新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具
1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压
2)通过idea导入flume源码
打开idea开发工具,选择File——》Open
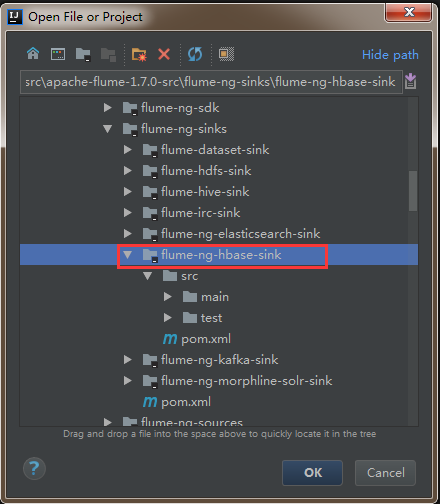
然后找到flume源码解压文件,选中flume-ng-hbase-sink,点击ok加载相应模块的源码。
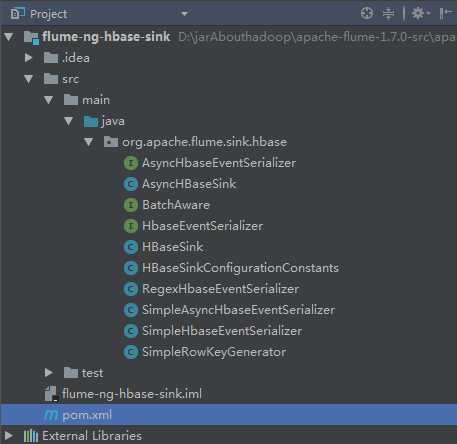
2.官方flume与hbase集成的参数介绍

3.下载日志数据并分析
到搜狗实验室下载用户查询日志
1)介绍
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。为进行中文搜索引擎用户行为分析的研究者提供基准研究语料
2)格式说明
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
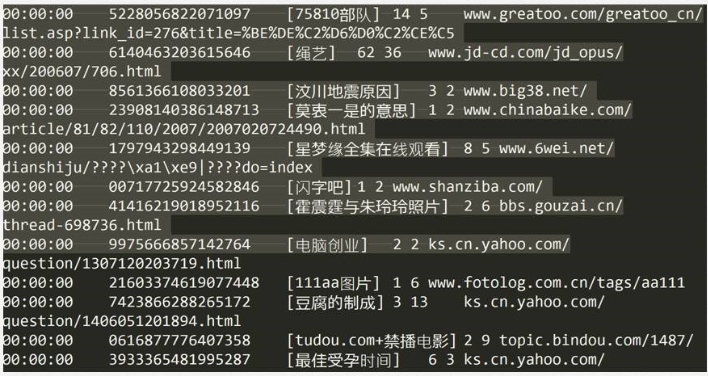
4.flume agent-3聚合节点与HBase集成的配置
vi flume-conf.properties
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC
agent1.sources.r1.bind = bigdata-pro01.kfk.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
5.对日志数据进行格式处理
1)将文件中的tab更换成逗号
cat weblog.log|tr "\t" "," > weblog2.log
2)将文件中的空格更换成逗号
cat weblog2.log|tr " " "," > weblog3.log
6.自定义SinkHBase程序设计与开发
1)模仿SimpleAsyncHbaseEventSerializer自定义KfkAsyncHbaseEventSerializer实现类,修改一下代码即可。
@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------代码修改开始---------------------------------*/
//解析列字段
String[] columns = new String(this.payloadColumn).split(",");
//解析flume采集过来的每行的值
String[] values = new String(this.payload).split(",");
for(int i=0;i < columns.length;i++){
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
//数据校验:字段和值是否对应
if(colColumn.length != colValue.length) break;
//时间
String datetime = values[0].toString();
//用户id
String userid = values[1].toString();
//根据业务自定义Rowkey
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userid,datetime);
//插入数据
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------代码修改结束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
2)在SimpleRowKeyGenerator类中,根据具体业务自定义Rowkey生成方法
