大数据学习(02)——HDFS入门
Hadoop模块
提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块。

Common是基础模块,这个是必须用的。剩下常用的就是HDFS和YARN。
MapReduce现在用的比较少了,多数场景下会被Spark取代。
Ozone是一个新组件,对象存储,可以看做是HDFS的升级版。
HDFS组成
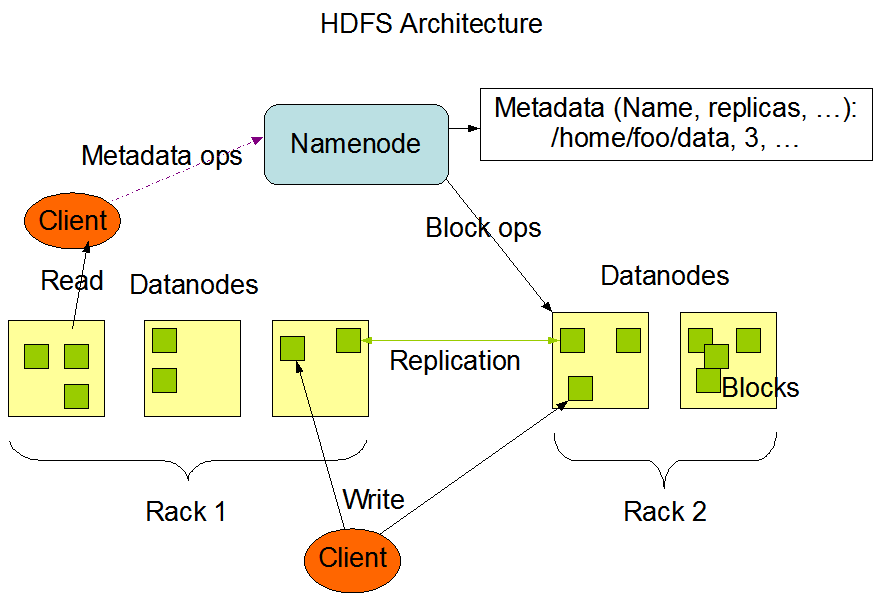
作为Hadoop的分布式文件系统,它的思想远比这个产品本身更重要。它主要包含这么几个组成部分:
- NameNode,主节点,用来保存元数据信息,包括文件属性、文件切成多少个Block、每个Block在哪个DataNode上等等
- DataNode,存储文件的Block
- SecondaryNameNode,为NameNode做记录合并工作,减少NameNode重启加载时间
这个文件系统的命令跟Linux的文件系统命令很相似,只不过前面要加上hdfs dfs前缀。
DataNode
当一个文件上传到HDFS时,根据配置文件里的块大小,它会被切成多个大小相同的Block(最后一块大小是实际值),分散存放在多个DataNode上。
每一个Block根据配置文件里的副本数设置,多个副本也会放在不同的DataNode上。这里有一个概念叫做Block放置策略,它是由NameNode来确定的。
Block多个副本在DataNode之间复制传输的时候,又被切成更小的单元,其中包含数据和校验和。切成小单元的目的,是为了提高Block复制的并发度,让它成为一个流水线作业,减少总体网络传输时间。
如果某一个副本在复制的时候出现问题,这个操作不会由客户端来重试,而是NameNode在检查副本数不足时,自动复制缺少的副本。
NameNode
存放元数据信息:一部分来源于客户端的目录增删、文件上传等操作,另一部分来源于DataNode存放文件Block之后的反馈信息。
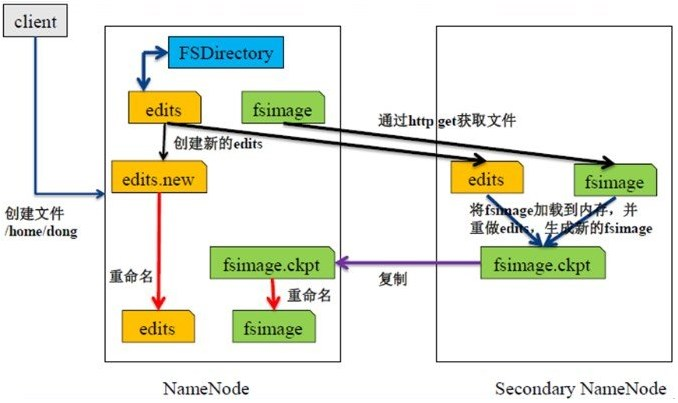
它使用FsImage保存某个时点全量的元数据信息,使用EditLog来记录实时变化的元数据信息,两个文件加起来构成了当前的全量信息。
Block放置策略:如果上传文件的节点是DataNode并且副本数为3,那么Block第一个副本放在该DataNode上,第二个副本放在其他机柜的DataNode上(与第一个节点不在同一个交换机),第三个副本放在与第二个副本相同机柜的DataNode上(同一个交换机网络开销小)
NameNode重启时,它会加载最新的FsImage,并把之后的EditLog重新执行一次,再把内存里恢复的元数据写一个新的FsImage。
SecondaryNameNode
它不是NameNode的备份。
它的工作是从NameNode上拉取FsImage和EditLog,并把两者合并后的新的FsImage推给NameNode。
在两种情况下会触发这个工作:
- 到达固定的时间间隔(比如一个小时)
- EditLog文件大小达到一个值(比如64M)
为什么有HDFS
在HDFS出现之前,已经有那么多分布式文件系统了,为什么还要再造一个轮子呢?
