一 概述
NodeManager是运行在单个节点上的代理,它管理Hadoop集群中单个计算节点,功能包括与ResourceManager保持通信,管理Container的生命周期、监控每个Container的资源使用(内存、CPU等)情况、追踪节点健康状况、管理日志和不同应用程序用到的附属服务等。
NodeManager是YARN中单个节点的代理,它需要与应用程序的ApplicationMaster和集群管理者ResourceManager交互;它从ApplicationMaster上接收有关Container的命令并执行(比如启动、停止Contaner);向ResourceManager汇报各个Container运行状态和节点健康状况,并领取有关Container的命令(比如清理Container)。
二 基本职能
两个主要的协议 ResourceTrackerProtocol协议 和 ContainerManagementProtocol协议
2.1 ResourceTrackerProtocol协议
a.registerNodeManager
注册自己,需要告诉RM自己的host ip、端口号、对外的tracking url以及自己拥有的资源总量(当前支持内存和虚拟内存两种资源)。
b.nodeHearbeat
NodeManager启动后,通过RPC协议向ResourceManager注册、汇报结点健康状况和Container运行状态,并领取ResourceManager下达的命令,包括重新初始化、清理Container占用资源等。
2.2 ContainerManagementProtocol协议
应用程序的ApplicationMaster通过RPC协议向NodeManager发起针对Container的相关操作,包括启动Container、杀死Container、获取Container执行状态。
ApplicationMaster可以将Container相关操作通过RPC的方式第一时间告诉NodeManager。
主要提供了三个RPC函数:
1.startContainer 有一个参数封装了Container启动所需要的本地资源、环境变量、执行命令、Token等信息。
2.stopContainer AM通过该RPC要求NodeManager停止(杀死)一个Container。该函数有一个StopContanerRequest类型的参数,用于指定待杀死的Container ID.
3.getContainerStatus:ApplicationMaster通过该RPC获取一个Container的运行状态,该函数参数类型为GetContaineStatusRequest,封装了目标Container 的ID。
注:1.NodeManager与ApplicationMaster之间采用了"push模型",ApplicationMaster可以将Container相关操作(启动、查询、停止)第一时间告诉NodeManager,相比于"push 模型",可以大大降低时间延迟。
2.ApplicationMaster可以通过三种方式获取Container的执行状态
a.通过与RM的心跳信息 b.Container汇报给AM c.AM向NM进行查询
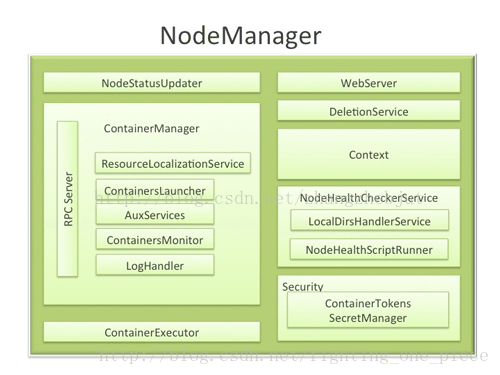
三 NodeManger内部架构
NodeManager 内部组件
介绍一下NodeManager内部的组织结构和主要的模块
3.1 NodeStatusUpdater
NodeStatusUpdater是NodeManager与ResourceManager通信的唯一通道。当NodeManager启动时,该组件向ResourceManager注册,并汇报节点上可用的资源(该值在运行过程中不再汇报);之后,该组件周期性与ResourceManager通信,汇报各个Container的状态更新,包括节点上正运行的Container、已完成的Container等信息,同时ResouceManager会返回待清理Container列表、待清理应用程序列表、诊断信息、各种Token等信息。
3.2 ContainerManager
ContainerManager是NodeManager中最新核心的组件之一,它由多个子组件构成,每个子组件负责一部分功能,它们协同工作组件用来管理运行在该节点上的所有Container,其主要包含的组件如下:
RPCServer 实现了ContainerManagementProtocol协议,是AM和NM通信的唯一通道。ContainerManager从各个ApplicationMaster上接受RPC请求以启动新的Container或者停止正在运行的Contaier。
