Flume与Kafka集成
一、Flume介绍
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
设计目标:
- 可靠性当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
- 可扩展性Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
- 可管理性所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
- 功能可扩展性用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
一般实时系统,所选用组件如下:
数据采集 :负责从各节点上实时采集数据,选用cloudera的flume来实现
数据接入 :由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,选用apache的kafka
流式计算 :对采集到的数据进行实时分析,选用apache的storm
数据输出 :对分析后的结果持久化,暂定用mysql ,另一方面是模块化之后,假如当Storm挂掉了之后,数据采集和数据接入还是继续在跑着,数据不会丢失,storm起来之后可以继续进行流式计算;
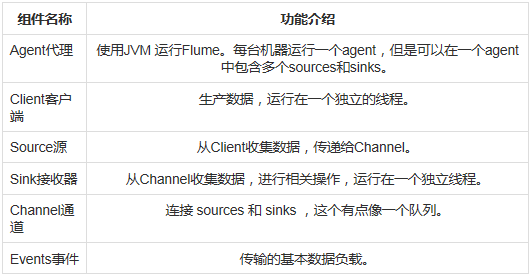
二、Flume 的 一些核心概念
其它参数配置请参见:http://itindex.net/detail/56260-flume-kafka-hdfs
http://www.jianshu.com/p/f0a08bd4f975
三、Flume的整体构成图
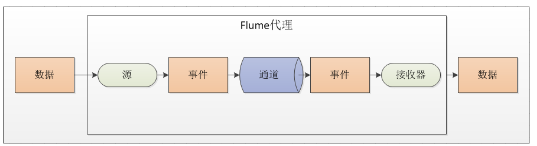
注意:(1)源将事件写到一个多或者多个通道中;(2)接收器只从一个通道接收事件;(3)代理可能会有多个源、通道与接收器。
四、常用配置模式
常用配置模式一:扫描指定文件
agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /Users/it-od-m/Downloads/abc.log
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100 #设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=127.0.0.1:9092
#设置Kafka的Topic
agent.sinks.k1.topic=testKJ1
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder agent.sinks.k1.channel=c1
常用配置模式二
Agent名称定义为agent.
Source:可以理解为输入端,定义名称为s1
channel:传输频道,定义为c1,设置为内存模式
sinks:可以理解为输出端,定义为sk1, agent.sources = s1
agent.channels = c1
agent.sinks = sk1 #设置Source的内省为netcat 端口为5678,使用的channel为c1
agent.sources.s1.type = netcat
agent.sources.s1.bind = localhost
agent.sources.s1.port = 3456
agent.sources.s1.channels = c1 #设置Sink为logger模式,使用的channel为c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1
#设置channel信息
agent.channels.c1.type = memory #内存模式
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100 #传输参数设置。
常用配置模式三:扫描目录新增文件
agent.sources = s1
agent.channels = c1
agent.sinks = sk1 #设置spooldir
agent.sources.s1.type = spooldir
agent.sources.s1.spoolDir = /Users/it-od-m/logs
agent.sources.s1.fileHeader = true agent.sources.s1.channels = c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1 #In Memory !!!
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10004
agent.channels.c1.transactionCapacity = 100
与Kafka结合时,通常采用第一种模式。
配置好参数以后,使用如下命令启动Flume:
./bin/flume-ng agent -n agent -c conf -f conf/hw.conf -Dflume.root.logger=INFO,console
最后一行显示Component type:SINK,name:k1 started表示启动成功.
说明:在启动Flume之前,Zookeeper和Kafka要先启动成功,不然启动Flume会报连不上Kafka的错误。
原文参见:http://www.jianshu.com/p/f0a08bd4f975
Flume与Kafka集成的更多相关文章
- 新闻实时分析系统-Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- 新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- Flume+HBase+Kafka集成与开发
先把flume1.7的源码包下载 http://archive.apache.org/dist/flume/1.7.0/ 下载解压后 我们通过IDEA这个软件来打开这个工程 点击ok后我们选择打开一个 ...
- flume+kafka+hbase+ELK
一.架构方案如下图: 二.各个组件的安装方案如下: 1).zookeeper+kafka http://www.cnblogs.com/super-d2/p/4534323.html 2)hbase ...
- 数据采集组件:Flume基础用法和Kafka集成
本文源码:GitHub || GitEE 一.Flume简介 1.基础描述 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中 ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- 使用Flume消费Kafka数据到HDFS
1.概述 对于数据的转发,Kafka是一个不错的选择.Kafka能够装载数据到消息队列,然后等待其他业务场景去消费这些数据,Kafka的应用接口API非常的丰富,支持各种存储介质,例如HDFS.HBa ...
- 纪录:Solr6.4.2+Flume1.7.0 +morphline+kafka集成
当前大多数企业版hadoop的solr版本都还停留在solr4.x,由于这个版本的solr本身的bug较多,使用起来会出很多奇怪的问题.如部分更新日期字段失败的问题. 最新的solr版本不仅修复了以前 ...
随机推荐
- 使用spring.net 1.3.2框架部署在虚拟目录上发生错误
如果你的网站使用了Spring.net 1.3.2,并部署在IIS的虚拟目录上,那么将会出现如下错误: The virtual path '/currentcontext.dummy' maps ...
- EasyMock使用手记
from:http://www.blogjava.net/supercrsky/articles/162766.html Mock 对象能够模拟领域对象的部分行为,并且能够检验运行结果是否和预期的一致 ...
- AP(应付帐管理)
--更新供应商地点 PROCEDURE update_vendor_site(p_init_msg_list IN VARCHAR2 DEFAULT fnd_api.g_false, x_return ...
- 使用 preferredStatusBarStyle 设置状态栏颜色
iOS9之前,在plist文件中 插入一个新的key,名字为View controller-based status bar appearance,并将其值设置为NO. 然后敲入代码: [UIAppl ...
- 【M5】对定制的“类型转换函数”保持警觉
1.隐式类型转换有两种情况:单个形参构造方法和隐式类型转换操作符.注意:隐式类型转换不是把A类型的对象a,转化为B类型的对象b,而是使用a对象构造出一个b对象,a对象并没有变化. 2.单个形参构造方法 ...
- progressBarButton
https://github.com/longtaoge/progressBarButton
- [MySQL登录错误] ERROR1045 (28000): Access denied for user 'omonroy'@'20.112.251.19' (using password:YES)
收到美国那边同事carl的call说用户登录不上去了,不过2个礼拜前他还用的好好的,他给我发email了,他有急事需要处理麻烦我记尽快协助,他在email有截取错误信息: root@xxxxx:/ho ...
- cocos2dx实例开发之flappybird(入门版)
cocos2dx社区里有个系列博客完整地复制原版flappybird的全部特性.只是那个代码写得比較复杂,新手学习起来有点捉摸不透,这里我写了个简单的版本号.演演示样例如以下: watermark/2 ...
- 提升GDI画图的效率
假设我们要画一个坐标图,里面可能还需要画网络线.XY各个单位的值.曲线或直线等,可能的函数代码如下: void OnPaint () { CPaintDC dc (this); DrawXY (&am ...
- VS环境下搭建自己NuGet服务器
一.NuGet服务端的搭建 环境:.NET 4.5 + VS2015 + NuGet.Server 2.10.1 1.建一个空的Web项目,取名叫NuGetServer 2.通过NuGet安装NuGe ...