Hadoop集群的hbase介绍、搭建、环境、安装
1、hbase的介绍(自行百度hbase,比我总结的全面具体)
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务。
2、搭建hbase的环境准备
1.jdk的1.7以上版本
2.前提zookper集群和HDFS集群
保证HDFS的namenode和datanode启动,也就是zookeeper出现QuorumPeerMain的leader和follower
3.安装hbase(今天的主题,理论知识太多也没用!!!)
3.1下载HBase安装包(hbase.apache.org)
我一般都是下载到window10里,在用Xftp传到JVM里的tmp目录下,安装到我JVM对相应的/usr/local路径下
tar -zxvf hbase-1.2.6-bin.tar.gz -C /usr/local/
然后进入我的local目录 cd /usr/local/
重命名 mv hbase-1.2.6/ hbase
我通常会把软件的docs删了,当搭建集群时会拷贝整个hbase,docs装的API在虚拟机里我们几乎不需要。
cd hbase 删除docs :rm -rf docs/
3.2修改环境变量
3.2.1 使用 vim /etc/profile命令修改系统环境变量(当你是普通用户时 sudo vim /etc/profile)
#hbase
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
保存后source /etc/profile应用下
3.2.2 在修改hbase的环境变量(记住的JAVA_HOME可使用echo $JAVA_HOME查我的路径是/usr/local/java)
cd /usr/local/hbase/conf
vim hbase-env.sh
export JAVA_HOME=/usr/local/java #Java环境
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop #通过hadoop的配置文件找到hadoop集群(hdfs_site.xml的目录位置)
export HBASE_MANAGES_ZK=false #不使用HBASE自带的zookeeper管理集群
3.2.3HBase参数配置:(hbase-site.xml)由于我直接配置的集群变量,可能跟伪集群不大一样。
<property><!-- 指定HDFS的路径信息 -->
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<property><!-- Hbase的运行模式,false单机,true分布式集群 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property><!-- ZK集群 -->
<name>hbase.zookeeper.quorum</name>
<value>zkHost01:2181,zkHost02:2181,zkHost03:2181</value>
</property>
<property><!--web ui port-->
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
3.2.4测试是否启动成功
zkServer.sh start
start-dfs.sh
start-hbase.sh
jps显示如下
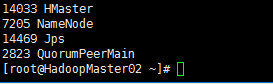
由于我搭的集群的正常还应该有个
ok!!!!!!!!!!!
4,配置集群的Hbase
如果你按上述创建完成了我们配置一个集群,克隆机就不用说了吧,搭建HDFS集群略过
达到的效果是配置2台主机(Hmaster),3个子机(HRegionServer)
主机分别为HaoopMaster01,HaoopMaster02.子机为HadoopSlave1,HadoopSlave2,HadoopSlave3
4.1在主机直接配置子机vim /usr/local/hbase/conf/regionservers
#里面填入子机名或端口号(可在etc下hosts里修改集群名对应端口)
HadoopSlave1
HadoopSlave2
HadoopSlave3
4.2把你配置好的hbaser通过你的单点机直接复制到其他机器上
再把第二台主机的环境配好 scp -r /etc/profile HadoopMaster01 :/etc/
scp -r hbase HadoopMaster01 :/usr/local
scp -r hbase HadoopSlave1 :/usr/local
scp -r hbase HadoopSlave2 :/usr/local
scp -r hbase HadoopSlave3 :/usr/local
4.3第二台主机需要单启(这台主机是防止一台主机down了,然后自动顶上)
hbase-daemon.sh start master
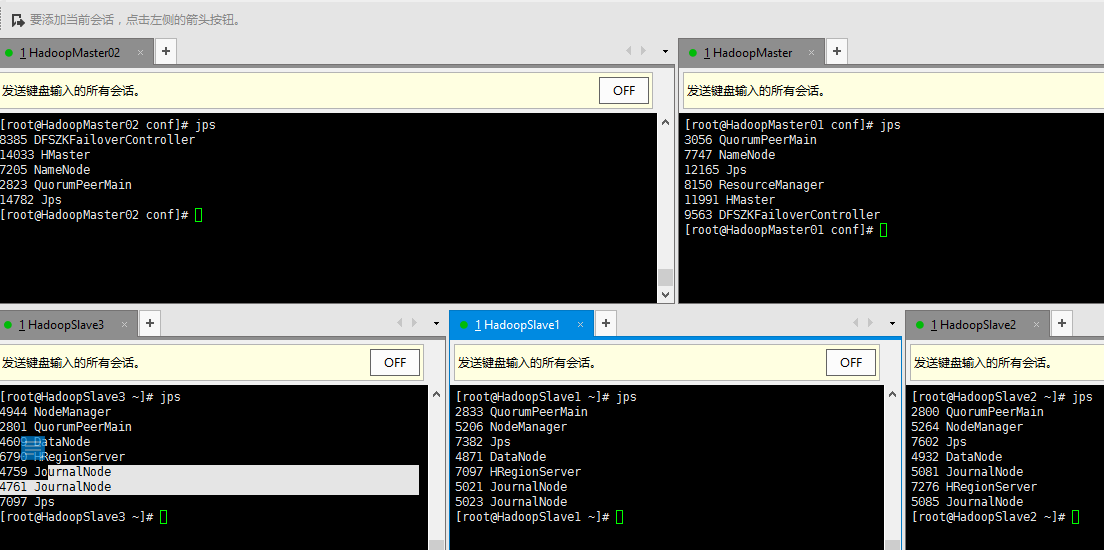
4.4测试
jps
这个集群主机的DFSZKFailoverController和ResousrceManager于本次配置无关子机的nodeManager和journalnode无关
因为我测试之前搭建的yarn和zfkc所以就显示上了(so sorry!)
