HDFS原理讲解
简介
本文是笔者在学习HDFS的时候的学习笔记整理, 将HDFS的核心功能的原理都整理在这里了。
【广告】 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/xuanku/p/index.html
HDFS的基础架构
见下图, 核心角色: Client, NameNode, Secondary NameNode, DataNode
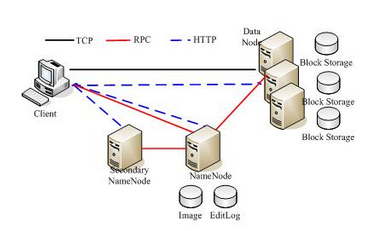
Client: 对用户提供系列操作工具&API
NameNode:
- 包含
map<filename, list<block_id>>, 以及map<block_id, list<DataNode>>的数据结构 - 资源分配算法
- 包含
DataNode:
- 管理好自己的磁盘, 上报数据给NameNode
读取过程
- Client向NameNode读取数据分布式信息
- Client找到第一个数据块离自己最近的DataNode
- 跟这个DataNode交互并获取数据
- 读完之后开始跟下一个数据块离自己最近的DataNode交互
- 读完之后close连接
- 如果读取过程中读取失败, 将会依次读取该数据块下一个副本, 失败的节点将被记录, 不再连接
近的判断标准(NetworkTopology.sortByDistance):
- 如果客户端和某个Datanode在同一台机器上, 优先
- 如果客户端和某个Datanode在同一个rack上, 次优先
- 否则随机
详情请参考下图:
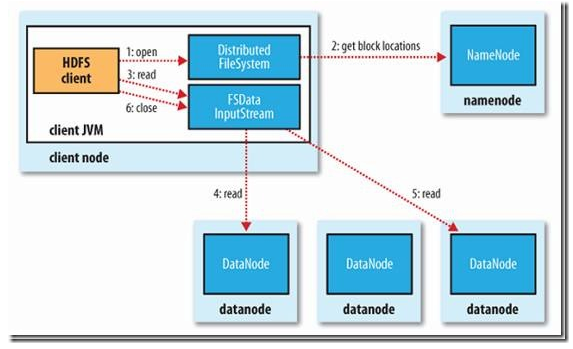
参考:
写入过程
流程
- 客户端通知NameNode创建目录
- 客户端开始写数据, 先写到本地, 然后定期分块
- 要写新块的时候再跟NameNode打交道, 获取到新块的目标地址
- 同一个数据块的不同副本是链式同步, 客户端只跟第一个副本打交道
- 只有所有副本都写入成功, 才开始下一个块的写操作
- 如果有一个写失败, 则:
- 失败的DataNode会加一个标记, 根据这个标记, 这份不完全的数据回头会被删除
- 不再往失败的DataNode上面写, 其他两个DataNode继续写
- 告诉NameNode这份数据副本数不足, NameNode回头会异步的补上
- 如果副本数少于某个配置(比如1个), 整个写入就算失败
详情参考下图:

副本分配策略
- 选择一个本地节点
- 选择一个本地机架节点
选择一个远程节点
- 随机选择一个节点
调整同步顺序(以节约带宽为目标)
参考: http://www.linuxidc.com/Linux/2012-01/50864.htm
如何感知机架位
通过NameNode的一个配置: topology.script.file.name 来控制的, 该配置的值对应一个脚本, 脚本输入是一个IP/字符串, 输出一个机架位名称, 该名称可以用"/xx/xx"的树形结构来表示网络拓扑。
如果没有配置该值, 则代表所有机器一个机架位, 会增加机器网络带宽消耗。
参考: http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html
HDFS Append文件逻辑
首先要说明两个概念, block和replica, 在NN中叫block, 在DN中叫replica。
block有四种状态:
- complete. block的长度和时间戳都不再变化, 并且至少有一个DN对应的rpelica是finalized的状态。
- under_construction. 文件被create和append的时候, 该block就处于under_construction的状态。该状态下文件是可以被读取的, 读取的长度是保证在所有的DN上副本都能读取到的长度;
- under_recovery. 如果一个文件的最后一个block在under_construction的状态时, client异常掉线了, 那么需要有一段时间的lease过期和恢复释放锁和关闭文件的过程, 这段时间之内该block处于under_recovery的状态.
