机器学习——支持向量机SVM
前言
学习本章节前需要先学习:
《机器学习——最优化问题:拉格朗日乘子法、KKT条件以及对偶问题》
《机器学习——感知机》
1 摘要:
支持向量机(SVM)是一种二类分类模型,其基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大,间隔最大使它有别于感知机,支持向量机也可通过核技巧使它成为非线性分类器。支持向量机的学习策略是间隔最大化,可将其转化为一个求解凸二次规划的问题,其学习算法就为求解凸二次规划的最优化算法序列最小最优化算法(SMO)。
关键词:二类分类;间隔最大化;核技巧;凸二次规划;序列最小最优化算法
2 回顾感知机模型
在感知机原理小结中,讲到了感知机的分类原理,感知机模型就是尝试找到一条直线,能够把二元数据隔离开。如果提升到高维,就是找到一个超平面,把高维数据分开。对于这个分离的超平面,定义为 $w^Tx + b = 0$ ,如下图。在超平面 $w^Tx + b = 0$ 上方定义为 $y=1$,在超平面 $w^Tx + b = 0$ 下方定义为 $y=−1$。可以看出满足这个条件的超平面并不止一个。
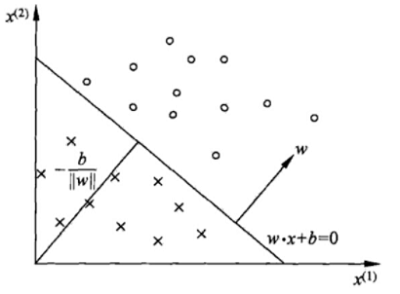
看感知机模型的损失函数优化,它的思想是让所有误分类的点(定义为 M )到超平面的距离和最小,即最小化下式:
$ {\large \frac{\sum\limits_{x_i \in M}- y^{(i)}(w^Tx^{(i)} +b)}{||w||_2} } $
当 $w$ 和 $b$ 成比例的增加,比如,当分子的 $w$ 和 $b$ 扩大 $N$ 倍时,分母的 L2 范数也会扩大 $N$ 倍。也就是说,分子和分母有固定的倍数关系。那么可以固定分子或者分母为$1$,然后求另一个即分子或者分母的倒数的最小化作为损失函数,这样可以简化损失函数。在感知机模型中,采用保留分子,固定分母 $||w||_2 = 1$ ,即最终感知机模型的损失函数为:
$\sum\limits_{x_i \in M}- y^{(i)}(w^Tx^{(i)} +b)$
3 SVM 的数学模型
支持向量机也叫做 max-Margin Classifer。在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector)。
支持向量是使约束条件式等号成立的点,即:
$y_{i}\left(w \cdot x_{i}+b\right)-1=0$
其中支持向量所在的边界称为间隔边界。由于只有支持向量能够决定分离超平面,起决定性作用,因此将这类分类模型称为支持向量机。
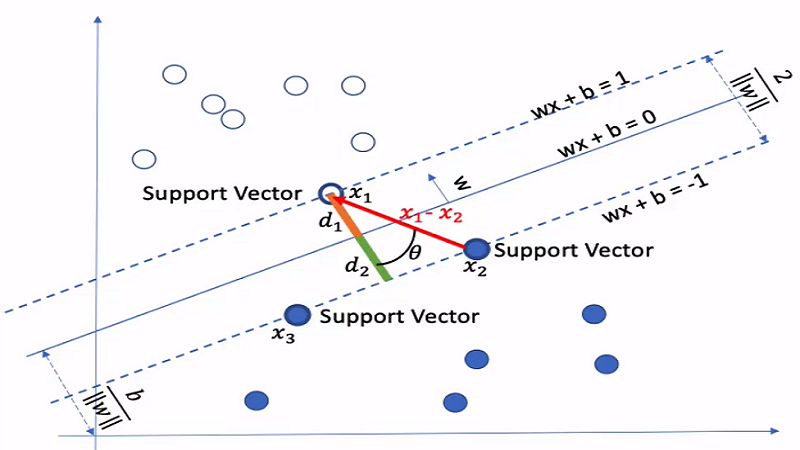
定义由空心圆形类的支持向量构成的一条分割线:
$w^{T} x_{1}+b=1 $
实心圆形类构成的支持向量构成的一条分割线:
$w^{T} x_{2}+b=-1$
上述两式相减:
$\left(w^{T} x_{1}+b\right)-\left(w^{T} x_{2}+b\right)=2$
得:
$w^{T}\left(x_{1}-x_{2}\right)=2$
根据余弦定理得:
$w^{T}\left(x_{1}-x_{2}\right)=\|w\|_{2}\left\|x_{1}-x_{2}\right\|_{2} \cos \theta=2$
简化:
$\left\|x_{1}-x_{2}\right\|_{2} \cos \theta=\frac{2}{\|w\|_{2}}$
求两个类的分割线到中心线 $w^{T} x_{1}+b=0 $ 的距离:
$d_{1}=d_{2}=\frac{\left\|x_{1}-x_{2}\right\|_{2} \cos \theta}{2}=\frac{\frac{2}{\|w\|_{2}}}{2}=\frac{1}{\|w\|_{2}}$
求得两类之间的距离:
$d_{1}+d_{2}=\frac{2}{\|w\|_{2}}$
故:SVM的目标就是使得 $d_{1}+d_{2}=\frac{2}{\|w\|_{2}}$ 之间的距离最大。
4 硬间隔最大化
给定一个特征空间上的训练数据集$T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}$。$x_{i} \in \mathcal{X}=\mathbf{R}^{n}$,$y_{i} \in \mathcal{Y}=\{+1,-1\}$, $i=1,2, \cdots, N $。$x_i$ 为第 $i$ 个特征向量, 也称为实例, $ y_{i}$ 为 $x_{i} $ 的类标记 。当 $y_{i}=+1$ 时, 称 $x_{i} $ 为正例;当 $y_{i}=-1$ 时,称 $x_{i} $ 为 负例。 $ \left(x_{i}, y_{i}\right) $ 称为样本点。再假设训练数据集是线性可分的。
线性可分支持向量机的学习目标是找到一个分离超平面将实例分为正负两类(与感知机相同),但是当数据集线性可分时,感知机的分离超平面有无穷多个。此时,线性可分支持向量机通过间隔最大化求解一个最优分离超平面。
在数据线性可分下,线性可分支持向量机学习到的分离超平面为
$w^{*} \cdot x+b^{*}=0$
以及相应的决策函数为
$f(x)=\operatorname{sign}\left(w^{*} \cdot x+b^{*}\right)$
