记intel杯比赛中各种bug与debug【其三】:intel chainer的安装与使用
现在在训练模型,闲着来写一篇
顺着这篇文章,顺利安装上intel chainer
再次感谢 大黄老鼠
intel chainer 使用
头一次使用chainer,本以为又入了一个大坑,实际尝试感觉非常兴奋
chainer的使用十分顺畅,开发起来特别友好
可能是跟pytorch相似的原因,特喜欢chainer
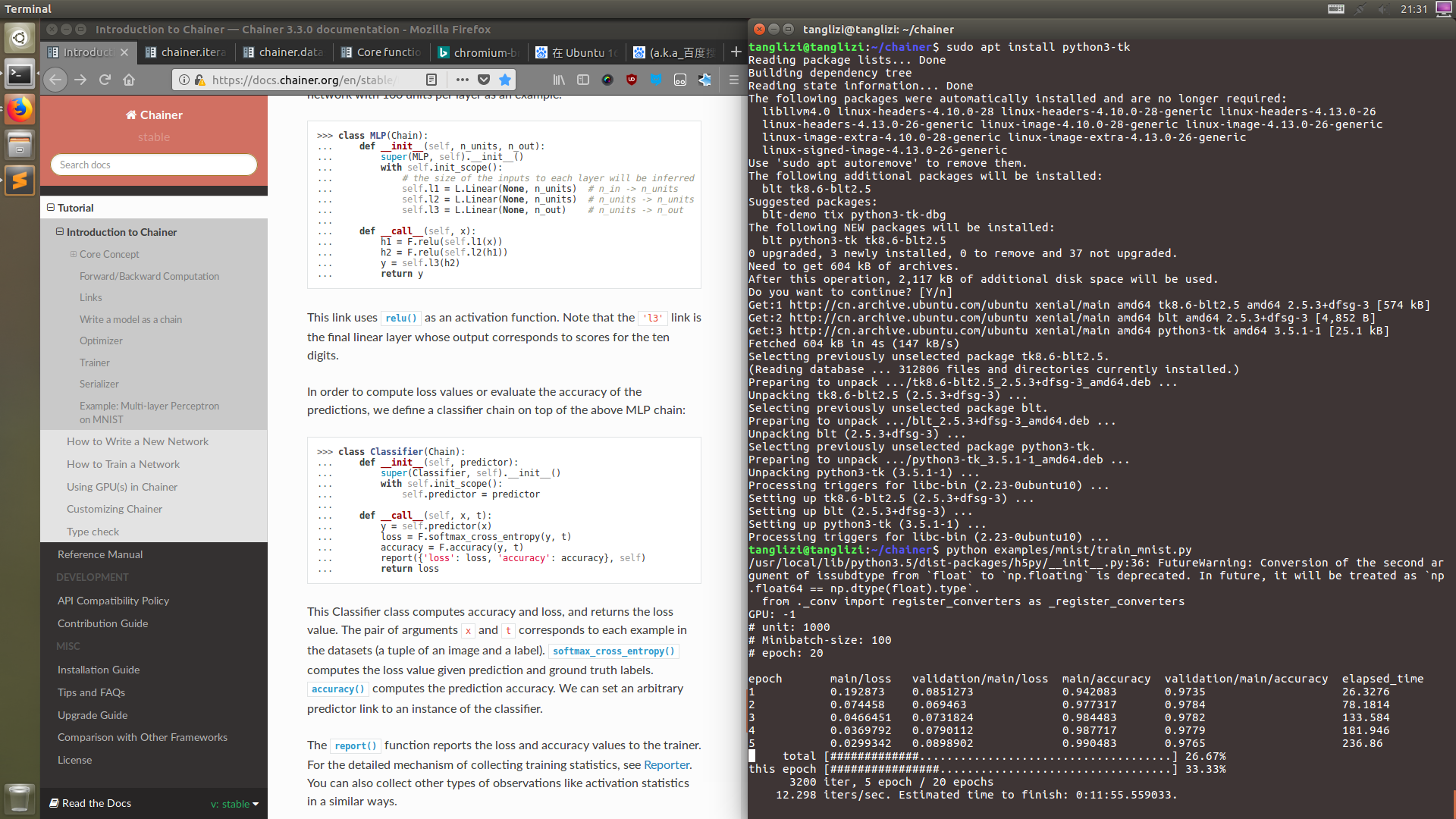
网络结构编写
这里如果用过pytorch,就会发现代码几乎没变,写起来就会非常顺手
在chainer中layers被视为links,Module被叫做Chain, chainer的意思由此可见
chainer的创新是突出了一个数据带领结构(“Define-by-Run”),所以就连layer的输入大小都不需要填写
模型会自动帮我们写
class Network(chainer.Chain):
def __init__(self):
super(Network, self).__init__()
with self.init__scope():
self.in=chainer.links.Linear(None, 256)
self.hidden=chainer.links.Linear(None, 64)
self.out=chainer.links.Linear(None, 5)
def __call__(self, x):
x=chainer.functions.relu(self.in(x))
x=chainer.functions.relu(self.hidden(x))
x=self.out(x)
return x
class Classifier(chainer.Chainer):
def __init__(self, predicor):
super(Classifier, self).__init__()
with self.init__scope():
self.predictor=predictor
def __call__(self, x, t):
x=self.predictor(x)
loss=chainer.functions.softmax_cross_entropy(x, t)
accuracy=chainer.functions.accuracy(x, t)
chainer.reporter.report({'loss': loss, 'accuracy': accuracy}, self)
return loss
训练模型
简要写一下chainer训练时要写什么
- model
- optimizer
- trainer(可选,需要updater和必要的参数)
- updater(以下皆可选, 需iterator, optimizer)
- iterator(需dataset,batch_size)
- dataset(类型为TupleDataset)
- extensions(需trainer)
我们把训练方式分为两种
- 一种为pytorch风格
定义好model, optimizer, criterion
嵌套循环,计算loss然后bp即可
def lossfun(data, label):
...
return loss
model=Network()
optimizer=chainer.optimizers.Adam()
