Scala 特质全面解析
要点如下:
- Scala中类只能继承一个超类, 可以扩展任意数量的特质
- 特质可以要求实现它们的类具备特定的字段, 方法和超类
- 与Java接口不同, Scala特质可以提供方法和字段的实现
- 当将多个特质叠加使用的时候, 顺序很重要
1. Scala类没有多继承
如果只是把毫不相关的类组装在一起, 多继承不会出现问题, 不过像下面这个简单例子就能让问题就浮出水面了;
class Student {
val id: Int = 10
}
class Teacher {
val id: Int = 100
}
假设可以有:
class TeacherAssistant extends Student, Teacher { ... }
要求返回id时, 该返回哪一个呢?
菱形继承
 

对于 class A 中的字段, class D 从 B 和 C 都得到了一份, 这两个字段怎么得到和被构造呢?
C++ 中通过虚拟基类解决它, 这是个脆弱而复杂的解决方法, Java设计者对这些复杂性心生畏惧, 采取了强硬的限制措施, 类只能继承一个超类, 能实现任意数量的接口.
同样, Scala 中类只能继承一个超类, 可以扩展任意数量的特质,与Java接口相比, Scala 的特质可以有具体方法和抽象方法; Java 的抽象基类中也有具体方法和抽象方法, 不过如果子类需要多个抽象基类的方法时, Java 就做不到了(没法多继承), Scala 中类可以扩展任意数量的特质.
2. 带有特质的类
2.1 当做接口使用的特质
- Scala可以完全像Java接口一样工作, 你不需要将抽象方法声明为 abstract, 特质中未被实现的方法默认就是抽象方法;
- 类可以通过 extends 关键字继承特质, 如果需要的特质不止一个, 通过 with 关键字添加额外特质
- 重写特质的抽象方法时, 不需要 override 关键字
- 所有 Java 接口都可以当做 Scala 特质使用
比起Java接口, 特质和类更为相似
trait Logger {
def log(msg: String) // 抽象方法
}
class ConsoleLogger extends Logger with Serializable { // 使用extends
def log(msg: String): Unit = { // 不需要override关键字
println("ConsoleLogger: " + msg)
}
}
object LoggerTest extends App{
val logger = new ConsoleLogger
logger.log("hi")
}
/*输出
ConsoleLogger: hi
*/
2.2 带有具体实现的特质
trait Logger {
def log(msg: String) // 抽象方法
def printAny(k: Any) { // 具体方法
println("具体实现")
}
}
让特质混有具体行为有一个弊端. 当特质改变时, 所有混入该特质的类都必须重新编译.
2.3 继承类的特质
特质继承另一特质是一种常见的用法, 而特质继承类却不常见.
特质继承类, 这个类会自动成为所有混入该特质的超类
trait Logger extends Exception { }
class Mylogger extends Logger { } // Exception 自动成为 Mylogger 的超类
如果我们的类已经继承了另一个类怎么办?
没关系只要这个类是特质超类的子类就好了;
//IOException 是 Exception 的子类
class Mylogger extends IOException with Logger { }
不过如果我们的类继承了一个和特质超类不相关的类, 那么这个类就没法混入这个特质了.
3. 带有特质的对象
在构造单个对象时, 你可以为它添加特质;
特质可以将对象原本没有的方法与字段加入对象中
如果特质和对象改写了同一超类的方法, 则排在右边的先被执行.
// Feline 猫科动物
abstract class Feline {
def say()
}
trait Tiger extends Feline {
// 在特质中重写抽象方法, 需要在方法前添加 abstract override 2个关键字
abstract override def say() = println("嗷嗷嗷")
def king() = println("I'm king of here")
}
class Cat extends Feline {
override def say() = println("喵喵喵")
}
object Test extends App {
val feline = new Cat with Tiger
feline.say // Cat 和 Tiger 都与 say 方法, 调用时从右往左调用, 是 Tiger 在叫
feline.king // 可以看到即使没有 cat 中没有 king 方法, Tiger 特质也能将自己的方法混入 Cat 中
}
/*output
嗷嗷嗷
I'm king of here
*/
4. 特质的叠加
可以为类和对象添加多个相互调用的特质 时, 从最后一个开始调用. 这对于需要分阶段加工处理某个值的场景很有用.