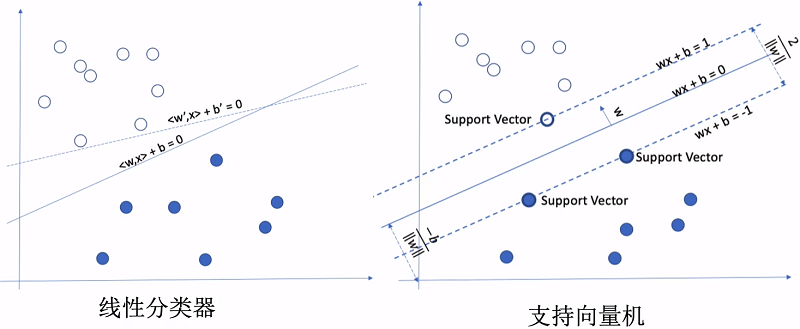
4.1 函数间隔与几何间隔
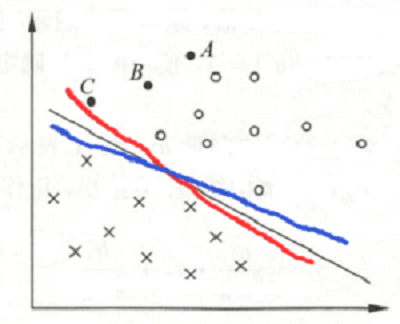
在上图中,点 A 距分离超平面较远,若预测该点为正类,就比较确信预测是正确的;点 C 距分离超平面较近,若预测该点为正类就不那么确信;点 B 介于点 A 与 C 之间,预测其为正类的确信度也在 A 与 C 之间。
一般来说,一个点距离分离超平面的远近可以表示分类预测的确信程度。在超平面 $w\cdot x+b=0$ 确定的情况下,$|w\cdot x+b|$ 能够相对地表示点 $x$ 距离超平面的远近。而 $w\cdot x+b$ 的符号与类标记 $y$ 的符号是否一致能够表示分类是否正确。所以可用 $y(w\cdot x+b)$ 来表示分类的正确性及确信度,这就是函数间隔。
下面给出函数间隔定义:
$\hat{\gamma}_{i}=y_{i}\left(w \cdot x_{i}+b\right)$
因此我们可以找到函数间隔的最小值,定义为:
$\hat{\gamma}=\underset{i=1, \cdots, N}{min}\ \ \hat{\gamma}_{i}$
由于选择超平面时只有函数间隔还不能够选出间隔最大超平面,因此对法向量 $w$ 规范化,使得 $||w||=1$,让函数间隔确定,这时确定的函数间隔就变成为几何间隔。

根据距离公式,可以计算出上图中A点到超平面的距离(几何间隔)为:
$\gamma_{i}=y_{i}\left(\frac{w}{\|w\|} \cdot x_{i}+\frac{b}{\|w\|}\right)$
下面给出几何间隔最小值定义:
$\gamma= \underset{i=1, \cdots, N}{min}\ \ \gamma_{i}$
因此根据函数间隔和几何间隔定义,两者有以下关系:
$\begin{aligned} \gamma_{i} &=\frac{\hat{\gamma}_{i}}{\|w\|} \\ \gamma &=\frac{\hat{\gamma}}{\|w\|} \end{aligned}$
如果模长为1,那么两者相等;参数成比例改变(超平面没有改变),那么函数间隔按比例改变,而几何间隔不变,也就是几何间隔是确定的值。
4.2 间隔最大化
支持向量机学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。并且对于线性可分数据集来说,几何间隔最大的分离超平面是唯一的,这个唯一的间隔最大化称为硬间隔最大化。(有很好的分类能力)
求解最大间隔分离超平面
如何求解几何间隔最大的分离超平面可以表示为下列的约束最优化问题:
$\begin{array}{ll} \underset{w, b}{max} & \gamma \\ \text { s.t. } & y_{i}\left(\frac{w}{\|w\|} \cdot x_{i}+\frac{b}{\|w\|}\right) \geqslant \gamma, \quad i=1,2, \cdots, N \end{array}$
上述解释为希望最大化训练数据集的几何间隔 $ \gamma$ ,约束条件表示为超平面关于样本点的几何间隔至少是 $ \gamma$ 。
又由于几何间隔与函数间隔的关系,可以得:
$\begin{array}{l} \underset{w, b}{max} \ \frac{\hat{\gamma}}{\|w\|} \\ \text { s.t. } \quad y_{i}\left(w \cdot x_{i}+b\right) \geqslant \hat{\gamma}, \quad i=1,2, \cdots, N \end{array}$
根据之前的理论,函数间隔的取值并不影响上面最优化问题的解,因此可以将函数间隔的值取为 1 并代入上面的最优化问题。于是可以得到下面新的最优化问题:
$\begin{aligned} \underset{w, b}{min}\ & \frac{1}{2}\|w\|^{2} \\ \text { s.t. }\ & y_{i}\left(w \cdot x_{i}+b\right)-1 \geqslant 0, \quad i=1,2, \cdots, N \end{aligned}$
注意, $max \ \ \frac{1}{||w||}$ 与 $min \ \ \frac{1}{2}||w||^2$ 是等价的,系数 1/2 和平方是为了方便后面求导和构造凸优化,不影响结果。从而将其转变为一个凸二次规划问题。
凸二次规划问题也是凸优化问题的一种形式,凸优化问题指:
$\begin{array}{ll} \underset{w}{min} & f(w) \\ \text { s.t. } & g_{i}(w) \leqslant 0, \quad i=1,2, \cdots, k \\ & h_{i}(w)=0, \quad i=1,2, \cdots, l \end{array} $
其中, 目标函数 $f(w)$ 和约束函数 $g_{i}(w)$ 都是 $\mathbf{R}^{n}$ 上的车续可微的凸函数, 约束函数 $h_{i}(w)$ 是 $\mathbf{R}^{n}$ 上的仿射函数 。然后,当目标函数是二次函数,并且约束函数 $g_i(x)$ 是仿射函数时(二阶导为0,其实也是凸函数,满足条件),上述凸优化问题就转变为凸二次规划问题。