ResourceLocalizationService 负责Container所需资源的本地化。能够按照描述从HDFS上下载Container所需的文件资源,并尽量将他们分摊到各个磁盘上以防止出现访问热点。此外,它会为下载的文件添加访问控制权限,并为之施加合适的磁盘空间使用份额。
ContainerLaucher 维护了一个线程池以并行完成Container相关操作。比如杀死或启动Container。 启动请求由AM发起,杀死请求有AM或者RM发起。
AuxServices NodeManager允许用户通过配置附属服务的方式扩展自己的功能,这使得每个节点可以定制一些特定框架需要的服务。附属服务需要在NM启动前配置好,并由NM统一启动和关闭。典型的应用是MapReduce框架中用到的Shuffle HTTP Server,其通过封装成一个附属服务由各个NodeManager启动。
ContainersMonitor 负责监控Container的资源使用量。为了实现资源的隔离和公平共享,RM 为每个Container分配一定量的资源,而ContainerMonitor周期性的探测它在运行过程中的资源利用量,一旦发现Container超过它允许使用的份额上限,就向它发送信号将其杀死。这可以避免资源密集型的Container影响到同节点上的其他正在运行的Container。
注:YARN只有对内存资源是通过ContainerMonitor监控的方式加以限制的,对于CPU资源,则采用轻量级资源隔离方案Cgroups.
3.3 NodeHealthCheckservice
结点健康检查,NodeHealthCheckSevice通过周期性地运行一个自定义的脚步和向磁盘写文件检查节点健康状况,并通过NodeStatusUpdater传递给ResouceManager.而ResouceManager则根据每个NodeManager的健康状况适当调整分配的任务数目。一旦RM发现一个节点处于不健康的状态,则会将其加入黑名单,此后不再为它分配任务,直到再次转为健康状态。需要注意的是,节点被加入黑名单后,正在运行的Container仍会正常运行,不会被杀死。
第一种方式通过管理员自定义的Shell脚步。(NM上专门有一个周期性任务执行该脚步,一旦该脚步输出以"ERROR"开头的字符串,则认为结点处于不健康状态)
第二种是判断磁盘好坏。(NM上专门有一个周期性任务检测磁盘的好坏,如果坏磁盘数据达到一定的比例,则认为结点处于不健康的状态)。
3.4 DeleteService
NM 将文件的删除功能服务化,即提供一个专门的文件删除服务异步删除失效文件,这样可以避免同步删除文件带来的性能开销。
3.5 Security
安全模块是NM中的一个重要模块,它由两部分组成,分别是ApplicationACLsManager 确保访问NM的用户是合法的,ContainerTokenSecretManger:确保用户请求的资源是被RM授权过的。
3.6 WebServer
通过Web界面向用户展示该节点上所有应用程序运行状态、Container列表、节点健康状况和Container产生的日志等信息。
四 分布式缓存
类似于MRv1中的Distrubuted Cache,其主要作用就是将用户应用程序执行时所需的外部文件资源自动透明的下载缓存到各个节点,从而省去了用户手动部署这些文件麻烦。
YARN分布式缓存工作流程如下:
1.客户端将应用程序所需的文件资源(外部字典、JAR包、二进制文件)提交到HDFS上。
2.客户端将应用程序提交到RM上。
3.RM将与某个NM进行通信,启动应用程序AM,NM收到命令后,首先从HDFS上下载文件(缓存),然后启动AM。
4.AM与RM通信,以请求和获取计算资源。
5.AM收到新分配到的计算资源后,与对应的NM通信,以启动任务。
6.如果应用程序第一次在该节点上启动任务,NM首先从HDFS上下载文件缓存到本地,然后启动任务。
7.NM后续收到启动任务请求后,如果文件已在本地缓存,则直接执行任务,否则等待文件缓存完成后再启动。
各个节点上的缓存文件由对应的NM管理和维护。
注:在Hadoop中,分布式缓存并不是将文件缓存到集群中各个节点的内存中,而是将文件缓存到各个节点的磁盘上,以便执行任务时直接从磁盘上读取文件。
资源的可见性分为三类:
PUBLIC: 节点上所有用户共享该资源
PRIVATE: 节点上的同一用户的所有应用程序共享该资源
APPLICATION:节点上同一应用程序的所有Container共享,默认情况下,MapReduce作业的split元信息文件job.splimetainfo和属性文件job.xml的可见性是Application的。
上面不同可见性是通过设置特殊目录的位置和目录权限实现的。
NM的资源分类
ARCHIVE:归档文件
