的是 1*1 的卷积:
1x1的卷积我认为有三个作用:使bottom-up对应层降维至256;缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定;组合特征。
3、 FPN自上而下的网络结构代码怎么实现?
# 先从 resnet 抽取四个不同阶段的特征图 C2-C5。
_, C2, C3, C4, C5 =
resnet_graph(input_image, config.BACKBONE,stage5=True, train_bn=config.TRAIN_BN) # Top-down Layers 构建自上而下的网络结构
# 从 C5开始处理,先卷积来转换特征图尺寸
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)
# 上采样之后的P5和卷积之后的 C4像素相加得到 P4,后续的过程就类似了
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1),name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2),name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)]) # P2-P5最后又做了一次3*3的卷积,作用是消除上采样带来的混叠效应
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2,name="fpn_p6")(P5) # 注意 P6是用在 RPN 目标区域提取网络里面的,而不是用在 FPN 网络
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
# 最后得到了5个融合了不同层级特征的特征图列表;
注意 P6是用在 RPN 目标区域提取网络里面的,而不是用在 FPN 网络;
另外这里 P2-P5最后又做了一次3*3的卷积,作用是消除上采样带来的混叠效应。
4、 如何确定某个 ROI 使用哪一层特征图进行 ROIpooling ?
看代码:
# Assign each ROI to a level in the pyramid based on the ROI area.
# 这里的 boxes 是 ROI 的框,用来计算得到每个 ROI 框的面积
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Use shape of first image. Images in a batch must have the same size.
# 这里得到原图的尺寸,计算原图的面积
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
# 原图面积
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32) # 分两步计算每个 ROI 框需要在哪个层的特征图中进行 pooling
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?论文的 K 使用如下公式,代码做了一点更改,替换为roi_level:
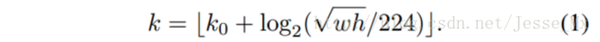
# 代码里面的计算替换为以下计算方式:
roi_level = min(5, max(2, 4 + log2(sqrt(w * h) / ( 224 / sqrt(image_area)) ) ) )
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,image_area是输入图片的长乘以宽,即输入图片的面积,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值会做取整处理,防止结果不是整数。
5、 上面得到的5个融合了不同层级的特征图怎么使用?
可以看到,这里只使用2-5四个特征图:
for i, level in enumerate(range(2, 6)):
# 先找出需要在第 level 层计算ROI
ix = tf.where(tf.equal(roi_level, level))
level_boxes = tf.gather_nd(boxes, ix) # Box indicies for crop_and_resize.
box_indices = tf.cast(ix[:, 0], tf.int32) # Keep track of which box is mapped to which level
box_to_level.append(ix) # Stop gradient propogation to ROI proposals
level_boxes = tf.stop_gradient(level_boxes)
box_indices = tf.stop_gradient(box_indices) # Crop and Resize
# From Mask R-CNN paper: "We sample four regular locations, so
# that we can evaluate either max or average pooling. In fact,
# interpolating only a single value at each bin center (without
# pooling) is nearly as effective."
#
# Here we use the simplified approach of a single value per bin,
# which is how it's done in tf.crop_and_resize()
# Result: [batch * num_boxes, pool_height, pool_width, channels]
# 使用 tf.image.crop_and_resize 进行 ROI pooling
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
对每个 box,都提取其中每一层特征图上该box对应的特征,然后组成一个大的特征列表pooled。
6、 金字塔结构中所有层级共享分类层是怎么回事?
先看代码:
# ROI Pooling
# Shape: [batch, num_boxes, pool_height, pool_width, channels]
# 得到经过 ROI pooling 之后的特征列表
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps) # 将上面得到的特征列表送入 2 个1024通道数的卷积层以及 2 个 rulu 激活层
# Two 1024 FC layers (implemented with Conv2D for consistency)
x = KL.TimeDistributed(KL.Conv2D(1024, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(1024, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x) shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x) # 分类层
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits) # BBOX 的位置偏移回归层
# BBox head
# [batch, boxes, num_classes * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, boxes, num_classes, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
这里的PyramidROIAlign得到的 x就是上面一步得到的从每个层的特征图上提取出来的特征列表,这里对这个特征列表先接两个1024通道数的卷积层,再分别送入分类层和回归层得到最终的结果。
也就是说,每个 ROI 都在P2-P5中的某一层得到了一个特征,然后送入同一个分类和回归网络得到最终结果。
FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
7、 它的思想是什么?
把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
8、 横向连接起什么作用?