下面展示一个char数组的例子, 展示混入的顺序很重要
定义一个抽象类CharBuffer, 提供两种方法
- put 在数组中加入字符
- get 从数组头部取出字符
abstract class CharBuffer {
def get: Char
def put(c: Char)
}
class Overlay extends CharBuffer{
val buf = new ArrayBuffer[Char]
override def get: Char = {
if (buf.length != 0) buf(0) else '@'
}
override def put(c: Char): Unit = {
buf.append(c)
}
}
定义两种对输入字符进行操作的特质:
- ToUpper 将输入字符变为大写
- ToLower 将输入字符变为小写
因为上面两个特质改变了原始队列类的行为而并非定义了全新的队列类, 所以这2种特质是可堆叠的,你可以选择它们混入类中,获得所需改动的全新的类。
trait ToUpper extends CharBuffer {
// 特质中重写抽象方法 abstract override
abstract override def put(c: Char) = super.put(c.toUpper)
// abstract override def put(c: Char): Unit = put(c.toUpper)
// java.lang.StackOverflowError, 由于put相当于 this.put, 在特质层级中一直调用自己, 死循环
}
trait ToLower extends CharBuffer {
abstract override def put(c: Char) = super.put(c.toLower)
}
特质中 super 的含义和类中 super 含义并不相同, 如果具有相同含义, 这里super.put调用时超类的 put 方法, 它是一个抽象方法, 则会报错, 下面会详细介绍 super.put 的含义
测试
object TestOverlay extends App {
val cb1 = new Overlay with ToLower with ToUpper
val cb2 = new Overlay with ToUpper with ToLower
cb1.put('A')
println(cb1.get)
cb2.put('a')
println(cb2.get)
}
/*output
a
A
*/
上面代码的一些说明:
上面的特质继承了超类charBuffer, 意味着这两个特质只能混入继承了charBuffer的类中
上面每一个
put方法都将修改过的消息传递给super.put, 对于特质来说, super.put 调用的是特质层级的下一个特质(下面说), 具体是哪一个根据特质添加的顺序来决定. 一般来说, 特质从最后一个开始被处理.在特质中,由于继承的是抽象类,super调用时非法的。这里必须使用abstract override 这两个关键字,在这里表示特质要求它们混入的对象(或者实现它们的类)具备 put 的具体实现, 这种定义仅在特质定义中使用。
混入的顺序很重要,越靠近右侧的特质越先起作用。当你调用带混入的类的方法时,最右侧特质的方法首先被调用。如果那个方法调用了super,它调用其左侧特质的方法,以此类推。
如果要控制具体哪个特质的方法被调用, 则可以在方括号中给出名称: super[超类].put(...), 这里给出的必须是直接超类型, 无法使用继承层级中更远的特质或者类; 不过在本例中不行, 由于两个特质的超类是抽象类, 没有具体方法, 编译器报错
5. 特质的构造顺序
特质也可以有构造器,由字段的初始化和其他特质体中的语句构成。这些语句在任何混入该特质的对象在构造时都会被执行。
构造器的执行顺序:
- 调用超类的构造器;
- 特质构造器在超类构造器之后、类构造器之前执行;
- 特质由左到右被构造;
- 每个特质当中,父特质先被构造;
- 如果多个特质共有一个父特质,父特质不会被重复构造
- 所有特质被构造完毕,子类被构造。
线性化细节
- 线性化是描述某个类型的所有超类型的一种技术规格;
- 构造器的顺序是线性化顺序的反向;
- 线性化给出了在特质中super被解析的顺序,
如果 C extends c1 with c2 with c3, 则:
lin(C) = C >> lin(c3) >> lin(c2) >> lin(c1)
这里>>意思是 "串接并去掉重复项, 右侧胜出"
下面例子中:
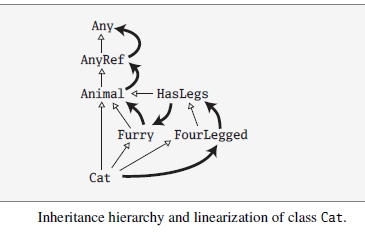
class Cat extends Animal with Furry with FourLegged
lin(Cat) = Cat>>lin(FourLegged)>>lin(Furry)>>lin(Animal)
= Cat>>(FourLegged>>HasLegs)>>(Furry>>Animal)>>(Animal)
= Cat>>FourLegged>>HasLegs>>Furry>>Animal
线性化给出了在特质中super被解析的顺序, 举例来说就是
FourLegged中调用super会执行HasLegs的方法
HasLegs中调用super会执行Furry的方法
例子
Scala 的线性化的主要属性可以用下面的例子演示:假设你有一个类 Cat,继承自超类 Animal 以及两个特质 Furry 和 FourLegged。 FourLegged 又扩展了另一个特质 HasLegs:
class Animal
trait Furry extends Animal
trait HasLegs extends Animal
trait FourLegged extends HasLegs
class Cat extends Animal with Furry with FourLegged
类 Cat 的继承层级和线性化次序展示在下图。继承次序使用传统的 UML 标注指明:白色箭头表明继承,箭头指向超类型。黑色箭头说明线性化次序,箭头指向 super 调用解决的方向。

6. 特质中的字段
特质中的字段可以是具体的也可以是抽象的. 如果给出了初始值那么字段就是具体的.