有什么大数据集群搭建问题可以直接评论我,一起进步吧!!!!
Hadoop集群的hbase介绍、搭建、环境、安装的更多相关文章
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- hadoop 集群及hbase集群的pid文件存放位置
一.当hbase集群和hadoop集群停了做一些配置调整,结果执行stop-all.sh的时候无法停止集群, 提示no datanode,no namenode等等之类的信息, 查看stop-all. ...
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
本篇将在 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper) 阿 ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- Hadoop集群(三) Hbase搭建
前面已经完成Zookeeper和HDFS的安装,本文会详细介绍Hbase的安装步骤.以及安装过程中遇到问题的汇总. 系列文章: Hadoop集群(一) Zookeeper搭建 Hadoop集群(二 ...
- 基于Hadoop集群的HBase集群的配置
一 Hadoop集群部署 hadoop配置 二 Zookeeper集群部署 zookeeper配置 三 Hbase集群部署 1.配置hbase-env.sh HBASE_MANAGES_ZK:用来 ...
- Hadoop集群中Hbase的介绍、安装、使用
导读 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. 一.Hbase ...
随机推荐
- Jenkins修改管理员密码
前言:Jenkins修改管理员密码,我看了网上所有的教程,竟然全都是拿着一串已经加密好的111111的密文去替代config.xml文件里面的密码,然后大家的密码都是111111!我觉得这种做法实在太 ...
- AngularJS语法基础及数据绑定——详解各种数据绑定指令、属性应用
AngularJS简单易学,但是功能强大.特别是在构建单页面应用方面效果显著.而 数据绑定 可以说是他被广泛使用的最主要的优点.他舍弃了对DOM的操作方式,一切都由AngularJS来自动更新视图,我 ...
- 一天搞定CSS:定位position--17
1.定位取值概览 2.相对定位relative <!DOCTYPE html> <html> <head> <meta charset="UTF-8 ...
- 初识Tensorboard
1.什么是Tensorboard? PPT设计原则中有这样一条,叫"文不如表,表不如图",可见图表在表达中更为直观.明确.程序设计中也是一样,我们经常用图表来描述程序的结构和流程, ...
- SVN·最新使用教程总结
SVN简介: 为什么要使用SVN? 程序员在编写程序的过程中,每个程序员都会生成很多不同的版本,这就需要程序员有效的管理代码,在需要的时候可以迅速,准确取出相应的版本. Subversion是什么? ...
- 不用媒体查询做web响应式设计-遁地龙卷风
(0)写在前面 讲述知乎上看到的一篇文章中的一个案例,让我脑洞大开,佩服至极,特意第二天找到原文赞赏了 5元,原文地址https://zhuanlan.zhihu.com/p/27258076,案例用 ...
- Redis数据类型之List(三)
前言:list即链表,它是一个能维持数据先后顺序的列表,便于在表的两端追加和删除数据,中间位置的存取具有O(N)的时间复杂度,是一个双向链表. 一.内部原理 redis ...
- Structured-Streaming之窗口操作
Structured Streaming 之窗口事件时间聚合操作 Spark Streaming 中 Exactly Once 指的是: 每条数据从输入源传递到 Spark 应用程序 Exactly ...
- Kafka 源代码分析.
这里记录kafka源代码笔记.(代码版本是0.8.2.1) kafka的源代码如何下载.这里简单说一下. git clone https://git-wip-us.apache.org/repos/a ...
- c# 读写文件时文件正由另一进程使用,因此该进程无法访问该文件
c# 读写文件时文件正由另一进程使用,因此该进程无法访问该文件,在IO处理上遇到了无法操作的问题. 文件"D:\log.txt"正由另一进程使用,因此该进程无法访问该文件. log ...