optimizer.setup(model)
for epoch in params['epoch']:
for step, batch in enumerate(dataset):
model.cleargrads()
# model.reset_state()
loss=lossfun(batch['data'], batch['label'])
loss.backward()
optimizer.update()
或者简单写成
model=Network()
optimizer=chainer.optimizers.Adam()
optimizer.setup(model)
for epoch in params['epoch']:
for step, batch in enumerate(dataset):
# model.reset_state()
optimizer.update(lossfun, data, label)
- 另一种是带trainer的chainer风格
若有需要,重写updater和iterator,塞进trainer即可
若需要拓展,只需trainer.extend(...),十分方便
这里就简单的写一下
model=Classifier(Network())
optimizer=chainer.optimizers.Adam()
optimizer.setup(model)
trainset=chainer.datasets.TupleDataset(data, label)
train_iter=chainer.iterators.SerialIterator(trainset, params['batch_size'], shuffle=True, repeat=True)
updater=trainer.StandardUpdater(train_iter, model)
trainer=chainer.training.Trainer(updater, (params['epoch'], 'epoch'), params['name'])
# 这里是各种拓展
trainer.run()
使用模型
跟pytorch一样,十分简单
predict=model(data)
...
记intel杯比赛中各种bug与debug【其三】:intel chainer的安装与使用的更多相关文章
- 记intel杯比赛中各种bug与debug【其一】:安装intel caffe
因为intel杯创新软件比赛过程中,并没有任何记录.现在用一点时间把全过程重演一次用作记录. 学习 pytorch 一段时间后,intel比赛突然不让用 pytoch 了,于是打算转战intel ca ...
- 记intel杯比赛中各种bug与debug【其二】:intel caffe的使用和大坑
放弃使用pytorch,学习caffe 本文仅记录个人观点,不免存在许多错误 Caffe 学习 caffe模型生成需要如下步骤 编写network.prototxt 编写solver.prototxt ...
- 记intel杯比赛中各种bug与debug【其四】:基于长短时记忆神经网络的中文分词的实现
(标题长一点就能让外行人感觉到高大上) 直接切入主题好了,这个比赛还必须一个神经网络才可以 所以我们结合主题,打算写一个神经网络的中文分词 这里主要写一下数据的收集和处理,网络的设计,代码的编写和模型 ...
