pytorch中网络特征图(feture map)、卷积核权重、卷积核最匹配样本、类别激活图(Class Activation Map/CAM)、网络结构的可视化方法
0,可视化的重要性:
深度学习很多方向所谓改进模型、改进网络都是在按照人的主观思想在改进,常常在说模型的本质是提取特征,但并不知道它提取了什么特征、哪些区域对于识别真正起作用、也不知道网络是根据什么得出了分类结果。为了增强结果的可解释性,需要给出模型的一些可视化图来证明模型或新methods对于任务的作用,这一点不仅能增加新模型或新methods可信度;还可以根据可视化某个网络的结果分析其不足之处,从而提出新的改进方法。(写论文还可以用来凑字数、凑工作量:)
无特殊说明,本文中所用的网络是:
torchvision.models.resnet50(pretrained=True)
所用的图片为

1,特征图(feture map)
- 概念
特征图是一个在深度学习的研究过程中经常会遇到的概念,简单来说就是对输入进行一次计算处理后的输出,通过对特征图的可视化可以看出输入样本在网络中的变化情况。 - 可视化方法:
- 直接可视化:直接让输入数据经过各层网络,获取各层网络处理后的输出,然后绘制想要展示的特征图即可。
- 反卷积网络(deconvnet)From 'Visualizing and Understanding Convolutional Networks':对一个训练好的神经网络中任意一层feature map经过反卷积网络后重构出像素空间,主要操作是
- Unpooling/反池化:将最大值放到原位置,而其他位置直接置零。
- Rectification:同样使用Relu作为激活函数。
- Filtering/反卷积:使用原网络的卷积核的转置作为卷积核,对Rectification后的输出进行卷积。
- 导向反向传播(Guided-backpropagation)From 'Striving for simplicity: The all convolutional net':其与反卷积网络的区别在于对ReLU的处理方式,在反卷积网络中使用ReLU处理梯度,只回传梯度大于0的位置;而在普通反向传播中只回传feature map中大于0的位置;在导向反向传播中结合这两者,只回传输入和梯度都大于0的位置。
- 例子
'''方法1,直接可视化'''
import torch
import torchvision
import cv2
from PIL import Image
import torchvision.models as models
import torch.nn as nn
from matplotlib import pyplot as plt
import math
'''1,加载训练模型'''
resnet50 = models.resnet50(pretrained=True)
print(resnet50)
'''2,提取CNN层,非必须'''
conv_layers = []
model_weights = []
model_children = list(models.resnet50().children())
counter = 0
for i in range(len(model_children)):
if type(model_children[i]) == nn.Conv2d:
counter += 1
model_weights.append(model_children[i].weight)
conv_layers.append(model_children[i])
elif type(model_children[i]) == nn.Sequential:
for j in range(len(model_children[i])):
for child in model_children[i][j].children():
if type(child) == nn.Conv2d:
counter += 1
model_weights.append(child.weight)
conv_layers.append(child)
'''3,读取数据'''
img = cv2.cvtColor(cv2.imread('data.jpg'), cv2.COLOR_BGR2RGB)
img = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage(),
torchvision.transforms.Resize((1050, 1680)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])(img).unsqueeze(0)
'''4,特征映射,这里绘制第一层卷积的feature map'''
featuremaps = [conv_layers[0](img)]
plt.figure(1)
for i in range(64):
plt.subplot(8, 8, i + 1)
plt.axis('off')
plt.imshow(featuremaps[0][0, i, :, :].detach(), cmap='gray')
plt.show()

2,卷积核权重
- 概念
卷积核的计算可以看作是在计算相似度,二维卷积核本身可以看作是一副缩略图,一维卷积核本身也可以看作是一段一维信号,卷积核权重的可视化就是将这些信息可视化。(虽然这些信息几乎都是杂乱无章的,没什么用:) - 可视化方法
取出某个想要可视化的卷积核权重,然后绘图即可。 - 例子
for i in range(64):
plt.subplot(8, 8, i+1)
plt.axis('off')
plt.imshow(model_weights[0][i][0, :, :].detach(), cmap='gray')
plt.show()