确切地说,HDFS不是一个完整的文件系统,它的出现是为了更好地执行分布式计算,这是以前的文件系统不具备的特性。
为了达到这个目的,HDFS不支持文件的修改。因为一旦某个Block被修改了,它的大小就会发生变化。为了保持每个Block大小一致,必然会引起其后所有Block的重新切分和移动,IO成本太高。
当然,它也可以只修改元素据里Block的偏移量,但这样会导致修改多次之后,Block的大小差异太大,不利于计算任务的平均分配。
大数据学习(02)——HDFS入门的更多相关文章
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- 08-ADMM算法
08-ADMM算法 目录 一.ADMM 算法动机 二.对偶问题 三.对偶上升法 四.对偶分割 五.乘子法(增广拉格朗日函数) 5.1 步长为 $\rho$ 的好处 六.ADMM算法 6.1 ADMM ...
- Mysql8关于hashjoin的代码处理方式
Mysql8关于hashjoin的代码处理方式 目录 Mysql8关于hashjoin的代码处理方式 1 表的Schema如下所示: 2 HashJoin代码实现 3 总结 1 表的Schema如下所 ...
- 老板防止我上班摸鱼,给我装了个chrome插件
<铁柱幻想的摸鱼生活> 9:30:到达公司,开开电脑,收拾一下办公桌 9:40:吃个早餐,接杯水(一定要多喝水,一个肾结石同事的出院后的衷心建议) 10:00:打开"技术网站&q ...
- C++中封装和继承的访问权限
众所周知,C++面向对象的三大特性为:封装,继承和多态.下面我们就先对封装做一些简单的了解.封装是通过C++中的类来完成的,类是一种将抽象转换为用户定义类型的工具.类的定义如下: class circ ...
- jenkins+nexus上传插件发布制品到nexus
nexus安装 nexus安装参考:https://www.cnblogs.com/afei654138148/p/14974124.html nexus配置 创建制品库 制品库URL:http:// ...
- 第11章:Pod数据持久化
参考文档:https://kubernetes.io/docs/concepts/storage/volumes/ Kubernetes中的Volume提供了在容器中挂载外部存储的能力 Pod需要设置 ...
- C++ nullptr 和 NULL 的使用区别
1. 为什么会有nullptr的出现 目的:nullptr的出现主要是为了替代NULL. 那么,为什么要替代NULL呢? 在NULL的定义中存在会有2种方式,有的编译器会将NULL定义成0,有的编译器 ...
- sonarqube 8.9版本配置项目访问权限
soanrqube设置项目权限 admin->项目->要设置的项目 进行项目权限配置 选择权限 权限配置(公开,私有)如果是公司项目建议选择私有 根据项目团队成员的角色需求,进行勾选配置 ...
- acwing 4 多重背包问题 I
多重背包 有 n种物品 一共有 m大小的背包,每种物品的价值 大小 个数 为 s[i],v[i],num[i]; #include<bits/stdc++.h>//cmhao #defin ...
- Maven中dependencies和dependencyManagement的区别
Maven项目中,为了保持引用依赖的一致性,一般会抽出一个parent层,用来管理子项目的maven依赖,对于依赖的管理有两种方式,分别是dependencies以及dependencyManagem ...