6.1 具体字段
trait Ability {
val run = "running" // 具体字段
def log(msg: String) = {}
}
class Cat extends Ability {
val name = "cat"
}
1.混入Ability特质的类自动获得一个run字段.
2.通常对于特质中每一个具体字段, 使用该特质的类都会获得一个字段与之对应.
3.这些字段不是被继承的, 他们只是简单的加到了子类中.任何通过这种方式被混入的字段都会自动成为该类自己的字段, 这是个细微的区别, 却很重要
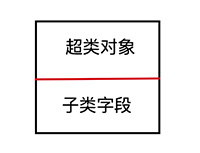 

JVM中, 一个类只能继承一个超类, 因此来自特质的字段不能以相同的方式继承. 由于这个限制, run 被直接加到Cat类中, 和name字段排在子类字段中.
6.2 初始化特质抽象字段
在类中初始化
特质中未被初始化的字段在具体的子类中必须被重写
trait Ability {
val swim: String // 具体字段
def ability(msg: String) = println(msg + swim) // 方法用了swim字段
}
class Cat extends Ability {
val swim = "swimming" // 不需要 override
}
这种提供特质参数的方式在零时构造某种对象很有利, 很灵活,按需定制.
创建对象时初始化
特质不能有构造器参数. 每个特质都有一个无参构造器. 值得一提的是, 缺少构造器参数是特质与类唯一不相同的技术差别. 除此之外, 特质可以具有类的所有特性, 比如具体的和抽象的字段, 以及超类.
这种局限对于那些需要定制才有用的特质来说会是一个问题, 这个问题具体就表现在一个带有特质的对象身上. 我们先来看下面的代码, 然后在分析一下, 就能一目了然了.
/**
* Created by wangbin on 2017/7/11.
*/
trait Fruit {
val name: String
// 由于是字段, 构造时就输出
val valPrint = println("valPrint: " + name)
// lazy 定义法, 由于是lazy字段, 第一次使用时输出
lazy val lazyPrint = println("lazyPrint: " + name)
// def 定义法, 方法, 每次调用时输出
def defPrint = println("defPrint: " + name)
}
object TestFruit extends App {
// 方法1. lazy定义法
println("** lazy定义法 构造输出 **")
val apple1 = new Fruit {
val name = "Apple"
}
println("\n** lazy定义法 调用输出 **")
apple1.lazyPrint
apple1.defPrint
// 方法2. 提前定义法
println("\n** 提前定义法 构造输出 **")
val apple2= new {
val name = "Apple"
} with Fruit
println("\n** 提前定义法 调用输出 **")
apple2.lazyPrint
apple2.defPrint
}
/*
** lazy定义法 构造输出 **
valPrint: null
** lazy定义法 调用输出 **
lazyPrint: Apple
defPrint: Apple
** 提前定义法 构造输出 **
valPrint: Apple
** 提前定义法 调用输出 **
lazyPrint: Apple
defPrint: Apple
*/
为了便于观察, 先把输出整理成表格
| 方法 | valPrint | lazyPrint | defPrint |
|---|---|---|---|
| lazy定义法 | null | Apple | Apple |
| 提前定义法 | Apple | Apple | Apple |
我们先来看一下 lazy定义法 和 提前定义法 的构造输出, 即 valPrint, lazy定义法输出为 null, 提前定义法输出为 "Apple"; 问题出在构造顺序上, Fruit 构造器(特质的构造顺序)先与子类构造器执行. 这里的子类并不那么明显, new 语句构造的其实是一个 Fruit 的匿名子类的实例. 也就是说 Fruit 先初始化, 子类的 name 还没来得及初始化, Fruit 的 valPrint 在构造时就立即求值了, 所以输出为 null.
由于lazy值每次使用都会检查是否已经初始化, 用起来并不是那么高效.
关于 val, lazy val, def 的关系可以看看 lazy
特质背后的实现: Scala通过将 trait 翻译成 JVM 的类和接口 , 关于通过反编译的方式查看 Scala 特质的背后工作方式可以参照 Scala 令人着迷的类设计中介绍的方法, 有兴趣的可以看看.