- committed. 介于under_construction和complete之间的状态。client收到所有DN写成功的ARK, 但是NN还没有收到任何一个DN报replica已经finalized的状态。
replica状态要复杂一些:
- Finalized. 写完事儿之后的状态。
- rbw(replica being written). 类似under_construction, 在创建和写入过程中的replica。同under_construction, 也是可以被读取的;
- rwr(rpelica waiting recovry). 异常之后, 等待lease过期的状态;
- rur(replica under recovery). 异常之后, lease过期之后修复数据的状态;
- Temporary. 类似rbw, 但是不是正常写的状态, 是比如集群间balance的状态。跟rbw不同的是, 同步中的文件不可读;
参考: http://yanbohappy.sinaapp.com/?p=175
SecondaryNameNode机制
- SecondaryNameNode不是说NameNode挂了的备用节点
- 他的主要功能只是定期合并日志, 防止日志文件变得过大
- 合并过后的镜像文件在NameNode上也会保存一份
SecondaryNameNode工作过程:
- SecondaryNameNode向NameNode发起同步请求, 此时NameNode会将日志都写到新的日志当中
- SecondaryNameNode向NameNode下载镜像文件+日志文件
- SecondaryNameNode开始Merge这两份文件并生成新的镜像文件
- SecondaryNameNode向NameNode传回新的镜像文件
- NameNode文件将新的镜像文件和日志文件替换成当前正在使用的文件
详情请参考下图:
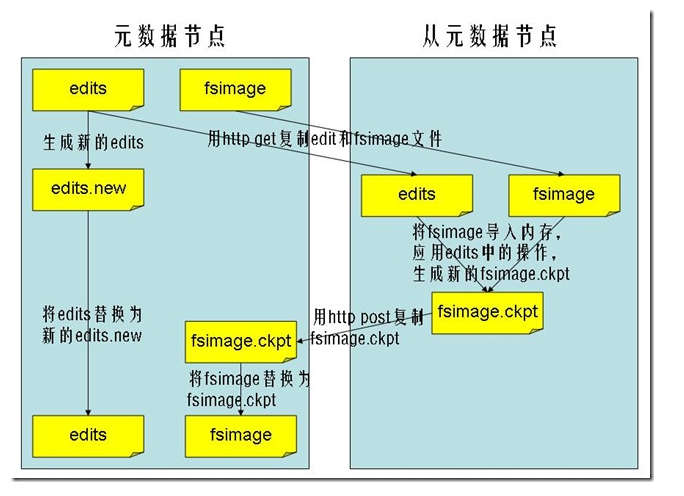
BackupNode机制
跟Mysql的Master-Slave机制类似, BackupNode是作为热备而存在, 同步更新NameNode节点的数据。
NameNode HA机制
NameNode数据主要包含两类:
map<filename, list<block_id>>即数据源信息这一类数据主要存储在两个文件中:
fsimg,editlog, 如上所说SecondaryNameNode的作用就是定期merge这两个文件。在HA机制中, 流程为将editlog写入一个共享存储, 一般为QJM(Quorum Journal Manager)节点, 一般为3个节点。active NN的editlog实时写入qjm节点, standby的NN定期从editlog中同步数据到自己的节点信息当中。
每次日志都有一个自增的epoch_id, jn会对比自己已有的epoch_id和NN给的epoch_id, 如果NN给的epoch_id比较小, 则会忽略该命令, 以此方式来达到避免脑裂问题。
NN通过ZKFC(ZooKeeper Fail Controller)来控制当前到底是哪个节点为ActiveNameNode, 在每个NN上都单独启动了一个ZKFC的进程, 该进程一方面监控NN的状态信息, 另一方面跟ZK保持连接说明自己的状态。类似租约, 一旦NN节点挂了, ZK会自动更新该节点状态信息, 同时通知另外的节点, 另外的节点就好接替前一个NN的工作。
map<block_id, list<DataNode>>即block_id和DataNode的对应关系这个本身信息是通过DataNode给NameNode上报来做到的, 增加了节点之后, DataNode跟每个NameNode都会上报一份信息。
类似qjm, DataNode也会维护一个自增的id, 当有NN切换的时候, 也会增加这个id, DN会拒绝比当前id还要小的控制命令。
HA的数据流图如下:
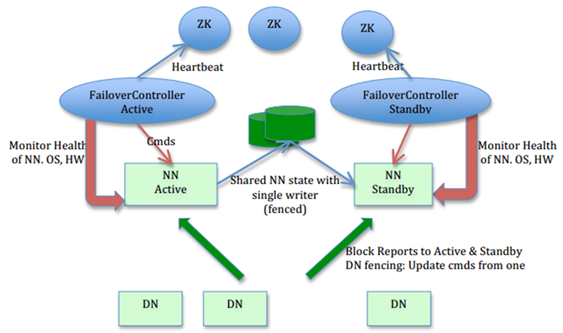
参考:
- 当前HDFS HA介绍. http://www.it165.net/admin/html/201407/3465.html
- HDFS HA进化论. http://www.bubuko.com/infodetail_124006.html
HDFS Federation
本身实现不复杂, 就是将原来所有信息都放在一个NameNode节点里, 变成了可以将NameNode信息拆分放到多个节点里, 一人分一个目录。