3,卷积核最匹配样本
- 概念
正如2中提到的,卷积核的计算可以看作是在计算相似度,那么在一批样本中经过卷积核计算以后的相似度值肯定有高有底,那么相似度越高也就越满足这个卷积核的“口味”,这也意味着该样本与该卷积核越匹配。那么,有没有方法能够超越有限的训练样本,生成与特定卷积核最匹配的样本呢?答案是肯定的。一个可行的思路是:随机初始化生成一个样本(指的是对样本的各个数据点随机取值,而不是在数据集中随机选一个样本),然后经过前向传播到该卷积核;我们希望这个随机生成的样本在经过这一层卷积核时响应值能尽可能的大(响应值比较大的样本是这个卷积核比较认可的,是与识别任务更相关的);我们要做的就是不断调整样本各个数据点的值,直到响应值足够大,我们就可以认为此时的样本就是这个卷积核所认可的,从而达到生成卷积核最匹配样本的目的。 - 可视化方法
设计一个损失函数(例如:经过变换后的响应值),使用梯度上升,更新数据点的值,使响应值最大。 - 例子
下图展示的是pytorch中的resnet50中的layer1的最后一次卷积操作中的256个卷积核中的0,10,...,150这16个卷积核的最匹配样本。优化过程中用了两种方法,结果如图:
方法1

方法2,可以明显看出方法2的结果区别性更大

4,类别激活图(Class Activation Map/CAM)
- 概念
特征图可视化、卷积核权重可视化、卷积核最匹配样本这些方法更多是用于分析模型在某一层学习到的东西;但是对于不同的类,我们又如何知道模型是根据哪些信息进行识别的?是否能将这些信息在原始数据上表示出来(比如说热力图)?答案依旧是肯定的。这个方法主要是CAM系列,目前有CAM, Grad-CAM, Grad-CAM++。其中CAM需要特定的结构-GAP,但大部分现有的模型没有这个结构,想要使用该方法便需要修改原模型结构,并重新训练,因此适用范围有限。针对CAM的缺陷,有了之后Grad-CAM的提出。 - 可视化方法
Grad-CAM的最大特点就是不再需要修改现有的模型结构,也不需要重新训练,可以直接在原模型上可视化。Grad-CAM对于想要可视化的类别C,使最后输出的类别C的概率值通过反向传播到最后一层feature maps,得到类别C对该feature maps的每个像素的梯度值;对每个像素的梯度值取全局平均池化,即可得到对feature maps的加权系数alpha;接下来对特征图加权求和,使用ReLU进行修正,再进行上采样。使用ReLU的原因是对于那些负值,可认为与识别类别C无关,这些负值可能是与其他类别有关,而正值才是对识别C有正面影响的。

计算梯度及全局平均池化:
\]
加权:
\]
- 例子
1,由蓝到红,越红代表关注度越高,对于类别分配的结果影响越大,这个例子将图片识别为n02909870 水桶,从关注的区域也可以看出预测是失败的,没有关注到有效的信息