最后求解出最优解 $w^*,b^*$,就能够得到线性可分支持向量机模型。因此,它的学习算法为最大间隔法。
由此得分离超平面:
$w^{*} \cdot x+b^{*}=0$
分类决策函数:
$f(x)=\operatorname{sign}\left(w^{*} \cdot x+b^{*}\right)$
例7.1: 已知一个如图 7.4 所示的训练数据集,其正例点 是 $ x_{1}=(3,3)^{\mathrm{T}}, \quad x_{2}=(4,3)^{\mathrm{T}} $,负例点是 $x_{3}=(1,1)^{\mathrm{T}}$,试求最大间隔分离超平面。
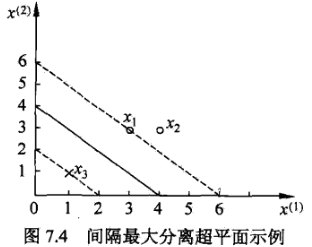
解:根据训练数据集构造约束最优化问题:
$\min _{x, b} \frac{1}{2}\left(w_{1}^{2}+w_{2}^{2}\right) $
$ 3 w_{1}+3 w_{2}+b \geqslant 1 $
$4 w_{1}+3 w_{2}+b \geqslant 1 $
$-w_{1}-w_{2}-b \geqslant 1 $
求得此最优化问题的解 $w_{1}=w_{2}=\frac{1}{2}, b=-2$ 。于是最大间隔分离超平面为
$\frac{1}{2} x^{(1)}+\frac{1}{2} x^{(2)}-2=0 $
其中, $x_{1}=(3,3)^{\mathrm{T}}$ 与 $x_{3}=(1,1)^{\mathrm{T}}$ 为支持向量。
4.3 学习的对偶算法
这样做的优点,一是对偶问题往往更容易求解;二是自然引入核函数,进而推广到非线性分类问题。对上面含有不等式约束的凸二次规划问题,可以对其使用拉格朗日乘子法得到其对偶问题。
首先对每一个不等式约束引入拉格朗日乘子 $α_i$ , $α_i \ge0,i=1,2,...N$ ,构造拉格朗日函数:
$L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2}\|\boldsymbol{w}\|^{2}-\sum \limits _{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w} \cdot \boldsymbol{x}_{i}+b\right)-1\right)$
然后展开后可以得到原问题拉格朗日函数:
$L(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum \limits _{i=1}^{N} \alpha_{i} y_{i}\left(w \cdot x_{i}+b\right)+\sum \limits_{i=1}^{N} \alpha_{i}$
原始问题的阐述:++++++++++++++++++++++++++++++++++++++++
下面展开拉格朗日对偶性的简单推导:
首先令:
$\theta(\boldsymbol{w})= \underset{\alpha_{i} \geq 0}{max} \ L(\boldsymbol{w}, b, \boldsymbol{\alpha})$
当样本点不满足约束条件时,即在可行解区域外:
$y_{i}\left(\boldsymbol{w} \cdot \boldsymbol{x}_{i}+b\right)<1$
此时,将 $α_i$ 设为无穷大,则 $θ(w)$ 也为无穷大。
此时 $θ(w)$ 为原函数本身。于是,将两种情况合并起来就可以得到我们新的目标函数:
$\theta(\boldsymbol{w})=\left\{\begin{array}{l} \frac{1}{2}\|\boldsymbol{w}\|^{2}, \boldsymbol{x} \in \text { 可行区域 } \\ +\infty \quad, \boldsymbol{x} \in \text { 不可行区域 } \end{array}\right.$
于是原约束问题就等价于:
$\underset{\boldsymbol{w}, b}{min} \ \theta(\boldsymbol{w})= \underset{\boldsymbol{w}, b}{min} \ \ \underset{\alpha_{i} \geq 0}{max} \ L(\boldsymbol{w}, b, \boldsymbol{\alpha})=p^{*}$
原始问题的阐述结束++++++++++++++++++++++++++++++++++++++++
PS:对于上述公式我们原问题是求 $\theta(\boldsymbol{w})= \underset{\alpha_{i} \geq 0}{max} \ L(\boldsymbol{w}, b, \boldsymbol{\alpha})$ ,但由于存在错误分类点(学习软间隔更能明白),导致不可避免的存在无穷大上界的情况,但我们需要得到的是$\frac{1}{2}\|\boldsymbol{w}\|^{2}$,所以取$min$。
对偶问题的阐述: ------------------------------------------------------------------------
看一下我们的新目标函数,先求最大值,再求最小值。这样的话,我们首先就要面对带有需要求解的参数 $w、b$ 的方程,而 $α_i$ 又是不等式约束,这个求解过程不好做。所以,我们需要使用拉格朗日函数对偶性(参考《机器学习——最优化问题:拉格朗日乘子法、KKT条件以及对偶问题》),将最小和最大的位置交换一下,这样就变成了:
$ \underset{\alpha_{i} \geq 0}{max} \ \underset{\boldsymbol{w}, b}{min} \ L(\boldsymbol{w}, b, \boldsymbol{\alpha})=d^{*}$
现在,要使得 $p^*=d^*$ ,需要满足两个条件:(上述参考博文等式成立的要求)
① 优化问题是凸优化问题
② 满足KKT条件
条件①因为本问题是凸优化问题可以直接满足,而要满足条件二,即要求:
$\left\{\begin{array}{l} \alpha_{i} \geq 0 \\ y_{i}\left(\boldsymbol{w}_{i} \cdot \boldsymbol{x}_{i}+b\right)-1 \geq 0 \\ \alpha_{i}\left(y_{i}\left(\boldsymbol{w}_{i} \cdot \boldsymbol{x}_{i}+b\right)-1\right)=0 \end{array}\right. $
Step1:为了得到求解对偶问题的具体形式,需要求解出 $w、b$ ,令拉格朗日函数 $L$ 分别对 $w$、$b$ 分别求偏导并令其为 $0$,从而得到极小化问题解:
$\begin{array}{lll} \frac{\partial L}{\partial b}=0 & \rightarrow & \sum \limits _{i=1}^{n} \alpha_{i} y_{i}=0 \\ \frac{\partial L}{\partial \mathbf{w}}=0 & \rightarrow & \mathbf{w}=\sum \limits_{i=1}^{n} \alpha_{i} y_{i} \mathbf{x}_{i} \end{array}$
Step2:将以上两个等式带入拉格朗日目标函数,消去 $w$ 和 $b$ ,从而得到:
$ \begin{aligned} \underset{\boldsymbol{w}, b}{min}\ L(w, b, \alpha) &=\frac{1}{2} \sum \limits _{i=1}^{N} \sum \limits_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)-\sum \limits_{i=1}^{N} \alpha_{i} y_{i}\left (\left(\sum \limits_{j=1}^{N} \alpha_{j} y_{j} x_{j}\right) \cdot x_{i}+b\right)+\sum \limits_{i=1}^{N} \alpha_{i} \\ &=-\frac{1}{2} \sum \limits_{i=1}^{N} \sum \limits_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)+\sum \limits_{i=1}^{N} \alpha_{i} \end{aligned}$
即:
$\underset{\boldsymbol{w}, b}{min}\ L(w, b, \alpha) =-\frac{1}{2} \sum \limits _{i=1}^{N} \sum \limits_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)+\sum \limits_{i=1}^{N} \alpha_{i}$
Step3:然后求上式对 $α$ 的 max,就是我们的对偶问题,并且把目标式子加一个负号,将求解极大转换为求解极小:
$\begin{array}{ll} \underset{\alpha}{min} & \frac{1}{2} \sum \limits_{i=1}^{N} \sum \limits_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)-\sum \limits_{i=1}^{N} \alpha_{i} \\ \text { s.t. } & \sum \limits_{i=1}^{N} \alpha_{i} y_{i}=0 \\ & \alpha_{i} \geqslant 0, \quad i=1,2, \cdots, N \end{array}$
Step4:最后,我们就可以求得一个 $α_j^*>0$ (w不能全为0)求得最优解 $w^*$ 和 $b^*$ :
$\begin{array}{c} w^{*}=\sum_\limits{i=1}^{N} \alpha_{i}^{*} y_{i} x_{i} \\ b^{*}=y_{j}-\sum \limits_{i=1}^{N} \alpha_{i}^{*} y_{i}(x_{i} \cdot x_{j}) \end{array}$
最后整理公式可得分离超平面:
$\sum_ \limits {i=1}^{N} \alpha_{i}^{*} y_{i}\left(x \cdot x_{i}\right)+b^{*}=0$
以及决策函数:
$f(x)=\operatorname{sign}\left(\sum \limits _{i=1}^{N} \alpha_{i}^{*} y_{i}\left(x \cdot x_{i}\right)+b^{*}\right)$