FIFE:普通文件
PATTERN:以上两种文件的混合体,有多种类型文件存在。
注:1.YARN是通过比较resource、type、timestamp和pattern四个字段是否相同来判断两个资源请求是否相同的。如果一个已经被缓存到各个节点上的文件被用户修改了,则下次使用时会自动触发一次缓存更新,以重新从HDFS上下载文件。
2.分布式缓存完成的主要功能是文件下载,涉及大量的磁盘读写,因此整个过程采用了异步并发模型加快文件下载速度,以避免同步模型带来的性能开销。
五 目录结构
NodeManager上的目录可分为两种:数据目录和日志目录,其中数据目录用于存放执行Container所需的数据(比如可执行程序或JAR包、配置文件等)和运行过程中产生的临时数据。
NM在每个磁盘上为该作业创建相同的目录结构,且采用轮询的调度方式将目录(磁盘)分配给不同的Container的不同模块以避免干扰。考虑到一个应用程序的不同Container之间存在依赖,为了避免提前清除已经完成的Container输出的中间数据破坏应用程序的设计逻辑,YARN统一规定,只有当应用程序运行结束后,才统一清楚Container产生的中间数据。
日志目录用于存放Container运行时输出的日志。NM提供了定期清除和日志聚集转存两种日志清理机制,默认情况下,采用的是定期清除机制,该任务由LogHandler组件完成。
六 状态机管理
NodeManager维护了三类状态机,分别是:Application、Container和LocalizedResource,它们均直接或者间接参与维护一个应用程序的生命周期。
当NodeManager收到来自某个应用程序第一次Container启动命令时,会创建一个Application状态机跟踪该应用程序在该结点上的生命周期,而每个Container的运行过程同样由一个状态机维护。此外Application所需的资源(比如文本文件、JAR包、归档文件等)需要从HDFS上下载,每个资源的下载过程均由一个状态机LocalizedResouce维护和跟踪。
NM上Application维护的信息是ResourceManager端Application信息的子集,这有利于对一个节点上的同一个Application的所有Container进行统一管理(比如记录每一个Application运行在该节点上的Container列表,杀死一个Application的所有Container等)。它实际的实现类是ApplicationImpl,该类维护了一个Application状态机,记录了Application可能存在的各个状态以及导致状态间转换的事件。需要注意的是NM上的Application生命周期与ResourceManager上Application的生命周期是一致的。
LocalizedResource是NodeManager中维护一种“资源”(资源文件、JAR包、归档文件等外部文件资源)生命周期的数据结构,它维护了一个状态,记录了"资源"可能存在的各种状态以及导致状态间转换的事件。
七 Container 生命周期剖
Container启动过程主要经历三个阶段:资源本地化、启动并运行Container和资源清理。
Container的启动命令是由各个ApplicationMaster通过RPC函数ContainerManagementProtocol#startContainer向NodeManager发起的,NodeManager中的ContainerManager组件负责接受并处理该请求。
7.1 资源本地化
资源本地化指的是准备Containers运行所需的环境,主要是分布式缓存机制完成的工作,功能包括初始化各种服务组件、创建工作目录、从HDFS下载运行所需的各种资源(比如文本文件、JAR包、可执行文件)等。资源本地化主要是由两部分组成,分别是应用程序初始化和Container本地化。其中,应用程序初始化的工作是初始化各类必需的服务组件(比如日志记录组件LogHandler、资源状态追踪组件LocalResouceTrackerImpl),供后续Container使用,通常由Application的第一个Container完成;Container本地化则是创建工作目录,从HDFS上下载各类文件资源。
注:1. YARN资源分为PUBLIC PRIVATE 和 APPLICATION三类。不同级别的资源对不同用户和应用程序的访问权限不同,这也直接导致资源的本地化方式不同。它们的本地化由ResouceLocalizationSevice服务完成,但内部由不同的线程负责机载。
2.两种类型的Container: 一种是该Container是ApplicationMaster发送到给节点的第一个Container;另一种则不是第一个Container.