- 记intel杯比赛中各种bug与debug【其五】:朴素贝叶斯分类器的实现和针对性的优化
咱这个项目最主要的就是这个了 贝叶斯分类器用于做可以统计概率的二元分类 典型的例子就是垃圾邮件过滤 理论基础 对于贝叶斯算法,这里附上两个链接,便于理解: 朴素贝叶斯分类器的应用-阮一峰的网络日志 基 ...
- SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理
原文:SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理 SQL Server 字段类型 decimal(18,6)小数点前是几位? 不可否认,这是 ...
- gcc中的内嵌汇编语言(Intel i386平台)
[转]http://bbs.chinaunix.net/thread-2149855-1-1.html 一.声明 虽然Linux的核心代码大部分是用C语言编写的,但是不可避免的其中还是有一部分是用汇 ...
- 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过?
HTML5学堂 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过? IE6已经渐渐的开始退出浏览器的历史舞台.虽然当年IE6作为微软的一款利器击败网景,但之后也因为版本的持续不更新而被火狐和谷歌三 ...
- 转:移动开发中一些bug及解决方案
网页开发要面对各种各样的浏览器,让人很头疼,而移动开发中,你不但要面对浏览器,还要面对各种版本的手机,iOS好一点,而安卓就五花八门了,你可能在开发中也被它们折磨过,或者正在被它们折磨,我在这里说几个 ...
- 写代码的心得,怎么减少编程中的 bug?
遭遇 bug 的时候,理性的程序员会说:这个 bug 能复现吗? 自负型:这不可能,在我这是好好的. 经验型:不应该,以前怎么没问题? 幻想型:可能是数据有问题. 无辜型:我好几个星期都没碰这块代码了 ...
随机推荐
- Mysql表引擎的切换
转换MYSQL表的引擎 1.方法一:Alter table 将1个表的引擎修改为另一个引擎最简单的方法是使用Alter table语句. 下面的语句将myTable的引擎修改为InnoDB mysql ...
- HDU 1285 确定比赛名次【拓扑排序】
题意:中文的题目-----这道题让我终于明白了那个break的作用---因为题目中有这一句“符合条件的排名可能不是唯一的,此时要求输出时编号小的队伍在前”@_@ #include<iostrea ...
- swift语言点评十五-$0
import UIKitimport XCPlayground class ViewController: UIViewController { func action() { print(" ...
- Linxu基本指令
一.Linux权限的概念 Linux下有两种用户:普通用户和超级用户(). 普通用户:在linux下做有限的事情: 超级用户:可以在linux系统下做任何事情,不受限制. 普通用户的提示符是“$”,超 ...
- xampp、phpstudy安装phalcon
1.下载扩展 https://github.com/phalcon/cphalcon/releases/tag/v3.4.1选择PHP对应版本的phalcon扩展 2.PHP.ini 配置phalco ...
- caioj 1158 欧拉函数
直接套模板,这道题貌似单独求还快一些 解法一 #include<cstdio> #include<cctype> #define REP(i, a, b) for(int i ...
- WPF Toolkit AutoCompleteBox 实体类绑定 关键字自定义关联搜索匹配
原文:WPF Toolkit AutoCompleteBox 实体类绑定 关键字自定义关联搜索匹配 WPF Toolkit AutoCompleteBox 实体类绑定 关键字自定义关联搜索匹配 网上的 ...
- android获取自己定义控件位置坐标,屏幕尺寸,标题栏,状态栏高度
android获取自己定义控件位置坐标,屏幕尺寸,标题栏,状态栏高度 1.获取自己定义控件height 在本Activity中获取当前Activity中控件的height: Button button ...
- JAVA学习第二十七课(多线程(六))- 多生产者多消费者问题(JDK1.5新特性)
多生产者多消费者问题 以生产馒头 消费馒头为例. class Resource { private String name; private int count = 1; private boolea ...
- YII进行数据查询及类库追踪
一般处理过程: 模型进行数据操作,继承自CActiveRecord (活跃记录) AR数据库向上的封装.AR通过OOP面向对象方式操作数据库.AR须要终于转变为详细的sql语句.通过一个中间类(cri ...