对偶问题的阐述结束 ------------------------------------------------------------------------
例 7.2 训练数据与例 7.1 相同。如图 7.4 所示,正例点是 $x_{1}=(3,3)^{\mathrm{T}}, x_{2}=(4,3)^{\mathrm{T}}$ , 负例点是 $x_{3}=(1,1)^{\mathrm{T}}$ , 试用对偶算法求线性可分支持向量机。 解 根据所给数据,对偶问题是
$\begin{array}{ll} \min _{\alpha} & \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)-\sum_{i=1}^{N} \alpha_{i} \\ & =\frac{1}{2}\left(18 \alpha_{1}^{2}+25 \alpha_{2}^{2}+2 \alpha_{3}^{2}+42 \alpha_{1} \alpha_{2}-12 \alpha_{1} \alpha_{3}-14 \alpha_{2} \alpha_{3}\right)-\alpha_{1}-\alpha_{2}-\alpha_{3} \\ \text { s.t. } \quad & \alpha_{1}+\alpha_{2}-\alpha_{3}=0 \\ & \alpha_{i} \geqslant 0, \quad i=1,2,3 \end{array}$
解这一最优化问题。 将 $ \alpha_{3}=\alpha_{1}+\alpha_{2} $ 代入目标函数并记为
$s\left(\alpha_{1}, \alpha_{2}\right)=4 \alpha_{1}^{2}+\frac{13}{2} \alpha_{2}^{2}+10 \alpha_{1} \alpha_{2}-2 \alpha_{1}-2 \alpha_{2}$
对 $\alpha_{1}, \alpha_{2}$ 求偏导数并令其为 $0$ , 易知 $s\left(\alpha_{1}, \alpha_{2}\right)$ 在点 $\left(\frac{3}{2},-1\right)^{\mathrm{T}} $ 取极值,但该点不满足 约束条件 $ \alpha_{2} \geqslant 0$ , 所以最小值应在边界上达到。
当 $\alpha_{1}=0$ 时,最小值 $s\left(0, \frac{2}{13}\right)=-\frac{2}{13}$ ; 当 $\alpha_{2}=0$ 时, 最小值 $s\left(\frac{1}{4}, 0\right)=-\frac{1}{4}$。于是 $s\left(\alpha_{1}, \alpha_{2}\right)$ 在 $ \alpha_{1}=\frac{1}{4}, \alpha_{2}=0$ 达到最小, 此时 $ \alpha_{3}=\alpha_{1}+\alpha_{2}=\frac{1}{4}$。
这样, $ \alpha_{1}^{*}=\alpha_{3}^{*}=\frac{1}{4}$ 对应的实例点 $x_{1}, x_{3}$ 是支持向量。 计算得
$\begin{array}{c} w_{1}^{*}=w_{2}^{*}=\frac{1}{2} \\ b^{*}=-2 \end{array}$
分离超平面为
$\frac{1}{2} x^{(1)}+\frac{1}{2} x^{(2)}-2=0$
分类决策函数为
$f(x)=\operatorname{sign}\left(\frac{1}{2} x^{(l)}+\frac{1}{2} x^{(2)}-2\right)$
对于线性可分问题,上述线性可分支持向量机的学习(硬间隔最大化)算法是 完美的。 但是, 训练数据集线性可分是理想的情形。 在现实问题中,训练数据集往往是线性不可分的, 即在样本中出现噪声或特异点。此时, 有更一般的学习算法。
5 软间隔最大化
有时候本来数据的确是可分的,也就是说可以用线性分类SVM的学习方法来求解,但是却因为混入了异常点,导致不能线性可分,比如下图1,本来数据是可以按下面的实线来做超平面分离的,可以由于一个橙色和一个蓝色的异常点导致我们没法按照上节线性支持向量机中的方法来分类。
另外一种情况没有这么糟糕到不可分,但是会严重影响我们模型的泛化预测效果,比如下图2,本来如果我们不考虑异常点,SVM的超平面应该是下图中的红色线所示,但是由于有一个蓝色的异常点,导致我们学习到的超平面是下图中的粗虚线所示,这样会严重影响我们的分类模型预测效果。
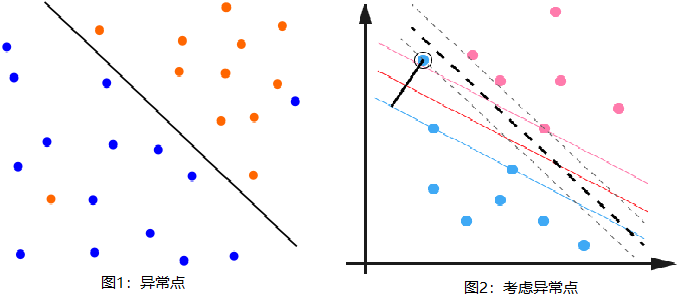
为了解决这个问题,引入了“软间隔”的概念,相比硬间隔的苛刻条件,即允许某些点不满足约束:
$y_{j}\left(\boldsymbol{w} \cdot \boldsymbol{x}_{j}+b\right) \geq 1$
于是为解决这个问题对每个样本点引入一个松弛变量,使函数间隔加上松弛变量大于等于1,约束条件变换成如下形式:
$y_{i}\left(w \cdot x_{i}+b\right) \geqslant 1-\xi_{i}$

然后我们采用合页损失函数(hinge loss function),将原优化问题改写为:
5.1 合页损失函数
为什么说线性支持向量机是采用的合页损失函数?
