Python爬虫实战教程:爬取网易新闻
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Amauri
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
此文属于入门级级别的爬虫,老司机们就不用看了。
本次主要是爬取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选的分类是国内新闻。然后鼠标右键点击查看源代码,发现源代码中并没有页面正中的新闻列表。这说明此网页采用的是异步的方式。也就是通过api接口获取的数据。
那么确认了之后可以使用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现了:"... special/00804KVA/cm_guonei_03.js? .... "之类的地址,点开Response发现正是我们要找的api接口。 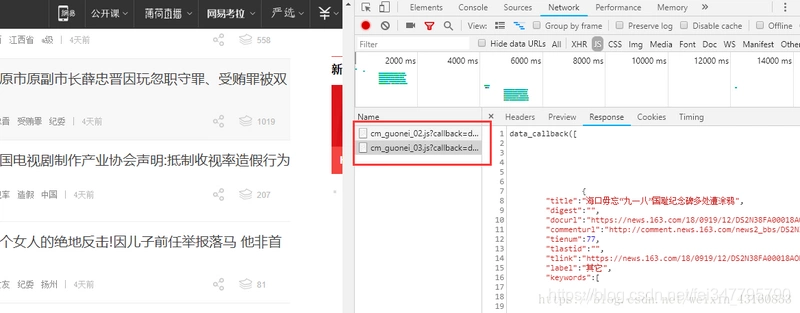
可以看到这些接口的地址都有一定的规律:“cm_guonei_03.js”、 “cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的连接也就是我们本次抓取所要请求的地址。
接下来只需要用到的python的两个库:
requests
json
BeautifulSoup
requests库就是用来进行网络请求的,说白了就是模拟浏览器来获取资源。
由于我们采集的是api接口,它的格式为json,所以要用到json库来解析。BeautifulSoup是用来解析html文档的,可以很方便的帮我们获取指定div的内容。
下面开始编写我们爬虫:
第一步先导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
接着我们定义一个获取指定页码内数据的方法:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样子就得到每个页码对应的内容列表:
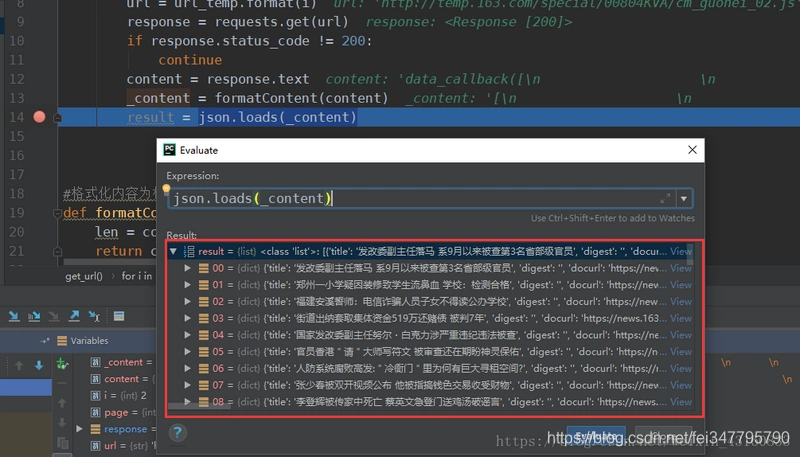
之后通过分析数据可知下图圈出来的则是需要抓取的标题、发布时间以及新闻内容页面。
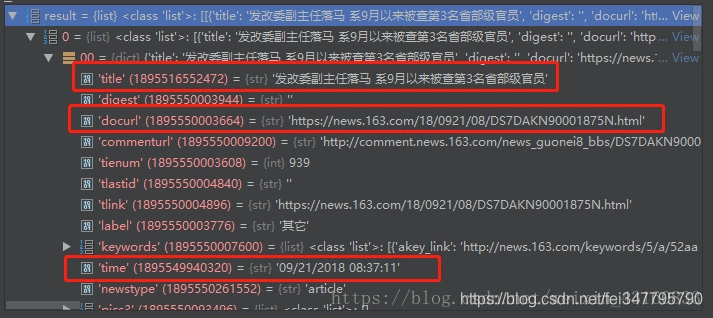
既然现在已经获取到了内容页的url,那么接下来开始抓取新闻正文。
在抓取正文之前要先分析一下正文的html页面,找到正文、作者、来源在html文档中的位置。
我们看到文章来源在文档中的位置为:id = "ne_article_source" 的 a 标签。 作者位置为:class = "ep-editor" 的 span 标签。 正文位置为:class = "post_text" 的 div 标签。
下面试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到此为止我们所要抓取的所有数据都已经采集了。
那么接下来当然是把它们保存下来,为了方便我直接采取文本的形式来保存。下面是最终的结果:

格式为json字符串,“标题” : [ ‘日期’, ‘url’, ‘来源’, ‘作者’, ‘正文’ ]。
要注意的是目前实现的方式是完全同步的,线性的方式,存在的问题就是采集会非常慢。主要延迟是在网络IO上,可以升级为异步IO,异步采集。
Python爬虫实战教程:爬取网易新闻的更多相关文章
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- python 爬虫实战4 爬取淘宝MM照片
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http:/ ...
- 芝麻HTTP:Python爬虫实战之爬取百度贴吧帖子
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 首先,我们先观察一下百度贴吧的任意一个帖子. 比如:http:// ...
随机推荐
- C++ 构造函数【新手必学】
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:可乐司机构造函数是C++里面的基础内容,特别重要,如果你刚学C++不久, ...
- MySql数据库之连接查询
在MySql数据库中连接查询分为以下几种方式: 1.内连接查询 内连接查询通过关键字 inner join 关键字来实现,通过代码实现: select * from 表1 inner join 表2 ...
- 【每天一题】LeetCode 0067. 二进制求和
开源地址:https://github.com/jiauzhang/algorithms 题目描述 * https://leetcode-cn.com/problems/add-binary * 给定 ...
- iOS 13 presentViewController
升级了iOS 13,发现代码中使用presentViewController的都变成了这样的,顶部留了一部分 查看present样式,iOS 13 默认自动适配,需要在present的时候,设置sty ...
- Crow’s Foot Notation
http://www2.cs.uregina.ca/~bernatja/crowsfoot.html Crow’s Foot Notation A number of data modeling te ...
- Mysql相关知识总结-持续更新~~~
2019-12-11对varchar类型排序问题的解决 在mysql默认order by 只对数字与日期类型可以排序,但对于varchar字符型类型排序好像没有用了,下面我来给各位同学介绍varcha ...
- Windows下安装和破解redis desktopmanager 2019.4
redis可视化客户端工具:redis desktop manager 破解版链接:https://www.52pojie.cn/thread-1042770-1-1.html redis deskt ...
- Ubuntu : apt 命令
apt 命令是一个功能强大的命令行工具,它不仅可以更新软件包列表索引.执行安装新软件包.升级现有软件包,还能够升级整个 Ubuntu 系统(apt 是 Debian 系操作系统的包管理工具).与更专业 ...
- 如果获取ruby的hash的v值?
最近写ruby,用到hash,通过k去获取v值,有时候通过hash["k"]去获取可以获取到,有时候通过又获取不到,感觉一脸懵逼 仔细观察了下ruby的hash,有两种表现形式,所 ...
- DataGridView右键菜单自定义显示及隐藏列
WinForm程序中表单的列可自定义显示及隐藏,是一种常见的功能,对于用户体验来说是非常好的.笔者经过一段时间的摸索,终于实现了自己想要的功能及效果,现记录一下过程: 1.新建一个自定义控件,命名为: ...