资源本地化过程可概括为:在NodeManager上,同一个应用程序的所有ContainerImpl异步并发向资源下载服务ResourceLocalizationService发送待下载的资源。而ResourceLocationService下载完一类资源后,将通知依赖该资源的所有Container。一旦一个Container依赖的资源已经全部下载完成,则该Container进入运行阶段。
7.2 Container启动
由ContainersLauncher服务完成,该服务将进一步调用插拔式组件ContainerExecutor,YARN提供了两种ContainerExecutor,一种是DefaultContainerExecutor一种是LinuxContainerExecutor.
主要过程可概括为:将待运行的Container所需的环境变量和运行命令写到Shell脚本launch_container.sh中,并将启动该脚本的命令写入default_container_executor.sh中,然后通过运行该脚步启动Container.
7.3 资源清理
是资源本地化的逆过程,它负责清理各种资源,它们均由ResouceLocalizatonService服务完成。
Container运行完成后(可能成功或者失败),NM需回收它占用的资源,这些资源主要是Container运行时使用的临时文件,它们的来源主要是ResourceLocalizationService和ContainerExecutor两个服务/组件,其中,ResourceLocalizationService将数据HDFS文件下载到本地,ContainerExecutor为Container创建私有工作目录,并保存一些临时文件(比如Container进程pid文件).因此,Container资源清理过程主要是通知这两个组件删除临时目录。
注:由于每个NM上只负责处理一个应用程序的部分任务,因此它无法知道一个应用程序何时完成,该信息只有控制着全部消息的RM知道,因此当一个应用程序运行结束时,需要由它广播给各个NM,再进一步由NM清理应用程序占用的所有资源,包括产生的中间数据。
八 资源隔离
资源隔离是指为不同的应用任务提供可独立使用的计算资源以避免它们之间互相干扰。当前存在很多种资源隔离技术,比如硬件虚拟化、虚拟机、Cgroups、Linux Container等。YARN对内存资源和CPU资源的管理采用的不同的资源隔离方案。
对于内存资源,它是一种限制性资源,它的量的大小直接决定的应用程序的死活。YARN采用了进程监控的方案控制内存资源使用量,一旦发现它超过约定的资源量,就将其杀死。
另一种可选的方案则是基于轻量级资源隔离技术Cgroups,Cgroups是Linux内核提供的弹性资源隔离机制,可以严格限制内存的使用上限,一旦进程使用资源量超过事先定义的上限值,则可将其杀死。对于CPU资源,它是一种弹性资源,它的量的大小不会直接影响应用程序的死活,因此采用了Cgroups。
Cgroups(Control Groups)是Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如CPU、内存、IO等)的机制,最初由Google工程师提出,后来被整合进Linux内核。Cgroups最初的目的是为资源管理提供一个统一的框架,既整合现有的cpuset等子系统,也为未来新的子系统提供接口,以使得Cgoups适合多种应用场景,从单个进程的资源控制到实现操作系统层次的虚拟化的应用场景均支持。总结起来,Cgroups提供了已下功能:
1.限制进程组使用的资源量。
2.进程组的优先级控制,比如,可以使用CPU子系统为某个进程组分配特定CPU share.
3.对进程组使用的资源量进行记账 4.进程控制,比如将某个进程组挂起和恢复。
YARN使用了Cgroups子系统中的CPU和Memory子系统,CPU子系统用于控制Cgroups中所有的进程可以使用的CPU时间片。Memory子系统可用于限定一个进程的内存使用上限,一旦超过该限制,将认为它为OOM,会将其杀死。
对于内存资源隔离,YARN采用了与MRv1这种基于线程监控的资源控制方式,这样做到的主要出发点是:这种方式更加灵活,且能够防止内存骤增骤降导致内存不足而死掉。
对于CPU资源隔离,YARN采用了轻量级的Cgroups。
注:默认情况下,NM未启用任何CPU资源隔离机制,如果想要启用该机制,需使用LinuxContainerExecutor,它能够以应用程序提交者的身份创建文件,运行Container和销毁Container.