这个预训练模型眼里好像不是水桶就是钩子。。。
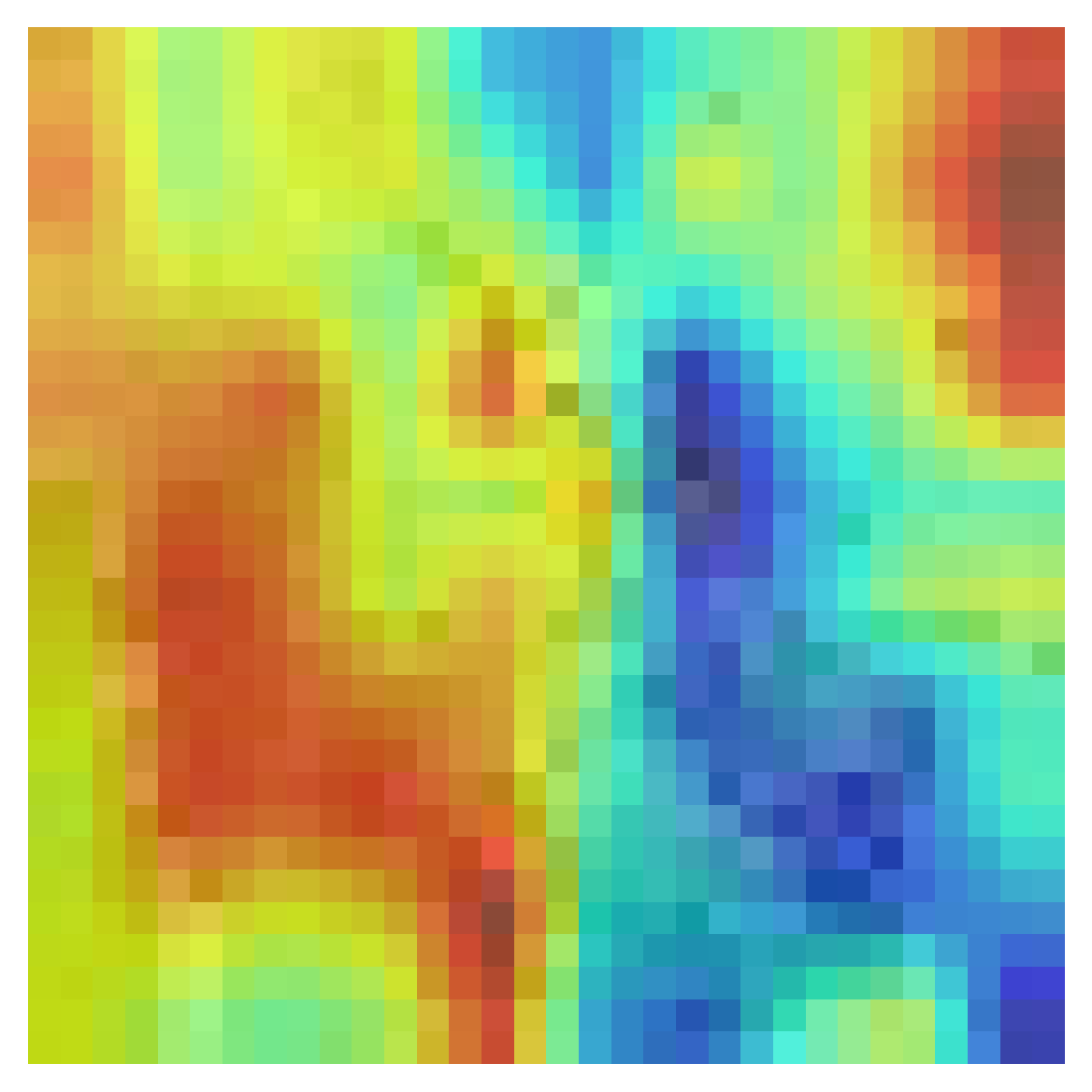
