scikit-learn中机器学习模型比较(逻辑回归与KNN)
本文源自于Kevin Markham 的模型评估:https://github.com/justmarkham/scikit-learn-videos/blob/master/05_model_evaluation.ipynb
- 我的监督学习应该使用哪一个模型
- 我的模型中应该选择那些调整参数
- 如何估计模型在样本数据外的表现
- 分类任务:预测未知鸢尾花的种类
- 用三个分类模型:KNN(K=1),KNN(K=5),逻辑回归
- 需要一个选择模型的方法:模型评估
1. 训练测试整个数据集
在整个数集上进行训练,然后用同一个数集进行测试,评估准确度。
1 from sklearn.datasets import load_iris
2 from sklearn.linear_model import LogisticRegression
3
4 # 1.read in the iris data
5 iris=load_iris()
6 X=iris.data
7 Y=iris.target
8 # print(X)
9 # print(Y)
10
11 # 2.logistic regression
12 logreg=LogisticRegression()
13 logreg.fit(X,Y)
14 y_pred=logreg.predict(X)
15 print(len(y_pred))


from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier # 1.read in the iris data
iris=load_iris()
X=iris.data
Y=iris.target
# print(X)
# print(Y) # 2.logistic regression
logreg=LogisticRegression(solver='liblinear',multi_class='ovr')
logreg.fit(X,Y)
y_logreg_pred=logreg.predict(X)
print(len(y_logreg_pred))
print(metrics.accuracy_score(Y,y_logreg_pred)) # 3.KNN=5
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(X,Y)
y_knn5_pred=knn.predict(X)
print(len(y_knn5_pred))
print(metrics.accuracy_score(Y,y_knn5_pred)) # 4.KNN=1
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X,Y)
y_knn1_pred=knn.predict(X)
print(len(y_knn1_pred))
print(metrics.accuracy_score(Y,y_knn1_pred))

 问题:
问题:- 目标是评测模型样本以外的数据表现
- 但是,最大化培训精度奖励过于复杂的模型,模型不能泛化
- 不必要的复杂模型过度拟合
2. 分开训练和测试集
将数据集一分为二,一部分用于训练,另一部分用于测试。
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split # 1.read in the iris data
iris=load_iris()
X=iris.data
Y=iris.target # 2.split X,Y
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.4,random_state=4)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape) # 3.logistic regression
logreg=LogisticRegression(solver='liblinear',multi_class='ovr')
logreg.fit(x_train,y_train)
y_logreg_pred=logreg.predict(x_test)
print(metrics.accuracy_score(y_test,y_logreg_pred)) # 3.KNN=5
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_knn5_pred=knn.predict(x_test)
print(metrics.accuracy_score(y_test,y_knn5_pred)) # 4.KNN=1
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train,y_train)
y_knn1_pred=knn.predict(x_test)
print(metrics.accuracy_score(y_test,y_knn1_pred))

import matplotlib.pyplot as plt
# print(k_range)
scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train,y_train)
y_knnk_pred=knn.predict(x_test)
scores.append(metrics.accuracy_score(y_test,y_knnk_pred))
plt.plot(k_range,scores)
plt.xlabel('value of k for KNN')
plt.ylabel('testing accurancy')
plt.show()
输出结果:
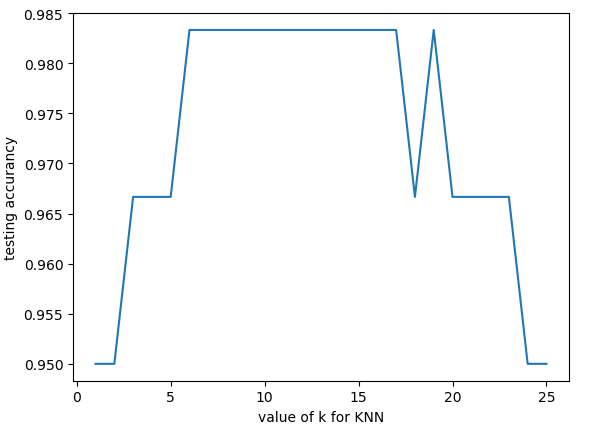
从上可以观察出k的取值对准确度的影响,k太小或太大都不是最佳值。
3. 预测
取k=11(7~16)。
# 6.predict
knn=KNeighborsClassifier(n_neighbors=11)
knn.fit(x_train,y_train)
y_pred=knn.predict([[3,5,4,2]])
print(y_pred)
输出结果:


4. 附注:
KNN算法:https://www.jianshu.com/p/48d391dab189
scikit-learn中机器学习模型比较(逻辑回归与KNN)的更多相关文章
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 机器学习总结之逻辑回归Logistic Regression
机器学习总结之逻辑回归Logistic Regression 逻辑回归logistic regression,虽然名字是回归,但是实际上它是处理分类问题的算法.简单的说回归问题和分类问题如下: 回归问 ...
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
原文链接:https://developers.google.com/machine-learning/crash-course/logistic-regression/ 逻辑回归会生成一个介于 0 ...
- 【机器学习基础】逻辑回归——LogisticRegression
LR算法作为一种比较经典的分类算法,在实际应用和面试中经常受到青睐,虽然在理论方面不是特别复杂,但LR所牵涉的知识点还是比较多的,同时与概率生成模型.神经网络都有着一定的联系,本节就针对这一算法及其所 ...
- PRML读书会第四章 Linear Models for Classification(贝叶斯marginalization、Fisher线性判别、感知机、概率生成和判别模型、逻辑回归)
主讲人 planktonli planktonli(1027753147) 19:52:28 现在我们就开始讲第四章,第四章的内容是关于 线性分类模型,主要内容有四点:1) Fisher准则的分类,以 ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Spark机器学习(2):逻辑回归算法
逻辑回归本质上也是一种线性回归,和普通线性回归不同的是,普通线性回归特征到结果输出的是连续值,而逻辑回归增加了一个函数g(z),能够把连续值映射到0或者1. MLLib的逻辑回归类有两个:Logist ...
- 使用SKlearn(Sci-Kit Learn)进行SVR模型学习
今天了解到sklearn这个库,简直太酷炫,一行代码完成机器学习. 贴一个自动生成数据,SVR进行数据拟合的代码,附带网格搜索(GridSearch, 帮助你选择合适的参数)以及模型保存.读取以及结果 ...
- 【Todo】用python进行机器学习数据模拟及逻辑回归实验
参考了这个网页:http://blog.csdn.net/han_xiaoyang/article/details/49123419 数据用了 https://pan.baidu.com/s/1pKx ...
随机推荐
- POJ1847 Tram
Tram Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 20274 Accepted: 7553 Description ...
- Power BI免费版(Free),专业版(Pro)以及增值版(Premium)授权功能对比, Server
Features of Power BI Report Server and the Power BI service Features Power BI Report Server Power BI ...
- Azure DevOps to Azure AppServices
Azure DevOps is a complete solution for software development, from planning to building to deploymen ...
- vscode的插件收集
转:https://zhuanlan.zhihu.com/p/27905838 转:https://segmentfault.com/a/1190000006697219
- Codeforces 1093D Beautiful Graph(二分图染色+计数)
题目链接:Beautiful Graph 题意:给定一张无向无权图,每个顶点可以赋值1,2,3,现要求相邻节点一奇一偶,求符合要求的图的个数. 题解:由于一奇一偶,需二分图判定,染色.判定失败,直接输 ...
- POJ2975 Nim 【博弈论】
DescriptionNim is a 2-player game featuring several piles of stones. Players alternate turns, and on ...
- 自定义滚动条样式-transition无效
问题 需求是自定义滚动条样式,然后2秒内无操作隐藏滚动条. 2s内隐藏比较麻烦,不能用css实现,只能监听容器的touch事件,然后给滚动条加个opacity: 0的class. .class::-w ...
- jQuery动态添加、删除按钮及input输入框
输入框的加减实现: <html> <head> <meta charset="utf-8"> <title>动态创建按钮</t ...
- 我的第一个微信小程序
今年国庆假期的时候,在家里带宝宝.想下载一个哄宝宝玩的游戏,从 App Store上搜索了一圈,发现评分高的基本上都是收费的.因为App Store上有限免机制,所以就萌发了做一款关注限免应用的小程序 ...
- js实现一个长页面中的图片懒加载即滚动到其位置才加载
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...