是由于根据上述原最优化问题等价于:
$\underset{w, b}{min}\sum \limits _ {i=1}^{N}[1-y_{i}(w \cdot x_{i}+b)]_{+}+\lambda\|w\|^{2}$
上述前一项为经验损失(合页损失函数),后一项为正则化项。
证明:首先令
$[1-y_{i}(w \cdot x_{i}+b)]_{+}=\xi_{i}$
$[z]_{+}=\{\begin{array}{ll} z, & z>0 \\ 0, & z \leqslant 0 \end{array}.$
其中,下标“+”表示函数取正值,因此松弛变量大于等于 0 。如果点被正确分类,且函数间隔大于 $1$,损失是 $0$,否则损失是 $1-y(w\cdot x +b)$。
当 $1-y_{i}(w \cdot x_{i}+b)>0 $ 时,有 $ y_{i}(w \cdot x_{i}+b)=1-\xi_{i}$ ;当 $1-y_{i}(w \cdot x_{i}+b) \leqslant 0$时,$\xi_{i}=0 $,有 $ y_{i}(w \cdot x_{i}+b) \geqslant 1-\xi_{i} $ 。 于是 $w, b, \xi_{i} $ 满足合页损失的约束条件。所以最优化问题可写成
$\underset{w, b}{min}\sum \limits _{i=1}^{N} \xi_{i}+\lambda\|w\|^{2}$
若取 $\lambda=\frac{1}{2 C}$ , 则
$\underset{w, b}{min}\ \ \frac{1}{C}\left(\frac{1}{2}\|w\|^{2}+C \sum \limits_{i=1}^{N} \xi_{i}\right)$

5.2 学习的对偶形式
带松他变量的优化问题:
$\begin{array}{c} \underset{\mathbf{w}, b, \xi \geq 0}{min}\ \ \frac{1}{2} \mathbf{w}^{\top} \mathbf{w}+C \sum_{i} \xi_{i} \\ \text { s.t. } y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right) \geq 1-\xi_{i}, \quad i=1, \ldots, n \\ \xi_{i} \geq 0 \end{array}$
将原优化问题, 利用拉格朗日算子, 转换为新的优化问题:
$L(\mathbf{w}, b, \xi, \alpha, \lambda)=\frac{1}{2} \mathbf{w}^{\top} \mathbf{w}+C \sum \limits_{i} \xi_{i}+\sum \limits_{i} \alpha_{i}\left(1-\xi_{i}-y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{i}+b\right)\right)-\sum \limits_{i} \lambda_{i} \xi_{i}$
$ \begin{array}{lll} \frac{\partial L}{\partial b}=0 & \rightarrow & \sum \limits _{i} \alpha_{i} y_{i}=0 \\ \frac{\partial L}{\partial \mathbf{w}}=0 & \rightarrow & \mathbf{w}=\sum \limits_{i} \alpha_{i} y_{i} \mathbf{x}_{i} \\ \frac{\partial L}{\partial \xi_{i}}=0 & \rightarrow & C-\alpha_{i}-\lambda_{i}=0 \end{array}$
将下式代入:
$\mathbf{w}=\sum \limits _{i} \alpha_{i} y_{i} \mathbf{x}_{i} \quad \sum \limits _{i} \alpha_{i} y_{i}=0$
则有:
$L(\xi, \alpha, \lambda)=\sum \limits _{i} \alpha_{i}-\frac{1}{2} \sum \limits _{i, j} \alpha_{i} \alpha_{j} y_{i} y_{j} \mathbf{x}_{i}^{\top} \mathbf{x}_{j}+\sum \limits _{i} \xi_{i}\left(C-\alpha_{i}-\lambda_{i}\right)$
再代入:
$C-\alpha_{i}-\lambda_{i}=0$
有:
$L(\xi, \alpha, \lambda)=\sum \limits _{i} \alpha_{i}-\frac{1}{2} \sum \limits _{i, j} \alpha_{i} \alpha_{j} y_{i} y_{j} \mathbf{x}_{i}^{\top} \mathbf{x}_{j}$
Dual对偶形式为:
$\begin{aligned} \underset{\alpha}{max} \ & W(\alpha)=\sum \limits _{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum \limits _{i, j=1}^{n} y^{(i)} y^{(j)} \alpha_{i} \alpha_{j}\left\langle x^{(i)}, x^{(j)}\right\rangle \\ \text { s.t. } & 0 \leq \alpha_{i} \leq C, \quad i=1, \ldots, n \\ & \sum \limits _{i=1}^{n} \alpha_{i} y^{(i)}=0, \end{aligned}$
KKT dual-complementarity 条件
