大数据学习(02)——HDFS入门
Hadoop模块
提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块。

Common是基础模块,这个是必须用的。剩下常用的就是HDFS和YARN。
MapReduce现在用的比较少了,多数场景下会被Spark取代。
Ozone是一个新组件,对象存储,可以看做是HDFS的升级版。
HDFS组成
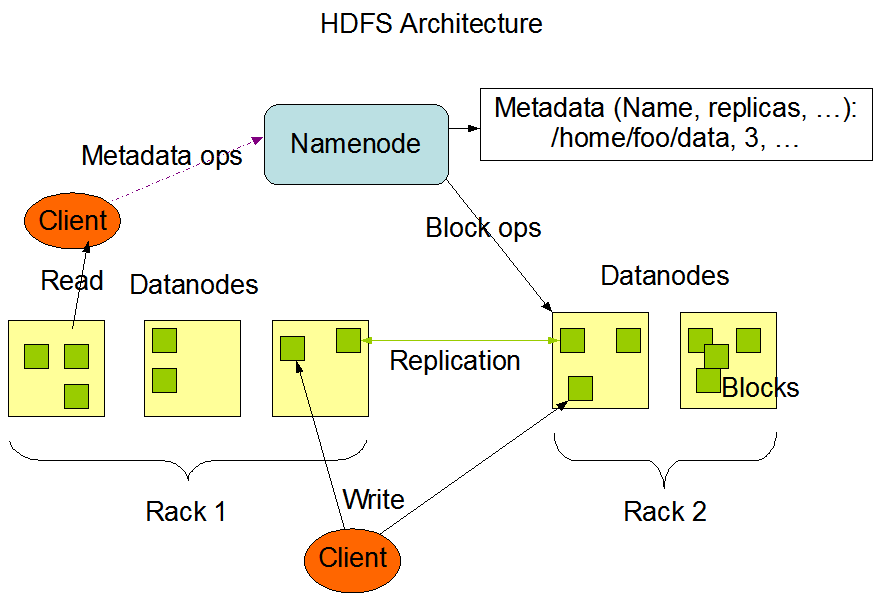
作为Hadoop的分布式文件系统,它的思想远比这个产品本身更重要。它主要包含这么几个组成部分:
- NameNode,主节点,用来保存元数据信息,包括文件属性、文件切成多少个Block、每个Block在哪个DataNode上等等
- DataNode,存储文件的Block
- SecondaryNameNode,为NameNode做记录合并工作,减少NameNode重启加载时间
这个文件系统的命令跟Linux的文件系统命令很相似,只不过前面要加上hdfs dfs前缀。
DataNode
当一个文件上传到HDFS时,根据配置文件里的块大小,它会被切成多个大小相同的Block(最后一块大小是实际值),分散存放在多个DataNode上。
每一个Block根据配置文件里的副本数设置,多个副本也会放在不同的DataNode上。这里有一个概念叫做Block放置策略,它是由NameNode来确定的。
Block多个副本在DataNode之间复制传输的时候,又被切成更小的单元,其中包含数据和校验和。切成小单元的目的,是为了提高Block复制的并发度,让它成为一个流水线作业,减少总体网络传输时间。
如果某一个副本在复制的时候出现问题,这个操作不会由客户端来重试,而是NameNode在检查副本数不足时,自动复制缺少的副本。
NameNode
存放元数据信息:一部分来源于客户端的目录增删、文件上传等操作,另一部分来源于DataNode存放文件Block之后的反馈信息。
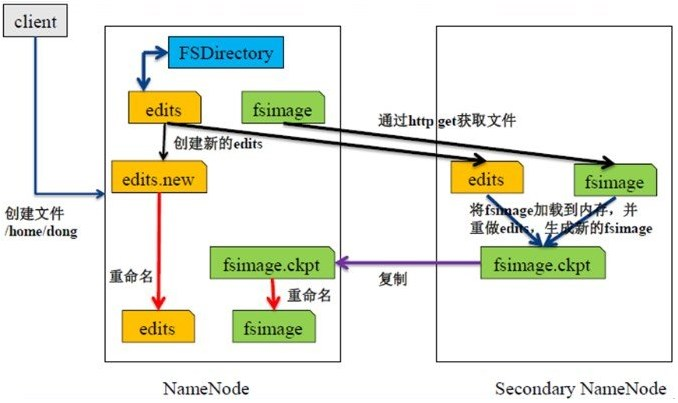
它使用FsImage保存某个时点全量的元数据信息,使用EditLog来记录实时变化的元数据信息,两个文件加起来构成了当前的全量信息。
Block放置策略:如果上传文件的节点是DataNode并且副本数为3,那么Block第一个副本放在该DataNode上,第二个副本放在其他机柜的DataNode上(与第一个节点不在同一个交换机),第三个副本放在与第二个副本相同机柜的DataNode上(同一个交换机网络开销小)
NameNode重启时,它会加载最新的FsImage,并把之后的EditLog重新执行一次,再把内存里恢复的元数据写一个新的FsImage。
SecondaryNameNode
它不是NameNode的备份。
它的工作是从NameNode上拉取FsImage和EditLog,并把两者合并后的新的FsImage推给NameNode。
在两种情况下会触发这个工作:
- 到达固定的时间间隔(比如一个小时)
- EditLog文件大小达到一个值(比如64M)
为什么有HDFS
在HDFS出现之前,已经有那么多分布式文件系统了,为什么还要再造一个轮子呢?