2,从网上找了一个模型,效果就挺好的
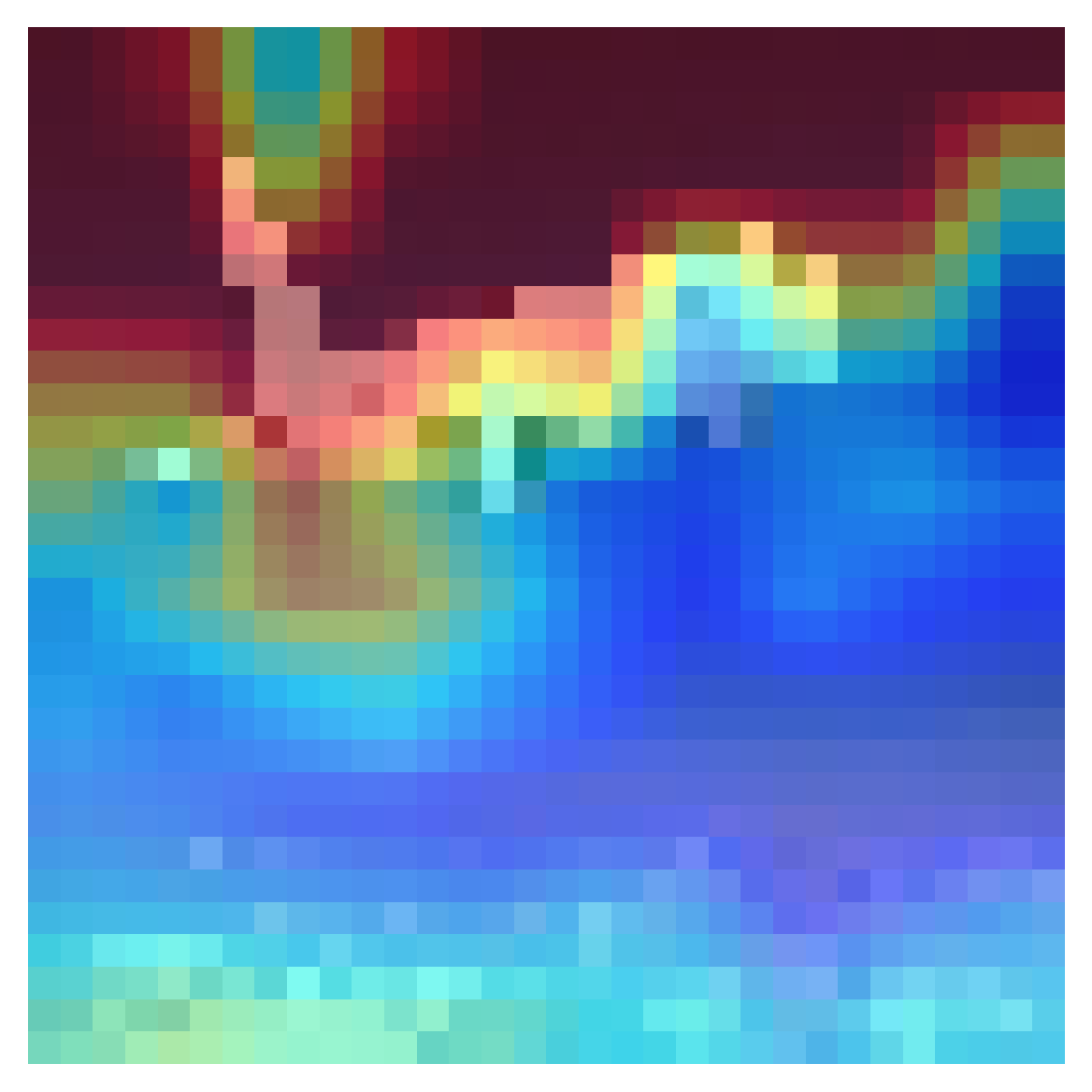