/**
* 自定义Rowkey
* @param userid
* @param datetime
* @return
* @throws UnsupportedEncodingException
*/
public static byte[] getKfkRowKey(String userid,String datetime)throws UnsupportedEncodingException {
return (userid + datetime + String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}
7.自定义编译程序打jar包
1)在idea工具中,选择File——》ProjectStructrue
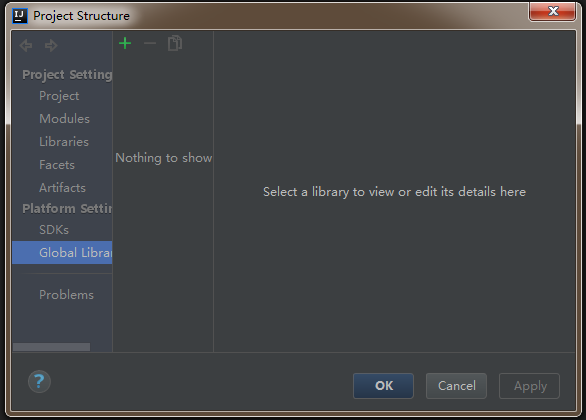
2)左侧选中Artifacts,然后点击右侧的+号,最后选择JAR——》From modules with dependencies
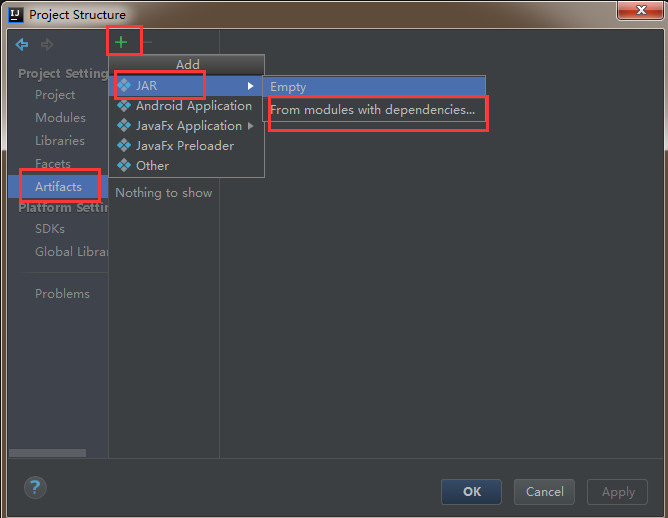
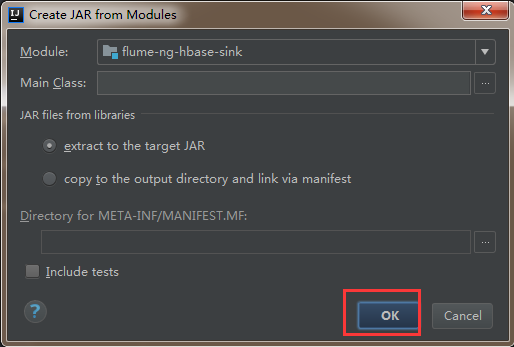
3)然后直接点击ok
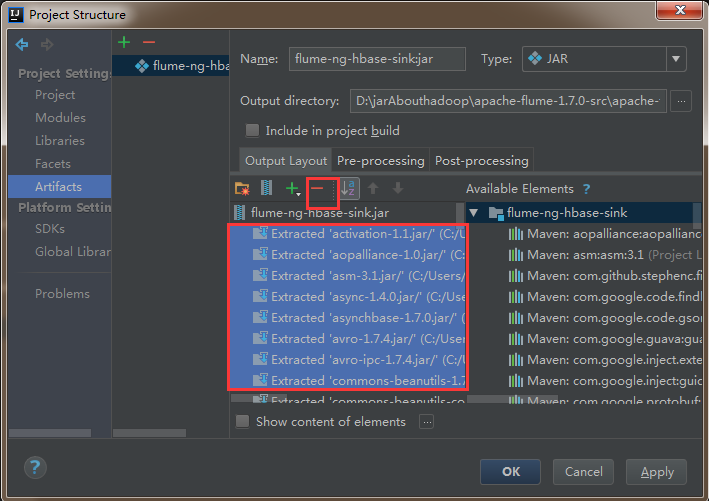
4)删除其他依赖包,只把flume-ng-hbase-sink打成jar包就可以了。
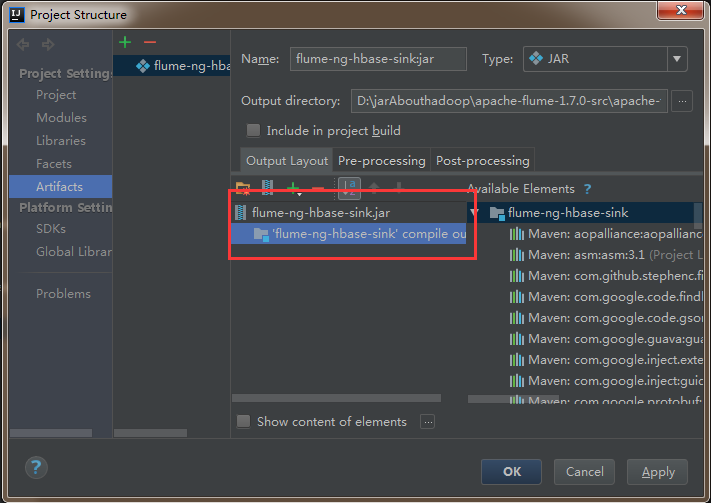
5)然后依次点击apply,ok
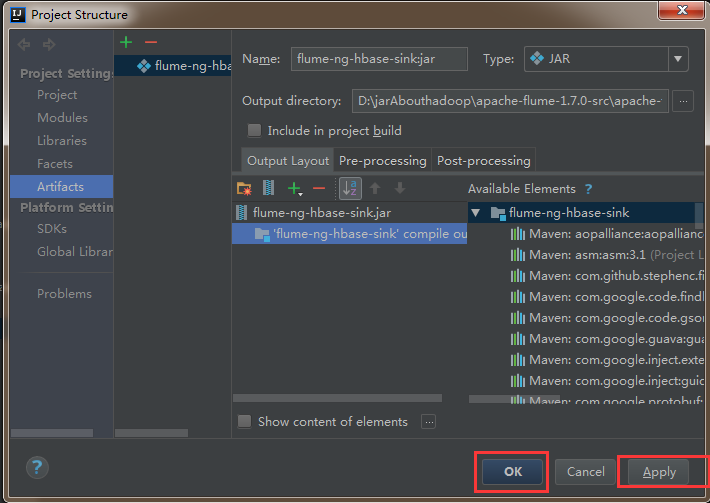
6)点击build进行编译,会自动打成jar包
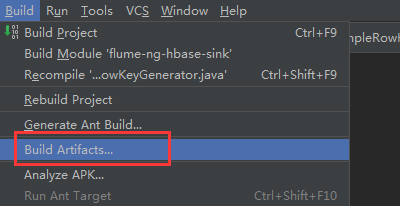
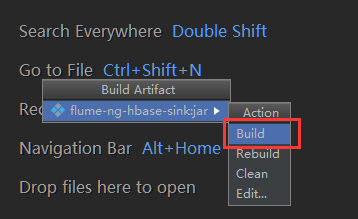
7)到项目的apache-flume-1.7.0-src\flume-ng-sinks\flume-ng-hbase-sink\classes\artifacts\flume_ng_hbase_sink_jar目录下找到刚刚打的jar包

8)将打包名字替换为flume自带的包名flume-ng-hbase-sink-1.7.0.jar ,然后上传至flume/lib目录下,覆盖原有的jar包即可。
8.flume聚合节点与Kafka集成的配置
vi flume-conf.properties
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC kafkaC
agent1.sources.r1.bind = bigdata-pro01.kfk.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
#*****************flume+Kafka***********************
agent1.channels.kafkaC.type = memory
agent1.channels.kafkaC.capacity = 100000
agent1.channels.kafkaC.transactionCapacity = 100000
agent1.channels.kafkaC.keep-alive = 20
agent1.sinks.kafkaSink.channel = kafkaC
agent1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkaSink.brokerList = bigdata-pro01.kfk.com:9092,bigdata-pro02.kfk.com:9092,bigdata-pro03.kfk.com:9092