确切地说,HDFS不是一个完整的文件系统,它的出现是为了更好地执行分布式计算,这是以前的文件系统不具备的特性。
为了达到这个目的,HDFS不支持文件的修改。因为一旦某个Block被修改了,它的大小就会发生变化。为了保持每个Block大小一致,必然会引起其后所有Block的重新切分和移动,IO成本太高。
当然,它也可以只修改元素据里Block的偏移量,但这样会导致修改多次之后,Block的大小差异太大,不利于计算任务的平均分配。
大数据学习(02)——HDFS入门的更多相关文章
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- leetcode1141 N*3矩阵。阿里笔试no.1
你有一个 n x 3 的网格图 grid ,你需要用 红,黄,绿 三种颜色之一给每一个格子上色,且确保相邻格子颜色不同(也就是有相同水平边或者垂直边的格子颜色不同). 给你网格图的行数 n . 请你返 ...
- 实现SLIC算法生成像素画
前言 像素风最早出现在8bit的电子游戏中,受制于电脑内存大小以及显示色彩单一, 只能使用少量像素来呈现内容,却成就了不少经典的像素游戏.随着内存容量与屏幕分辨率的提升,内存与显示媒介的限制不再是问题 ...
- [翻译]在GC上加入DPAD
本文90%通过机器翻译,另外10%译者按照自己的理解进行翻译,和原文相比有所删减,可能与原文并不是一一对应,但是意思基本一致. 译者水平有限,如果错漏欢迎批评指正 译者@Bing Translator ...
- webapi发布在iis之后报错Http 403.14 error
服务器是 Windows Server 2008 R2 Enterprise 网上找了很多说是修改webconfig.试过之后没有效果,另外报错了. 最后才找到是因为webapi发布时选择的应用程序的 ...
- jenkins+nexus上传插件发布制品到nexus
nexus安装 nexus安装参考:https://www.cnblogs.com/afei654138148/p/14974124.html nexus配置 创建制品库 制品库URL:http:// ...
- 【IllegalArgumentException】: object is not an instance of declaring class
java.lang.IllegalArgumentException: object is not an instance of declaring class 日前在调试动态代理的例子中,出现以上报 ...
- SpringMVC(6)数据验证
在系列SpringMVC(4)数据绑定-1.SpringMVC(5)数据绑定-2中我们展示了如何绑定数据,绑定完数据之后如何确保我们得到的数据的正确性?这就是我们本篇要说的内容 -> 数据验证. ...
- Log4cpp配置文件及动态调整日志级别的方法
一.log4cpp概述 Log4cpp是一个开源的C++类库,它提供了C++程序中使用日志和跟踪调试的功能,它的优点如下: 提供应用程序运行上下文,方便跟踪调试: 可扩展的.多种方式记录日志,包括命令 ...
- python使用笔记23--面向对象编程
1.面向对象编程概念 面向对象是包含面向过程 面向过程编程 买车: 1.4s看车,买车 2.上保险 保险公司 3.交税 地税局 4.交管所 上牌 面向对象编程 卖车处: 1.4s 2.保险 3.交税 ...
- 双线性插值算法的FPGA实现
本设计预实现720P到1080P的图像放大,输入是YUV444数据,分量像素位宽为10bit,采用的算法为双线性插值法,开发平台是xiinx K7开发板. 双线性插值法即双次线性插值,首先在横向线性插 ...