原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我
注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的。
爬虫目标网站:http://jandan.net/ooxx/ #如有侵权请联系我
代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib.request
import base64
import time url_a = 'http://jandan.net/ooxx/'#网站前一部分
need = '20200217-'#后一部分
need_a = 147#后一部分的后一部分 def base(word):#base64编码
outcome = base64.b64encode(word.encode("utf-8"))#编码后
url = url_a + outcome.decode('utf-8') + '#comments'
web(url) def web(url):
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
a = html.find('<img src="//')#从这个下标开始
i = 0#用来区别文件名
while a != -1:
b = html.find('.jpg',a,a+250)#到这个下标为止
if b != -1:
c = 'http://' + html[a+12:b+4]#图片网址
name = 'picture\\' + str(i) + str(need_a) + '.jpg'#文件名
get_jpg(c,name)
else:
b = a + 12
a = html.find('<img src="//',b)#循环查找
i += 1 def get_jpg(address,filename):
get = urllib.request.urlopen(address)#打开新网址
jpg = get.read()
with open(filename,'wb') as f:#写入图片
f.write(jpg)
print("Succeed!") while need_a >=100:#逐减
addition = need + str(need_a)
base(addition)
need_a -= 1
time.sleep(10)#停顿防止被反爬
效果图:
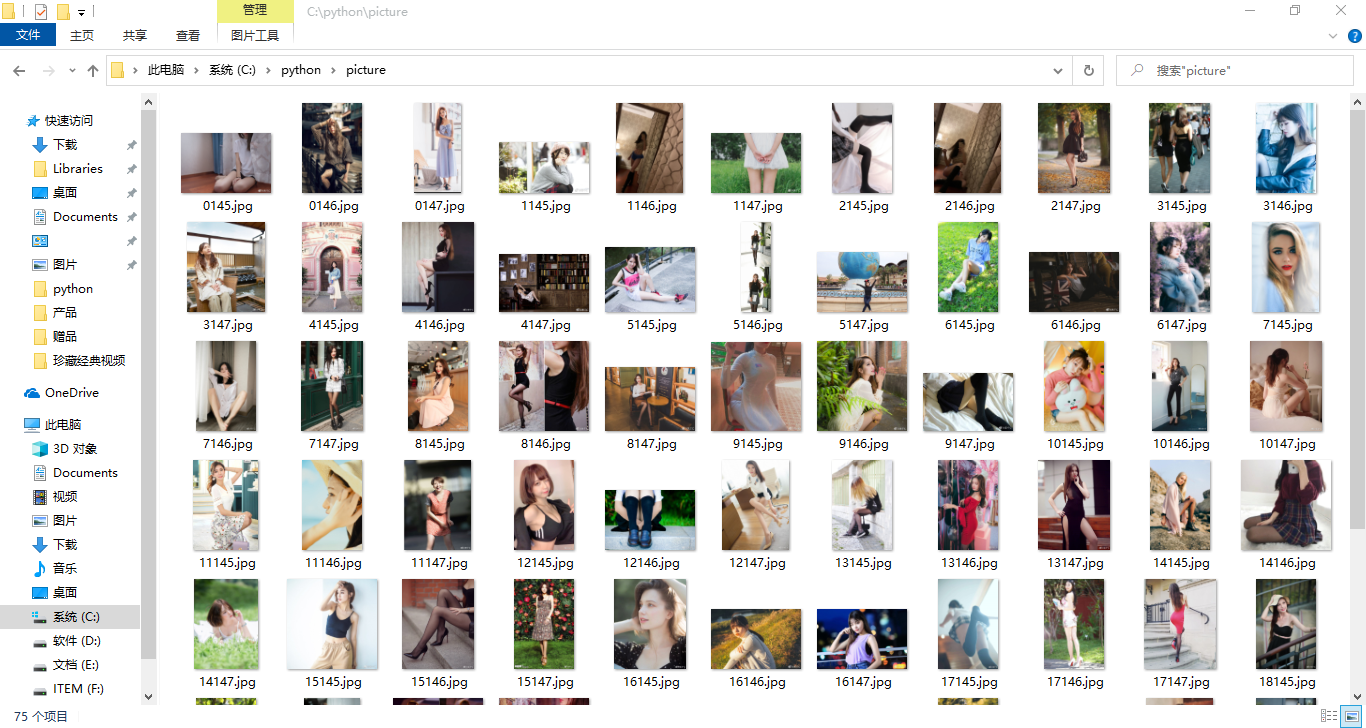
未经博主允许,不得转载
原创:Python爬虫实战之爬取美女照片的更多相关文章
- 原创:Python爬虫实战之爬取代理ip
编程的快乐只有在运行成功的那一刻才知道QAQ 目标网站:https://www.kuaidaili.com/free/inha/ #若有侵权请联系我 因为上面的代理都是http的所以没写这个判断 代 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- 芝麻HTTP:Python爬虫实战之爬取百度贴吧帖子
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 首先,我们先观察一下百度贴吧的任意一个帖子. 比如:http:// ...
随机推荐
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:循环神经网络预测正弦函数
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 定义RNN的参数. HIDDEN_SIZE = ...
- top 命令中的VIRT,RES,SHR ,MEM区别
VIRT 表示进程的虚拟(地址)空间大小,其包含进程实际使用的大小(申请的堆栈), 使用mmap映射的大小,包括外设RAM, 还有映射到本进程的文件(例如动态库),还有进程间的共享内存.所以VIRT ...
- Matlab高级教程_第二篇:关于MATLAB转C#过程中遇到输出两组参数的问题
1. 在matlab的m函数很可能遇到原函数[a,b] = func(a); 这样的两个输出参数. 2. 在观察C#生成后定义中我们发现: public MWArray HP(); public MW ...
- Nginx的下载与安装
.创建文件输入网页中需要复制的 cat >/etc/yum.repos.d/nginx.repo<<EOF [nginx-stable] name=nginx stable repo ...
- K3CLOUD表关联
销售订单关联发货通知单 销售订单表 T_SAL_ORDER A T_SAL_ORDERENTRY B T_SAL_ORDERENTRY_LK C 发货通知单表 T_SAL_DELIVERYNOTICE ...
- [LC] 541. Reverse String II
Given a string and an integer k, you need to reverse the first k characters for every 2k characters ...
- leetcode第38题:报数
这是一道简单题,但是我做了很久,主要难度在读题和理解题上. 思路:给定一个数字,返回这个数字报数数列.我们可以通过从1开始,不断扩展到n的数列.数列的值为前一个数列的count+num,所以我们不断叠 ...
- 总结verilog产生随机数的$random和seed
$random(seed)是verilog中最简单的产生随机数的系统函数. 在调用系统函数$random(seed)时,可以写成三种样式:1)$random,2)$random(),3)$rand ...
- android apk 文件反编译
最近,自己坑逼的把一个android 项目修改版本的代码删除了.这个项目居然还没上传到源代码管理器.幸好还有apk文件,修改的代码也不多可以反编译一下. 1.下载 dex2jar 获取源码工具 地 ...
- IPFS问题总结
1.安装包下载 ipfs安装版本下载:https://github.com/ipfs/go-ipfs/releases,这是IPFS的go语言实现版,目前实现的还有js版本. 2.安装与启动 linu ...