识别青蛙的结果很有意思,这意味着网络关注的重点不在于青蛙,反而在于青蛙周围的环境,而且网络的预测结果还是正确的!



5,网络结构的可视化
- 可视化方法
用tensorboard直接绘制就行,注意两点- 路径不要有中文
- pytorch版本在1.3.0及以上(低版本不显示)
- 例子
from torch.utils.tensorboard import SummaryWriter
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
1,初始化writer
'''
writer = SummaryWriter('runs/resnet50') # 指定写入文件的位置
'''
2,加载模型
'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(6 * 12 * 12, 120)
self.fc2 = nn.Linear(120, 84)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 6 * 12 * 12)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x
net = Net()
'''
3,添加网络结构
'''
writer.add_graph(net, torch.randn(1, 1, 28, 28))
writer.close()

pytorch中网络特征图(feture map)、卷积核权重、卷积核最匹配样本、类别激活图(Class Activation Map/CAM)、网络结构的可视化方法的更多相关文章
- CNN中feature map、卷积核、卷积核的个数、filter、channel的概念解释
CNN中feature map.卷积核.卷积核的个数.filter.channel的概念解释 参考链接: https://blog.csdn.net/xys430381_1/article/detai ...
- 使用DeepWalk从图中提取特征
目录 数据的图示 不同类型的基于图的特征 节点属性 局部结构特征 节点嵌入 DeepWalk简介 在Python中实施DeepWalk以查找相似的Wikipedia页面 数据的图示 当你想到" ...
- 详解Pytorch中的网络构造,模型save和load,.pth权重文件解析
转载:https://zhuanlan.zhihu.com/p/53927068 https://blog.csdn.net/wangdongwei0/article/details/88956527 ...
- Pytorch中自定义神经网络卷积核权重
1. 自定义神经网络卷积核权重 神经网络被深度学习者深深喜爱,究其原因之一是神经网络的便利性,使用者只需要根据自己的需求像搭积木一样搭建神经网络框架即可,搭建过程中我们只需要考虑卷积核的尺寸,输入输出 ...
- Pytorch中RoI pooling layer的几种实现
Faster-RCNN论文中在RoI-Head网络中,将128个RoI区域对应的feature map进行截取,而后利用RoI pooling层输出7*7大小的feature map.在pytorch ...
- (原)CNN中的卷积、1x1卷积及在pytorch中的验证
转载请注明处处: http://www.cnblogs.com/darkknightzh/p/9017854.html 参考网址: https://pytorch.org/docs/stable/nn ...
- pytorch中的激励函数(详细版)
初学神经网络和pytorch,这里参考大佬资料来总结一下有哪些激活函数和损失函数(pytorch表示) 首先pytorch初始化: import torch import t ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- pytorch 中的重要模块化接口nn.Module
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 对于自己 ...
随机推荐
- OpenGL在图形管道中调用了什么用户模式图形驱动程序(UMD)?
OpenGL在图形管道中调用了什么用户模式图形驱动程序(UMD)? 图形硬件供应商,需要为显示适配器编,编写用户模式显示驱动程序.用户模式显示驱动程序,是由Microsoft Direct3D运行时加 ...
- 【NX二次开发】用户出口函数介绍
用户出口(User Exit)是NX Open 中的一个重要概念.NX在运行过程中某些特定的位置存在规定的出口,当进程执行到这些出口时,NX会自动检查用户是否在此处已定义了指向内部程序位置的环境变量: ...
- 由一次PasswordBox密码绑定引发的疑问 ---> WPF中的附加属性的定义,以及使用。
1,前几天学习一个项目的时候,遇到了PasswordBox这个控件,由于这个控件的Password属性,不是依赖属性,所以不能和ViewModel层进行数据绑定. 2,但是要实现前后端彻底的分离,就需 ...
- SpringBoot 结合 Spring Cache 操作 Redis 实现数据缓存
系统环境: Redis 版本:5.0.7 SpringBoot 版本:2.2.2.RELEASE 参考地址: Redus 官方网址:https://redis.io/ 博文示例项目 Github 地址 ...
- Waymo object detect 2D解决方案论文拓展
FixMatch 半监督中的基础论文,自监督和模型一致性的代表作. Consistency regularization: 无监督学习的方式,数据\(A\)和经过数据增强的\(A\)计做\(A'\) ...
- 『言善信』Fiddler工具 — 17、Fiddler常用插件(Willow)
目录 1.Traific Difer插件 2.PDF View插件 3.JavaScript Formatter插件 4.CertMaker for iOS and Android插件 5.Synta ...
- Windows内核开发-Windows内部概述-1-
Windows内部概述-1- 进程: 进程是一个程序的运行实例的控制和管理对象.一般的程序员所说进程运行,这样的说法是不对的,因为进程不能运行程序,进程只能管理该程序运行.线程才是真正的执行代码的东西 ...
- alert日志报错:ERROR: failed to establish dependency between database RACDB and diskgroup resource ora.DATA.dg
一.打开数据库alert日志,发现有报错 ERROR: failed to establish dependency between database RACDB and diskgroup reso ...
- Windows操作系统添加永久静态路由
1.比如:添加一条去往 10.10.10.0/24网段的静态路由,指定去往此网段的路由都走 172.20.153.254网关 route -p add 10.10.10.0 mask 255.255. ...
- SpringBoot Validation优雅的全局参数校验
前言 我们都知道在平时写controller时候,都需要对请求参数进行后端校验,一般我们可能会这样写 public String add(UserVO userVO) { if(userVO.getA ...