注意有一个block pool的概念, 为了避免在分配DataNode上的打架, 为每个NameNode分配了一个专属的block pool, 这样大家就分开了, 需要一开始配置自己的NameNode需要多少空间, 即Namespace Volume。
如下图:
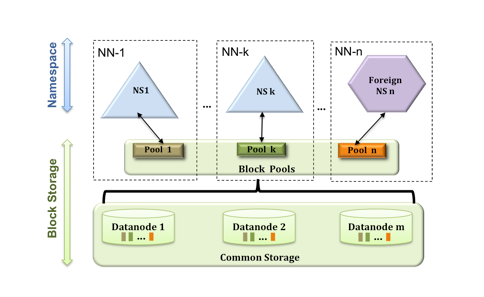
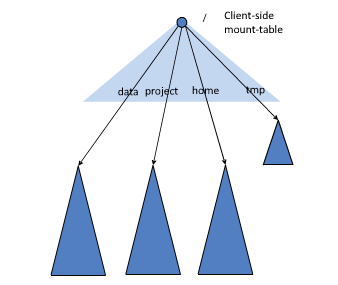
参考:
- http://zh.hortonworks.com/blog/an-introduction-to-hdfs-federation/
- http://blog.csdn.net/strongerbit/article/details/7013221/
- https://issues.apache.org/jira/secure/attachment/12453067/high-level-design.pdf
HDFS distcp
distcp1:
- 利用mapreduce来传输文件
为了保证文件内block的有序性, 所以map最小粒度为文件
问题出来了, 大文件会拖慢小文件, 导致整个拷贝效率不行
distcp2:
针对distcp1, 做了一些优化:
- 去掉了一些不必要的目录检查工作, 从而缩短了目录检查时间;
- 动态分配map task的工作量, 在运行过程中调整自己的任务量, 能优化部分distcp1的情况;
- 可对拷贝进行限速
- 支持HSFTP
fastcopy:
最主要是对federation机制的支持, 如果使用fastcp在同一个集群中不同的federation进行拷贝的时候, 则不需要再走一遍网络和删除, 只修改源数据即可, 但是distcp不行。
facebook的hadoop版本已经将fastcopy的这个特性集成到了distcp当中。
参考:
HDFS Balancer
是一个脚本, 该脚本做的事情很简单:
- 从NameNode获取DataNode数据分布信息
- 计算数据移动方案
- 执行移动方案
- 直到满足平衡要求
平衡要求是该脚本的一个输入(0~100), 代表不同机器的磁盘利用率差值。
注意:
- Balancer程序现在设计是不会将一个rack的数据移动到另外一个rack
- 也就是说跨rack的均衡是不能满足的, 除非有修改后的Balancer程序
- 一般不要将Balancer放到NameNode上运行
数据流图:
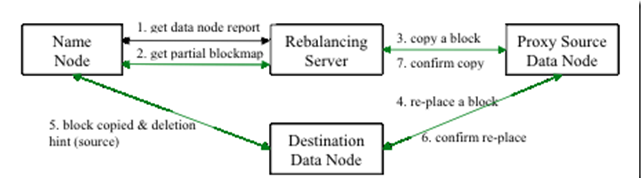
参考:
- balancer介绍. http://www.aboutyun.com/thread-7354-1-1.html
HDFS 快照
快照是给当前hdfs内容建立一个只读备份, 可以针对整个hdfs或者某个目录创建, 一般用于备份, 故障恢复, 避免人工故障等。
HDFS的快照有如下特点:
- 快照是瞬间创造的, 如果抛开inode的查询时间, 只需要O(1)
- 快照创建以后需要额外的内存来存储变化, 内存需要是O(M)
- 快照只是记录了block_list和文件大小信息, 不做任何的实际数据拷贝
- 快照不会影响到现在数据的增删改查, 查询快照的时候, 会根据当前结果以及记录的日志做减法来获取快照数据
HDFS NFSv3
就是在本地通过挂载NFS访问HDFS的文件
参考: http://blog.csdn.net/dmcpxy/article/details/18257065
HDFS dfsadmin
参考: http://blog.csdn.net/xiaojin21cen/article/details/42610697
hdfs 权限控制
认证:
支持两种方式, simple和kerberos, 通过hadoop.security.authentication这个类配置。默认是simple模式, simple模式下, 用户名为whoami, 组名为bash -c group
kerberos没有研究。
授权:
针对每个目录, 有读写一级可执行的权限设置, 权限有分为用户级别, 组级别, 以及其他。
同时也可以通过设置ACL来针对一个目录的某些用户设置特殊权限。
参考: http://demo.netfoucs.com/skywalker_only/article/details/40709447
代码阅读笔记
读取文件信息
客户端代码
- DFSClient.getFileInfo
- 到ClientProtocol类里查看getFileInfo
是接口, 用ctl+T查看其子类列表, 找到ClientNamenodeProtocolTranslatorPB类 - 再看ClientNamenodeProtocolTranslatorPB.getFileInfo函数
