python提取网页表格并保存为csv
0.
1.参考
表格标签
| 表格 | 描述 |
|---|---|
| <table> | 定义表格 |
| <caption> | 定义表格标题。 |
| <th> | 定义表格的表头。 |
| <tr> | 定义表格的行。 |
| <td> | 定义表格单元。 |
| <thead> | 定义表格的页眉。 |
| <tbody> | 定义表格的主体。 |
| <tfoot> | 定义表格的页脚。 |
| <col> | 定义用于表格列的属性。 |
| <colgroup> | 定义表格列的组。 |
表格元素定位
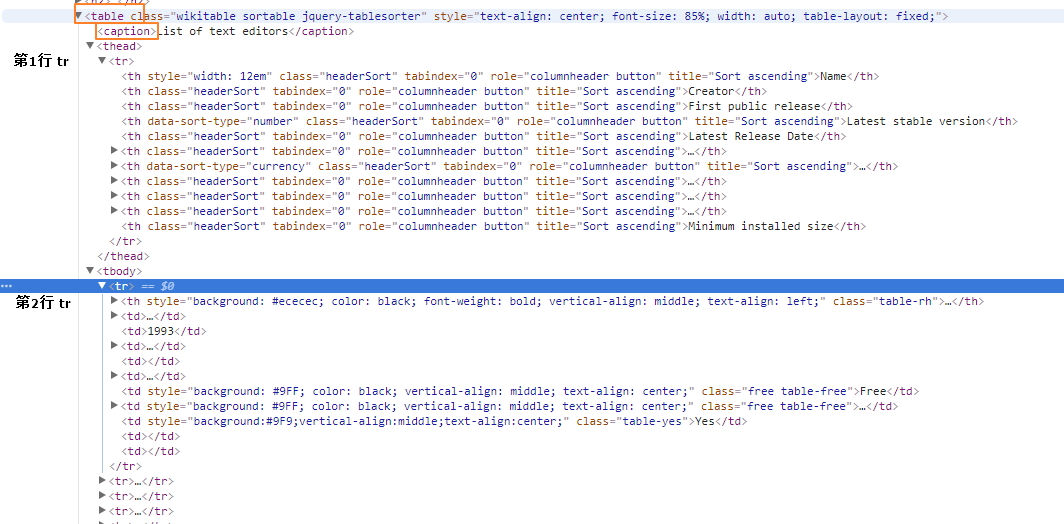
参看网页源代码并没有 thead 和 tbody。。。
<table class="wikitable sortable" style="text-align: center; font-size: 85%; width: auto; table-layout: fixed;">
<caption>List of text editors</caption>
<tr>
<th style="width: 12em">Name</th>
<th>Creator</th>
<th>First public release</th>
<th data-sort-type="number">Latest stable version</th>
<th>Latest Release Date</th>
<th><a href="/wiki/Programming_language" title="Programming language">Programming language</a></th>
<th data-sort-type="currency">Cost (<a href="/wiki/United_States_dollar" title="United States dollar">US$</a>)</th>
<th><a href="/wiki/Software_license" title="Software license">Software license</a></th>
<th><a href="/wiki/Free_and_open-source_software" title="Free and open-source software">Open source</a></th>
<th><a href="/wiki/Command-line_interface" title="Command-line interface">Cli available</a></th>
<th>Minimum installed size</th>
</tr>
<tr>
<th
2.提取表格数据
表格标题可能出现超链接,导致标题被拆分,
也可能不带表格标题。。
<caption>Text editor support for remote file editing over
<a href="/wiki/Lists_of_network_protocols" title="Lists of network protocols">network protocols</a>
</caption>
表格内容换行
<td>
<a href="/wiki/Plan_9_from_Bell_Labs" title="Plan 9 from Bell Labs">Plan 9</a>
and
<a href="/wiki/Inferno_(operating_system)" title="Inferno (operating system)">Inferno</a>
</td>
tag 规律
| table | ||||
| thead tr1 | th | th | th | th |
| tbody tr2 | td/th | td | ||
| tbody tr3 | td/th | |||
| tbody tr3 | td/th | |||
2.1提取所有表格标题列表
filenames = []
for index, table in enumerate(response.xpath('//table')):
caption = table.xpath('string(./caption)').extract_first() #提取caption tag里面的所有text,包括子节点内的和文本子节点,这样也行 caption = ''.join(table.xpath('./caption//text()').extract())
filename = str(index+1)+'_'+caption if caption else str(index+1) #xpath 要用到 table 计数,从[1]开始
filenames.append(re.sub(r'[^\w\s()]','',filename)) #移除特殊符号
In [233]: filenames
Out[233]:
[u'1_List of text editors',
u'2_Text editor support for various operating systems',
u'3_Available languages for the UI',
u'4_Text editor support for common document interfaces',
u'5_Text editor support for basic editing features',
u'6_Text editor support for programming features (see source code editor)',
u'7_Text editor support for other programming features',
'',
u'9_Text editor support for key bindings',
u'10_Text editor support for remote file editing over network protocols',
u'11_Text editor support for some of the most common character encodings',
u'12_Right to left (RTL) bidirectional (bidi) support',
u'13_Support for newline characters in line endings']
2.2每个表格分别写入csv文件
for index, filename in enumerate(filenames):
print filename
with open('%s.csv'%filename,'wb') as fp:
writer = csv.writer(fp)
for tr in response.xpath('//table[%s]/tr'%(index+1)):
writer.writerow([i.xpath('string(.)').extract_first().replace(u'\xa0', u' ').strip().encode('utf-8','replace') for i in tr.xpath('./*')]) #xpath组合,限定 tag 范围,tr.xpath('./th | ./td')
代码处理 .replace(u'\xa0', u' ')
HTML转义字符&npsp;表示non-breaking space,unicode编码为u'\xa0',超出gbk编码范围?