如果不进行特征的融合(也就是说去掉所有的1x1侧连接),虽然理论上分辨率没变,语义也增强了,但是AR下降了10%左右!作者认为这些特征上下采样太多次了,导致它们不适于定位。Bottom-up的特征包含了更精确的位置信息。
六、资源资料
Feature Pyramid Networks for Object Detection(CVPR 2017论文)
详解何恺明团队4篇大作 | 从特征金字塔网络、Mask R-CNN到学习分割一切
源码资料:
官方:Caffe2
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
Caffe
https://github.com/unsky/FPN
PyTorch
https://github.com/kuangliu/pytorch-fpn (just the network)
MXNet
https://github.com/unsky/FPN-mxnet
Tensorflow
https://github.com/yangxue0827/FPN_Tensorflow
『计算机视觉』FPN:feature pyramid networks for object detection的更多相关文章
- 【Network Architecture】Feature Pyramid Networks for Object Detection(FPN)论文解析(转)
目录 0. 前言 1. 博客一 2.. 博客二 0. 前言 这篇论文提出了一种新的特征融合方式来解决多尺度问题, 感觉挺有创新性的, 如果需要与其他网络进行拼接,还是需要再回到原文看一下细节.这里 ...
- Feature Pyramid Networks for Object Detection比较FPN、UNet、Conv-Deconv
https://vitalab.github.io/deep-learning/2017/04/04/feature-pyramid-network.html Feature Pyramid Netw ...
- Feature Pyramid Networks for Object Detection
Feature Pyramid Networks for Object Detection 特征金字塔网络用于目标检测 论文地址:https://arxiv.org/pdf/1612.03144.pd ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 论文阅读 | FPN:Feature Pyramid Networks for Object Detection
论文地址:https://arxiv.org/pdf/1612.03144v2.pdf 代码地址:https://github.com/unsky/FPN 概述 FPN是FAIR发表在CVPR 201 ...
- FPN(feature pyramid networks)
多尺度的object detection算法:FPN(feature pyramid networks). 原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征 ...
- FPN-Feature Pyramid Networks for Object Detection
FPN-Feature Pyramid Networks for Object Detection 标签(空格分隔): 深度学习 目标检测 这次学习的论文是FPN,是关于解决多尺度问题的一篇论文.记录 ...
- Parallel Feature Pyramid Network for Object Detection
Parallel Feature Pyramid Network for Object Detection ECCV2018 总结: 文章借鉴了SPP的思想并通过MSCA(multi-scale co ...
- 『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
一.模块概述 上节的最后,我们进行了如下操作获取了有限的proposal, # [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)] # IMAGES_PER_GP ...
随机推荐
- arm中断体系结构
ARM处理器中有7种类型的异常,按优先级从高到低的排列如下: 复位异常(Reset). 数据异常(Data Abort). 快速中断异常(FIQ) ...
- Shiro学习笔记(二)
首先还是先搭建工程运行环境 依旧搭建的是Maven工程,如果不是Maven 也可以去网上找jar包然后导入 (我使用Maven主要是找依赖配置文件就行,我自己导jar包的时候就是很容易报错) 还是先 ...
- POJ 3693 Maximum repetition substring(连续重复子串)
http://poj.org/problem?id=3693 题意:给定一个字符串,求重复次数最多的连续重复子串. 思路: 这道题确实是搞了很久,首先枚举连续子串的长度L,那么子串肯定包含了r[k], ...
- php的Allowed memory size of 134217728 bytes exhausted问题
提示Allowed memory size of 134217728 bytes exhausted,出现这种错误的情况常见的有三种: 0:查询的数据量大. 1:数据量不大,但是php.ini配置的内 ...
- C#:导入Excel通用类(Xls格式)
PS:在CSV格式和XLSX格式中有写到通用调用的接口和引用的插件,所以在这个xls格式里面并没有那么详细,只是配上xls通用类. 一.引用插件NPOI.dll.NPOI.OOXML.dll.NPOI ...
- ros 节点关闭后重启
加入参数 respawn="true"
- Hibernate的查询功能
1.Query对象 1.使用Query对象,不需要写sql语句,但是写hql语句 (1)hql:hibernate query language,提供查询语言,这个hql语言和普通sql语句相似 (2 ...
- Mysql简单入门
这两天比较懒,没有学习,这个是我问一个学java的小伙伴要的sql的总结资料,大体语句全在上面了,复制到博客上,以后忘记可以查看 #1命令行连接MySQLmsyql -u root -proot;#2 ...
- Q-Q图
来自:https://mp.weixin.qq.com/s/_UTKNcOgKQcCogk2C2tsQQ 正负样本数据集符合独立同分布是构建机器学习模型的前提,从概率的角度分析,样本数据独立同分布是正 ...
- Qt532.QString_填充字符
1.代码: void MainWindow::on_pushButton_clicked() { QString str = "; QString str01 = str.leftJusti ...