看到其调用了rpcProxy.getFileInfo类, 找rpcProxy的来源, 发现是构造函数传进来的, 所以用ctl+alt+H来找到其反向调用关系 - NameNodeProxies.createNNProxyWithClientProtocol函数
发现在该函数中调用了RPC.getProtocolProxy函数来获取该proxy, 在获得该proxy的时候传入了系列NN服务相关配置, 以及SocketFactory - 到RPC.getProtocolProxy函数
发现其是调用了getProtocolEngine(XX).getProxy(XX)的函数, 那么先看setProtocolEngine函数 - 到RPC.setProtocolEngine函数中看
发现其都设置的是RpcEngine的子类, 那么去看该RpcEngine的接口, 发现其实一个interface, 老办法, 用ctl+T看其子类, 找到ProtobufRpcEngine子类 - 找ProtobufRpcEngine.getProxy函数
发现其主要是使用了自己的一个Invoker的类, 该Invoker是一个动态代理类, 主要关注其invoke函数即可 - 看ProtobufRpcEngine.Invoker.invoke函数
该函数就是各种网络操作了, 可以看到他是将函数名拼成了一个字节流, 然后发给了NN, 然后hang住等待NN的返回结果
服务端代码
- ClientProtocol类是用来通信的类, 客户端和服务端都会用到, 直接看其子类即可
看到其子类有一个NameNodeRpcServer, 看起来肯定就是NN服务端这头的代码了 - NameNodeRpcServer.getFileInfo
发现其实调用了namesystem.getFileInfo函数 - namesystem.getFileInfo函数
一层一层往下面调用, 就可以找到其最终的逻辑了
NN启动代码
直接进入NameNode.main查看
- 参数获取和查看我们略过, 我们着重关注后面的逻辑
- createNameNode
调用了构造函数: NameNode(conf), conf已经根据argv参数初始化好了
该函数又调用了NameNode.initialize函数 - initialize(conf)
- 启动了http接口, 先启动http接口应该是说可以通过http接口来查看启动状态
- 调用loadNamesystem函数
- 该函数又调用了FSNamesystem.loadNamesystem函数
FSNamesystem就是非常重要的类了, 基本上所有的NN的核心数据结构都放在这个类里面了 - 主要关注该类的loadFSImage函数
- namenode.join()
参考文章
- hdfs流程简介. http://www.cnblogs.com/forfuture1978/archive/2010/03/14/1685351.html
- hdfs vs kfs. http://blog.csdn.net/Cloudeep/article/details/4467238
- hdfs的缺陷. http://www.cnblogs.com/wycg1984/archive/2010/03/20/1690281.html
- hdfs配置. http://cqfish.blog.51cto.com/622299/207766
- hdfs看分布式文件系统设计需求. http://dennis-zane.javaeye.com/blog/228537
- 利用Java API访问hdfs文件. http://blog.csdn.net/zhangzhaokun/article/details/5597433
- hdfs重大性能杀手——shell. http://blog.csdn.net/fly542/article/details/6819945
- DataNode的stale状态. http://www.tuicool.com/articles/RneQve
- hdfs源码阅读. http://www.linuxidc.com/Linux/2012-03/55966.htm
HDFS原理讲解的更多相关文章
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- OAuth的机制原理讲解及开发流程
本想前段时间就把自己通过QQ OAuth1.0.OAuth2.0协议进行验证而实现QQ登录的心得及Demo实例分享给大家,可一直很忙,今天抽点时间说下OAuth1.0协议原理,及讲解下QQ对于Oaut ...