参考:
- 特质与特质线性化 Jason Ding
Scala 特质全面解析的更多相关文章
- scala特质
package com.ming.test /** * scala 特质,类似与java接口,但是比java接口强大,可以有实现方法,定义字段之类的 */ /** * 定义一个日志的特质 */ tra ...
- Scala词法文法解析器 (二)分析C++类的声明
最近一直在学习Scala语言,偶然发现其Parser模块功能强大,乃为BNF而设计.啥是BNF,读大学的时候在课本上见过,那时候只觉得这个东西太深奥.没想到所有的计算机语言都是基于BNF而定义的一套规 ...
- Scala词法文法解析器 (一)解析SparkSQL的BNF文法
平台公式及翻译后的SparkSQL 平台公式的样子如下所示: if (XX1_m001[D003]="邢おb7肮α䵵薇" || XX1_m001[H003]<"2& ...
- scala akka 修炼之路5(scala特质应用场景分析)
scala中特质定义:包括一些字段,行为(方法/函数/动作)和一些未实现的功能接口的集合,能够方便的实现扩展或混入到已有类或抽象类中. scala中特质(trait)是一个非常实用的特性,在程序设计中 ...
- 8.scala:特质
版权申明:转载请注明出处.文章来源:http://bigdataer.net/?p=317 总体来说,scala中的特质类似于Java中的接口,但是有别于接口的是特质中既可以有实现方法也可以有抽象方法 ...
- Scala集合常用方法解析
Java 集合 : 数据的容器,可以在内部容纳数据 List : 有序,可重复的 Set : 无序,不可重复 Map : 无序,存储K-V键值对,key不可重复 scala 集合 : 可变集合( ...
- scala模式匹配详细解析
一.scala模式匹配(pattern matching) pattern matching可以说是scala中十分强大的一个语言特性,当然这不是scala独有的,但这不妨碍它成为scala的语言的一 ...
- scala 特质的应用
一.为类提供可以堆叠的改变 package com.jason.qianfeng trait Loggertest { def logger(msg: String) } trait ConsoleL ...
- scala通过尾递归解析提取字段信息
一.背景 获取数据中以“|”作为字段间的分隔符,但个别字段中数据也是以“|”作为分隔符.因此,在字段提取时需要保护数据完整性. 二.实现 1.数据以“|”分隔,可以采用递归方式迭代解析.通过尾递归方式 ...
随机推荐
- httprouter使用pprof
httprouter使用pprof 参考:https://github.com/feixiao/httpprof 性能分析参考:https://github.com/caibirdme/hand-to ...
- 【MSSQL】SQL Server的日期和时间类型
参考:SQL Server的日期和时间类型 SQL Server使用 Date 表示日期,time表示时间,使用datetime和datetime2表示日期和时间. 1.秒的精度 秒的精度是指TSQL ...
- 网络编程基础【day10】:我是一个进程(三)
本节内容 1.引子 2.进程的诞生 3.线程 4.争吵 一.引子 我听说我的祖先们生活在专用计算机里, 一生只帮助人类做一件事情,比说微积分运算 了.人口统计了 .生成密码.甚至通过织布机印花 ! ...
- OPCServer:使用Matrikon OPC Server Simulation
实验用模拟OPCServer 旧版(50M):Matrikon OPC Server Simulation(v1.5.0.0),百度网盘,密码: mcur 新版(157M):Matrikon OPC ...
- Linux系统中用户组、文件权限浅解
用户组 在linux中的每个用户必须属于一个组,不能独立于组外.在Linux中每个文件有所有者.所在组.其它组的概念. [所有者] 一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用& ...
- 解析/proc/net/dev
https://stackoverflow.com/questions/1052589/how-can-i-parse-the-output-of-proc-net-dev-into-keyvalue ...
- tensorflow--logistic regression
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist=input_data. ...
- aspnetpager使用介绍
AspNetPager分页控件解决了分页中的很多问题,直接采用该控件进行分页处理,会将繁琐的分页工作变得简单化, 效果如下: 下面是我如何使用AspNetPager控件进行分页处理的详细代码: 1.首 ...
- 电脑丢失api-ms-win-core-libraryloader-|1-1-1.dll怎么办
电脑从win7升级到win10,到98%的时候提示说丢失.dll,如图,我是64位系统,怎么解决这个问题呢?在脚本之家下载了 放到system32中也没有用,在线等,谢谢! 用C:\Windows\S ...
- 第26月第13天 hibernate导包
1. https://yq.aliyun.com/ziliao/386827