$\begin{aligned} \alpha_{i}=0 & \Rightarrow y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1 \\ \alpha_{i}=C & \Rightarrow y^{(i)}\left(w^{T} x^{(i)}+b\right) \leq 1 \\ 0<\alpha_{i}<C & \Rightarrow y^{(i)}\left(w^{T} x^{(i)}+b\right)=1 \end{aligned}$
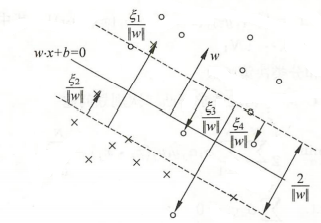
5.3 支持向量
在线性支持向量机中,它的支持向量有点不同,还是 $α_i^* >0$ 的为支持向量(软间隔的支持向量),可以在间隔边界上,也可以在边界之间,这里只需要注意约束条件便能正确判断。
6 非线性支持向量机——核技巧
对解线性分类问题,线性分类支持向量机是一种非常有效的方法。但是,有时分类问题是非线性的,这时可以使用非线性支持向量机。本节叙述非线性支持向量机,其主要特点是利用核技巧(kernel trick)。为此,先要介绍核技巧。核技巧不仅应用于支持向量机,而且应用于其他统计学习问题。
6.1 非线性分类问题
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题。比如:
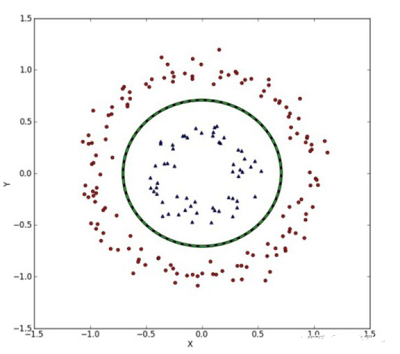
能在 $n$ 维欧式空间中找到这样的超曲面进行正确的分类,则称为非线性可分问题。
这种情况的解决方法就是:将二维线性不可分样本映射到高维空间中,让样本点在高维空间线性可分,比如:
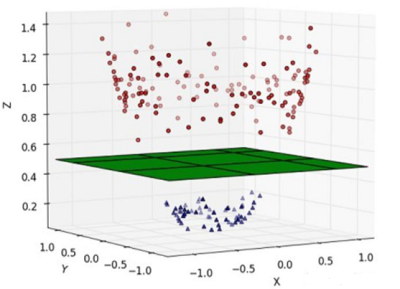
6.2 核函数
定义 7.6 (核函数) 设 $\mathcal{X}$ 是输入空间 (欧氏空间 $\mathbf{R}^{n}$ 的子集或离散集合 ),又设 $\mathcal{H}$ 为特征空间 (希尔伯特空间 ),如果存在一个从 $\mathcal{X}$ 到 $\mathcal{H}$ 的映射$\phi(x): \mathcal{X} \rightarrow \mathcal{H}$
使得对所有 $x, z \in \mathcal{X}$ , 函数 $K(x, z) $ 满足条件
$K(x, z)=\phi(x) \cdot \phi(z)$
则称 $K(x, z)$ 为核函数, $\phi(x)$ 为映射函数,式中 $\phi(x) \cdot \phi(z)$ 为 $ \phi(x)$ 和 $\phi(z)$ 的内积。
希尔伯特空间:欧几里德空间的一个推广,其不再局限于有限维的情形,是一个完备化的内积空间。
核技巧的思想:只定义核函数 $K(x,z)$ ,而不显式定义映射函数 $φ$ ,因为一般直接计算核函数会比较容易。另外,同一核函数在同一特征空间的映射函数可以不同。
6.3 核技巧在支持向量机中的应用
在线性支持向量机学习的对偶问题中,用核函数替代内积,求解得到的就是非线性支持向量机,对偶形式如下
$W(\alpha)=\frac{1}{2} \sum \limits _{i=1}^{N} \sum \limits_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} K\left(x_{i}, x_{j}\right)-\sum \limits_{i=1}^{N} \alpha_{i}$
其分类决策函数为:
$\begin{aligned} f(x) &=\operatorname{sign}\left(\sum \limits _{i=1}^{N_{s}} a_{i}^{*} y_{i} \phi\left(x_{i}\right) \cdot \phi(x)+b^{*}\right) \\ &=\operatorname{sign}\left(\sum \limits _{i=1}^{N_{s}} a_{i}^{*} y_{i} K\left(x_{i}, x\right)+b^{*}\right) \end{aligned}$
在实际应用中,核函数的选择的有效性需要通过实验验证。
6.4 核函数的作用
我们不禁有个疑问:只是做个内积运算,为什么要有核函数的呢?
这是因为低维空间映射到高维空间后维庄可能会很大,如果将全部样本的点乘全部计算好, 这样的 计算量太大了。
但如果我们有这样的一核函数 $ k(x, y)=(\phi(x), \phi(y)), \quad x_{i}$ 与 $ x_{j}$ 在特征空间的内积等于 它们在原始样本空间中通过函数 $ k(x, y)$ 计算的结果,我们就不需要计算高维甚至无穷维空间的内积了。
举个例子:假设我们有一个多项式核函数:
$k(x, y)=(x \cdot y+1)^{2} $
带进样本点的后:
$k(x, y)=\left(\sum \limits _{i=1}^{n}\left(x_{i} \cdot y_{i}\right)+1\right)^{2}$
而它的展开项是:
$\sum \limits _{i=1}^{n} x_{i}^{2} y_{i}^{2}+\sum \limits_{i=2}^{n} \sum \limits_{j=1}^{i-1}\left(\sqrt{2} x_{i} x_{j}\right)\left(\sqrt{2} y_{i} y_{j}\right)+\sum \limits_{i=1} n\left(\sqrt{2} x_{i}\right)\left(\sqrt{2} y_{i}\right)+1$
如果没有核函数,我们则需要把向量映射成:
$x^{\prime}=\left(x_{1}^{2}, \ldots, x_{n}^{2}, \ldots \sqrt{2} x_{1}, \ldots, \sqrt{2} x_{n}, 1\right)$
然后在进行内积计算,才能与多项式核函数达到相同的效果。
可见核函数的引入一方面减少了我们计算量,另一方面也减少了我们存储数据的内存使用量。
6.5 正定核
那么如何不用构造映射函数就能够判断一个函数是否是核函数呢?