agent1.sinks.kafkaSink.topic = test
agent1.sinks.kafkaSink.zookeeperConnect = bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181
agent1.sinks.kafkaSink.requiredAcks = 1
agent1.sinks.kafkaSink.batchSize = 1
agent1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder
新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发的更多相关文章
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
随机推荐
- win10中,vscode安装go插件排雷指南
最近学习go,想着使用强大的vscode编写go,在安装go插件过程中,遇到了很多问题.下面记录解决方案. 1)win10环境,安装go,vscode,git 配置GOPATH环境变量,在我的电脑-& ...
- Eclipse Tomcat 7.0 添加WEB项目报错:Tomcat version 7.0 only supports J2EE 1.2, 1.3, 1.4, and Java EE 5 and 6 Web modules
前言 我叫梅乾花,我误闯了“从零开始的程序世界”,遭受到了前所未有的的困难,为了活下去,为了看见美好的明天,我开始学习之旅. 问题篇我打开了"Eclipse",将项目导入其中,开启 ...
- springweb 详解。
spring web架构图 从图中可以看出, 如果要对输出的内容进行重构,不需要视图的话,在handlerMethodReturnValueHandler里进行操作,可以重构这个对象,以达到自定义输出 ...
- POJ-3821-Dining (拆点网络流)
这题为什么不能用 左边放食物,中间放牛,后面放水? 原因很简单,假设一头牛喜欢两个食物AB和两种水AB. 此时可以从一个食物A,走到牛A,再走到水A. 但是还可以有另一条路,从另一个食物B,走到该牛A ...
- stackADT
stack.h #ifndef STACK_H_INCLUDED #define STACK_H_INCLUDED #include <stdbool.h> typedef struct ...
- 加密设备NAT对IPSec的影响
加密设备NAT对IPSec VPN的影响:我们先配置好经典的IPSec VPN,然后在R3上做PAT看会对IPSec VPN产生什么影响(不会对有隧道的IPSec VPN技术产生影响). 现在默认配置 ...
- idea maven项目使用过程中遇到的问题
1. Error:Cannot build Artifact :war exploded because it is included into a circular depency 参考: http ...
- Update(stage3):第1节 redis组件:7、持久化
7.redis的持久化 由于redis是一个内存数据库,所有的数据都是保存在内存当中的,内存当中的数据极易丢失,所以redis的数据持久化就显得尤为重要,在redis当中,提供了两种数据持久化的方式, ...
- Android读取权限
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" /> <use ...
- 三年以上php开发经验常见面试题
01 一般有三年以上php开发经验去百度.腾讯面试,常会接触的面试题小总结一下: 02 0.简单做一下自我介绍,? 然后谈一下近三年来你的得意之作? 03 1.面试官看过你的简历,会问一些你做的项目 ...