使用 'w' 写csv文件,会出现如下问题,使用'wb' 即可解决问题
【已解决】Python中通过csv的writerow输出的内容有多余的空行 – 在路上
所有表格写入同一excel文件的不同工作表 sheet,需要使用xlwt
python ︰ 创建 excel 工作簿和倾倒 csv 文件作为工作表
python提取网页表格并保存为csv的更多相关文章
- Python读取网页表格数据
学会了从网格爬取数据,就可以告别从网站一页一页复制表格数据的时代了. 说个亲身经历的事: 以前我的本科毕业论文是关于"燃放烟花爆竹和空气质量"之间关系的,就要从环保局官网查资料. ...
- python提取分析表格数据
#/bin/python3.4# -*- coding: utf-8 -*- import xlrd def open_excel(file="file.xls"): try: d ...
- python爬取昵称并保存为csv
代码: import sys import io import re sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') ...
- python爬取信息并保存至csv
import csv import requests from bs4 import BeautifulSoup res=requests.get('http://books.toscrape.com ...
- 使用python 提取网页的特定数据转
http://blog.csdn.net/nwpulei/article/details/7272832
- Python:提取网页中的电子邮箱
import requests, re #regex = r"([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)"#这个正则表达式过滤 ...
- Python使用Tabula提取PDF表格数据
今天遇到一个批量读取pdf文件中表格数据的需求,样式大体是以下这样: python读取PDF无非就是三种方式(我所了解的),pdfminer.pdf2htmlEX 和 Tabula.综合考虑后,选择了 ...
- python笔记之提取网页中的超链接
python笔记之提取网页中的超链接 对于提取网页中的超链接,先把网页内容读取出来,然后用beautifulsoup来解析是比较方便的.但是我发现一个问题,如果直接提取a标签的href,就会包含jav ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
随机推荐
- Vuex、axios、跨域请求处理和import/export的注意问题
一.Vuex 1.介绍 vuex是一个专门为Vue.js设计的集中式状态管理架构. 对于状态,我们把它理解为在data中需要共享给其他组件使用的部分数据. Vuex和单纯的全局对象有以下不同: 1. ...
- Codeforces Round #542 [Alex Lopashev Thanks-Round] (Div. 2)
A. Be Positive 题意:给出一个数组 每个树去除以d(d!=0)使得数组中大于0的数 大于ceil(n/2) 求任意d 思路:数据小 直接暴力就完事了 #include<bits/s ...
- Python3 与 C# 并发编程之~ 进程篇
上次说了很多Linux下进程相关知识,这边不再复述,下面来说说Python的并发编程,如有错误欢迎提出- 如果遇到听不懂的可以看上一次的文章:https://www.cnblogs.com/dot ...
- Zabbix通过JMX方式监控java中间件
Zabbix2.0添加了支持用于监控JMX应用程序的服务进程,称为“Zabbix-Java-gateway”:它是用java写的一个程序. 工作原理: zabbix_server想知道一台主机上的特定 ...
- ASP.NET知识点汇总
一 ,html属性20181113常用的居中方法1 text-align2 float3 margin (margin-left matgin-right margin-bottom margin-t ...
- 20175209 《Java程序设计》第二周学习总结
教材学习内容总结 二三章介绍的主要是Java中的基本知识:数据类型及转换,数据的输入输出,数组,运算符表达式,和常见的一些语句,这些都是帮助我们学习Java的基本知识,而这些知识很大一部分都和C语言相 ...
- hive笔记
cast cast(number as string), 可以将整数转成字符串 lpad rpad lpad(target, 10, '0') 表示在target字符串前面补0,构成一个长度为 ...
- 【.net】未在本地计算机上注册“microsoft.ACE.oledb.12.0”提供程序解决办法
#错误描述: 在开发.net项目中,通过microsoft.ACE.oledb读取excel文件信息时,报错: “未在本地计算机上注册“microsoft.ACE.oledb.12.0”提供程序” # ...
- MySQL实战45讲学习笔记:事务隔离级别(第三讲)
一.隔离性与隔离级别 1.事务的特性 原子性 一致性 隔离性 持久性 2.不同事务隔离级别的区别 读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到.读已提交:别人改数据的事务已经提交,我在我 ...
- CSS BFC(格式化上下文)深入理解
什么是BFC 在解释BFC之前,先说一下文档流.我们常说的文档流其实分为定位流.浮动流和普通流三种.而普通流其实就是指BFC中的FC.FC是formatting context的首字母缩写,直译过来是 ...