核函数需要是正定核,通常所说的核函数都是正定核。
下面介绍正定核的充要条件:
定理 $\mathbf{7 . 5}$ (正定核的充要条件) 设 $ K: \mathcal{X} \times \mathcal{X} \rightarrow \mathbf{R}$ 是对称函数,则 $ K(x, z) $ 为正定核函数的充要条件是对任意 $x_{i} \in \mathcal{X}, i=1,2, \cdots, m, K(x, z) $ 对应的 $ Gram$ 矩阵:
$K=\left[K\left(x_{i}, x_{j}\right)\right]_{m \times m}$
是半正定矩阵。
那么什么是半正定矩阵?任取一个 N 维的列向量 $\alpha$ ,如果满足:
$\alpha^{T} K \alpha \geq 0$
就说明K是一个半正定矩阵。
6.6 常用的核函数
$\begin{array}{lll} \hline \text { 名称 } & \text { 表达式 } & \text { 参数 } \\ \hline \text { 线性核 } & \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j} & \\ \text { 多项式核 } & \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left(\boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}\right)^{d} & d \geqslant 1 \text { 为多项式的次数 } \\ \text { 高斯核 } & \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\exp \left(-\frac{\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|^{2}}{2 \sigma^{2}}\right) & \sigma>0 \text { 为高斯核的带宽(width) } \\ \text { 拉普拉斯核 } & \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\exp \left(-\frac{\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|}{\sigma}\right) & \sigma>0 \\ \text { Sigmoid 核 } & \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\tanh \left(\beta \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}+\theta\right) & \tanh \text { 为双曲 } \text { 正切函数, } \beta>0, \theta<0 \\ \hline \end{array}$
如果 Feature 的数量很大,跟样本数量差不多,这时候选用 LR 或者是 Linear Kernel 的 SVM
如果 Feature 的数量比较小,样本数量一般, 不算大也不算小,选用 SVM+Gaussian Kernel
如果 Feature 的数量比较小,而样本数量很多,需要手工添加一些 feature 变成第一种情况
参考
文献:
视频:
机器学习——支持向量机SVM的更多相关文章
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析
SVM有很多实现,现在只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使用一种核函数(kernel)的方式将SVM ...
- coursera机器学习-支持向量机SVM
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 机器学习-支持向量机SVM
简介: 支持向量机(SVM)是一种二分类的监督学习模型,他的基本模型是定义在特征空间上的间隔最大的线性模型.他与感知机的区别是,感知机只要找到可以将数据正确划分的超平面即可,而SVM需要找到间隔最大的 ...
- 机器学习——支持向量机(SVM)
支持向量机原理 支持向量机要解决的问题其实就是寻求最优分类边界.且最大化支持向量间距,用直线或者平面,分隔分隔超平面. 基于核函数的升维变换 通过名为核函数的特征变换,增加新的特征,使得低维度空间中的 ...
- 机器学习支持向量机SVM笔记
SVM简述: SVM是一个线性二类分类器,当然通过选取特定的核函数也可也建立一个非线性支持向量机.SVM也可以做一些回归任务,但是它预测的时效性不是太长,他通过训练只能预测比较近的数据变化,至于再往后 ...
- 机器学习——支持向量机(SVM)之核函数(kernel)
对于线性不可分的数据集,可以利用核函数(kernel)将数据转换成易于分类器理解的形式. 如下图,如果在x轴和y轴构成的坐标系中插入直线进行分类的话, 不能得到理想的结果,或许我们可以对圆中的数据进行 ...
- 机器学习——支持向量机(SVM)之Platt SMO算法
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替: 一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描. 所谓 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
随机推荐
- 通信协议,TCP/UDP对比:
通信协议 协议:约定,比如在中国约定说普通话 网络通信协议:速率,传输码率,代码结构,传输控制... 问题:非常复杂 大事化小:分层 TCP/IP协议簇:实际上是一组协议 重要: TCP:用户传输协议 ...
- [08 Go语言基础-for循环]
[08 Go语言基础-for循环] 循环 循环语句是用来重复执行某一段代码. for 是 Go 语言唯一的循环语句.Go 语言中并没有其他语言比如 C 语言中的 while 和 do while 循环 ...
- 【监控】Zabbix安装
目录 一.监控目的 二.监控方式 三.主流监控系统 四.Zabbix介绍 五.Zabbix服务端安装 5.1 环境介绍 5.2 准备系统环境 5.3 安装Nginx(源码编译安装) 5.3.1 配置N ...
- Spring系列之HikariCP连接池
上两篇文章,我们讲到了Spring中如何配置单数据源和多数据源,配置数据源的时候,连接池有很多选择,在SpringBoot 1.0中使用的是Tomcat的DataSource,在SpringBoot ...
- 数据结构与算法-排序(十)桶排序(Bucket Sort)
摘要 桶排序和基数排序类似,相当于基数排序的另外一种逻辑.它是将取值范围当做创建桶的数量,桶的长度就是序列的大小.通过处理比较元素的数值,把元素放在桶的特定位置,然后遍历桶,就可以得到有序的序列. 逻 ...
- asp.net MVC 数据的验证
join 操作
- web.xml中自定义Listener
Listener可以监听容器中某一执行动作,并根据其要求做出相应的响应. 常用的Web事件的监听接口如下: ServletContextListener:用于监听Web的启动及关闭 ServletCo ...
- Go与接口:实现接口的条件
接口类型变量 Go是强类型语言,你不能将整数值赋值给浮点型变量.同样,也不能将没有实现接口的类型值赋值给接口类型变量. // 1.定义变量是接口类型 var w io.Writer // 2.将具体类 ...
- 战胜了所有对手,却输给了时代。MVVM--jQuery永远的痛。
前言 第二次浏览器战争中,随着以 Firefox 和 Opera 为首的 W3C 阵营与 IE 对抗程度的加剧,浏览器碎片化问题越来越严重,不同的浏览器执行不同的标准,对于开发人员来说这是一个恶梦.为 ...
- Golang slice作为函数参数
slice底层其实是一个结构体,len.cap.array分别表示长度.容量.底层数组的地址,当slice作为函数的参数传递的时候,跟普通结构体的传递是没有区别的:如果直接传slice,实参slice ...