九 小结
NodeManager作为资源管理系统YARN的一个重要服务,它的主要功能包括节点健康状况检测、分布式缓存机制、目录结构管理、状态机管理、Container生命周期、资源隔离机制等机制。NM管理的是Container而不是任务,一个Container中可能运行着各种任务,但是对NM而言是透明的,它只负责Container相关操作,比如管理Container的生命周期,即启动Container、监控Container和清理Container等。
- TDH-大数据基础
------------------------------------------------------------------------------------*******大数据概念和基础* ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- YARN基本框架介绍
YARN基本框架介绍 转载请注明出处:http://www.cnblogs.com/BYRans/ 在之前的博客<YARN与MRv1的对比>中介绍了YARN对Hadoop 1.0的完善.本 ...
- Spark on YARN两种运行模式介绍
本文出自:Spark on YARN两种运行模式介绍http://www.aboutyun.com/thread-12294-1-1.html(出处: about云开发) 问题导读 1.Spark ...
- Hadoop介绍及最新稳定版Hadoop 2.4.1下载地址及单节点安装
Hadoop介绍 Hadoop是一个能对大量数据进行分布式处理的软件框架.其基本的组成包括hdfs分布式文件系统和可以运行在hdfs文件系统上的MapReduce编程模型,以及基于hdfs和MapR ...
- Cloudera impala简单介绍及安装具体解释
一.Impala简单介绍 Cloudera Impala对你存储在Apache Hadoop在HDFS,HBase的数据提供直接查询互动的SQL.除了像Hive使用同样的统一存储平台,Impala也使 ...
- Hadoop YARN介绍
YARN产生背景 MRv1的局限 YARN是在MRv1基础上演化而来的,它克服了MRv1中的各种局限性.在正式介绍YARN之前,先了解下MRv1的一些局限性,主要有以下几个方面: 扩展性差.在MRv1 ...
- Hadoop集群的hbase介绍、搭建、环境、安装
1.hbase的介绍(自行百度hbase,比我总结的全面具体) HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
随机推荐
- springboot学习三:整合jsp
在pom.xml加入jstl <!--springboot tomcat jsp 支持开启--> <dependency> <groupId>org.apache. ...
- html弹出div
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- IIS 字符串过长
jquery.datatable.js---弹窗要用极速模式 <?xml version="1.0" encoding="utf-8"?><c ...
- Mac 启用NTFS
How to Enable NTFS Write Support in Mac OS X http://osxdaily.com/2013/10/02/enable-ntfs-write-suppor ...
- QTP - 描述性编程
描述性编程: 1.QTP的描述性编程能够摆脱测试对象库的限制,编写出更为复杂.适应能力更强的测试脚本. 2.即不需要在仓库晨定义,也能访问和操作实际对象. 3.用描述性编程编写的测试脚本在运行时,QT ...
- jpa @RepositoryRestResource
依赖: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spr ...
- sql语句应用
laravel5.6框架中用到的sql语句 //排序 $data=DB::table('admin')->select(array('id','name','password'))->or ...
- 使用memcached遇到的一些问题
1 .多台服务器时间不统一,引发缓存存取异常. 问题描述: 同一台memcache缓存服务器,比如memcache.server=192.168.88.51:11211 提供缓存服务: 项目部署到 ...
- Windows邮件客户端
换回WIndows 因为要保存邮件 所以需要邮件客户端 Foxmail 腾讯自家 同样需要独立密码 之前的foxmail是全拼 新注册了一个@qq 发现新注册的@qq绑定到的是新的QQ号 算了 去用1 ...
- lanya
var app = getApp() Page({ data: { motto: 'Hello World', openBLE:'打开蓝牙设备', startBLEDiscover ...