- pureMVC简单示例及其原理讲解五(Facade)
本节将讲述Facade,Proxy.Mediator.Command的统一管家.自定义Facade必须继承Facade,在本示例中自定义Facade名称为ApplicationFacade,这个名称也 ...
- pureMVC简单示例及其原理讲解四(Controller层)
本节将讲述pureMVC示例中的Controller层. Controller层有以下文件组成: AddUserCommand.as DeleteUserCommand.as ModelPrepCom ...
- pureMVC简单示例及其原理讲解三(View层)
本篇说的是View层,即视图层,在本示例中包括两个部分:MXML文件,即可视控件:Mediator. 可视控件 可视控件由UserForm.mxml(图1)和UserList.mxml(图2)两个文件 ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
随机推荐
- 转载: Vim 练级攻略
转自:http://coolshell.cn/articles/5426.html 酷壳 vim的学习曲线相当的大(参看各种文本编辑器的学习曲线),所以,如果你一开始看到的是一大堆VIM的命令分类, ...
- bjfu1284 判别正则表达式
做解析器做得多的我,一上来就觉得要写解析器,麻烦,于是想偷懒用java的正则表达式类Pattern直接进行判断,结果wa了,原因是这题要求的正则表达式只是真正正则表达式的一个子集.比如|12是合法正则 ...
- 【LeetCode 160】Intersection of Two Linked Lists
Write a program to find the node at which the intersection of two singly linked lists begins. For ex ...
- Apriori学习笔记
Apriori算法是一种挖掘关联规则的频繁项集算法,是由Rakesh Agrawal和Ramakrishnan Srikant两位在1994年提出的布尔关联规则的频繁项集挖掘算法.算法的名字" ...
- 在这个年纪,打DOTA冲分有那么可笑么?
大学四年,毕业两年,6年dota,总是在最无助的时候让心灵得到一丝安宁的东西,烟和dota. 我不知道dota对别人的意义是什么,一盘dota,在最多不超过1个半小时的时间里,仿佛经历了一个小人生,每 ...
- Things App Engine Doesn't Do...Yet
当人们第一次使用App Engine的时候,他们会问一些App Engine不会做的事情.其中的一些事情Google在不久的将来会实现的,还有一些违背了App Engine设计的本质,将不可能增加(到 ...
- Codeforces 380 简要题解
ABC见上一篇. 感觉这场比赛很有数学气息. D: 显然必须要贴着之前的人坐下. 首先考虑没有限制的方案数.就是2n - 1(我们把1固定,其他的都只有两种方案,放完后长度为n) 我们发现对于一个限制 ...
- RabbitMQ (五)主题(Topic) -摘自网络
虽然使用direct类型改良了我们的系统,但是仍然存在一些局限性:它不能够基于多重条件进行路由选择. 在我们的日志系统中,我们有可能希望不仅根据日志的级别而且想根据日志的来源进行订阅.这个概念类似un ...
- 有关OOM KILLER的一些理解
Linux下有一种OOM KILLER 的机制,它会在系统内存耗尽的情况下,启用自己算法有选择性的kill 掉一些进程. 一.为什么会有OOM killer 当我们使用应用时,需要申请内存,即进行ma ...
- quartz 时间配置规则
quartz 时间配置规则 格式: [秒] [分] [小时] [日] [月] [周] [年] 序号 说明 是否必填 允许填写的值 允许的通配符 1 秒 是 0-59 , - * / ...